标签:des style blog http io color os ar 使用
前言
本文介绍如何在Ubuntu Kylin操作系统上搭建Hadoop平台。
配置
1. 操作系统: Ubuntu Kylin 14.04
2. 编程语言支持: JDK 1.8
3. 通信协议支持: SSH
2. 云计算项目: Hadoop 1.2.1
第一步:安装最新版本的JDK (若已经安装过请忽略这一步)
1. 去官网下载JDK1.8并解压 (当前安装包为:jdk-8u25-linux-x64.gz)
2. 将解压后的安装包复制到 /usr/lib/jvm 目录下 (jvm目录需要自行创建)
3. 以管理员方式打开 /etc/profile 文件并在文件底部添加以下代码:
1 #set Java Environment 2 export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_25 3 export CLASSPATH=".:$JAVA_HOME/lib:$CLASSPATH" 4 export PATH="$JAVA_HOME/bin:$PATH"
4. 执行以下命令使配置文件立即生效:
1 source /etc/profile
5. 执行以下命令验证JDK是否安装成功:
1 java -version
若显示以下信息表示安装完成:

第二步:配置SSH免密码登陆
1. 输入以下命令安装SSH
1 sudo app-get install ssh
2. 检查用户目录下是不是有个.ssh的隐藏文件夹,没有的话就自己创建一个。
3. 执行以下命令配置SSH无密码登陆 (这几行代码的功能请参考SSH使用文档):
1 ssh-keygen -t dsa -P ‘‘ -f ~/.ssh/id_dsa 2 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
4. 执行以下命令验证SSH是否安装配置成功:
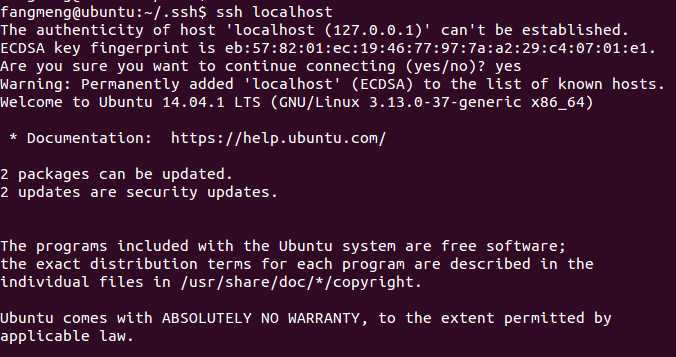
1 ssh localhost
出现提示输入yes,若终端显示以下信息,表示SSH配置成功:
第三步:安装并运行Hadoop
说明:Hadoop有三种运行方式 - 单机模式,伪分布式和完全分布式。其中,前两者主要用于程序的测试和调试,这里要讲的是伪分布式的配置,配置完全分布式的方法将在以后讲解。
1. 下载并解压最新版本的Hadoop到当前目录下 (当前安装包为:hadoop-1.2.1.tar.gz)
2. 进入conf子目录中,修改如下配置文件:
a. hadoop-env.sh
在末尾设置JAVA路径:
1 export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_25
b. core-site.xml
配置为:
1 <?xml version="1.0"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 4 <!-- Put site-specific property overrides in this file. --> 5 6 <configuration> 7 <property> 8 <name>fs.default.name</name> 9 <value>hdfs://localhost:9000</value> 10 </property> 11 </configuration>
c. hdfs-site.xml
配置为:
1 <?xml version="1.0"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 4 <!-- Put site-specific property overrides in this file. --> 5 6 <configuration> 7 <property> 8 <name>dfs.replication</name> 9 <value>1</value> 10 </property> 11 </configuration>
d. mapred-site.xml
配置为:
1 <?xml version="1.0"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 4 <!-- Put site-specific property overrides in this file. --> 5 6 <configuration> 7 <property> 8 <name>mapred.job.tracker</name> 9 <value>localhost:9001</value> 10 </property> 11 </configuration>
3. 进入Hadoop文件夹执行以下命令以格式化Hadoop文件系统HDFS:
1 bin/hadoop namenode -format
4. 执行以下命令以启动所有Hadoop进程:
1 bin/start-all.sh
5. 验证Hadoop是否安装成功
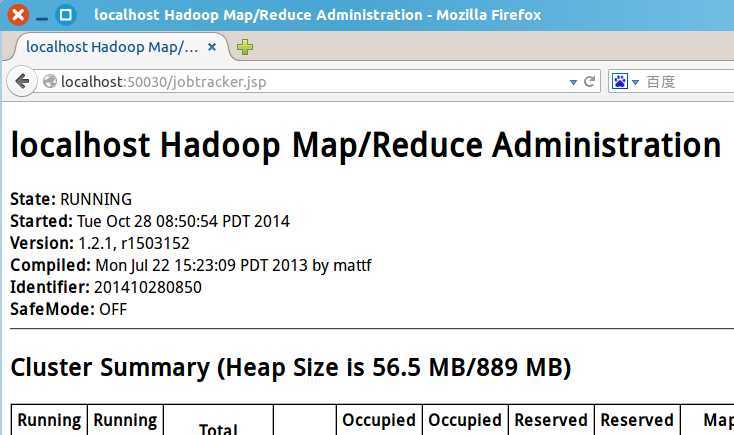
a. 打开浏览器,输入网址 http://localhost:50030 以查看MapReduce的Web页面:
b. 打开浏览器,输入网址 http://localhost:50070 以查看HDFS的Web页面:
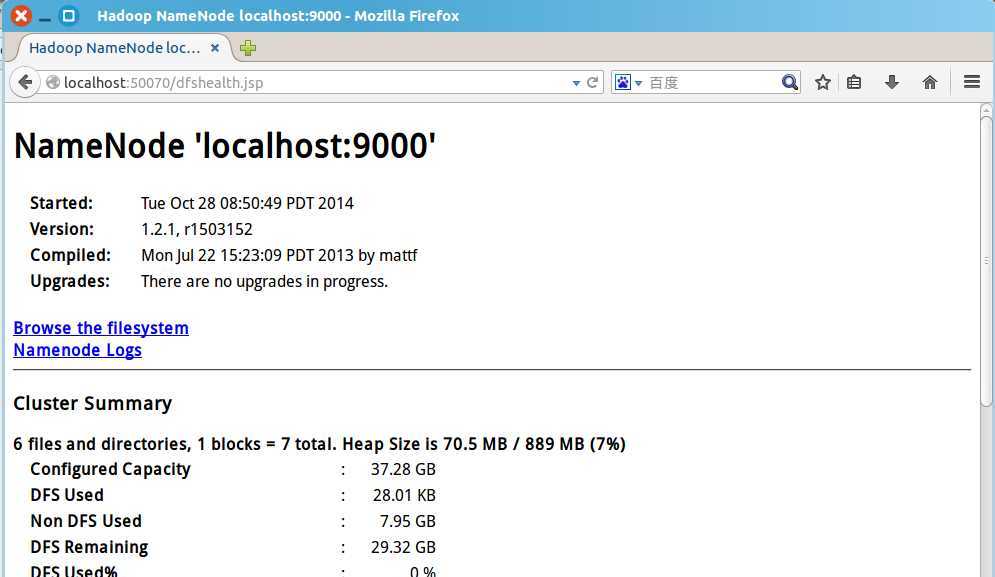
如果显示正常,那么Hadoop环境便搭建好了。
小结
1. 伪分布式的架构,机制和真实分布式其实是一样的,不过伪分布式中,Master和Slave都是一台机器。
2. 关于真实分布式环境的搭建,将在以后介绍。到时会在虚拟机上组建一个虚拟网络,跑真正的分布式程序。
标签:des style blog http io color os ar 使用
原文地址:http://www.cnblogs.com/scut-fm/p/4043846.html