标签:jason 模式 地址 from 结束 pre 数据不一致 删库 流程
目录
描述事物的符号记录称为数据,描述事物的符号既可以是数字,也可以是文字、图片,图像、声音、语言等,数据由多种表现形式,它们都可以经过数字化后存入计算机
在计算机中描述一个事物,就需要抽取这一事物的典型特征,组成一条记录,就相当于文件里的一行内容,如:
1,zhang,不详,18,2001,wan,swimming单纯的一条记录并没有任何意义,如果我们按逗号作为分隔,依次定义各个字段的意思,相当于定义表的标题
id,name,height,age,birth,birth_addr,hobby # 字段/列名
1, zhang,不详, 18, 2001, wan, swimming #数据这样我,们就可以了解到zhang,身高不详,年龄18,出生于2001年,住在安徽,爱好是游泳
数据库即存放数据的仓库,只不过这个仓库是在计算机存储设备上,而且数据是按一定的格式存放的
过去人们将数据存放在文件柜里,现在数据量庞大,已经不再适用
数据库是长期存放在计算机内、有组织、可共享的数据集合。
数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种 用户共享
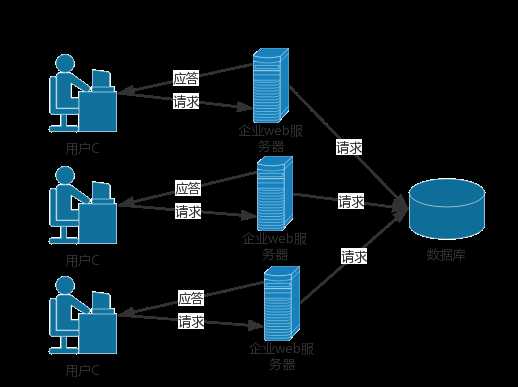
第一,将文件和程序存在一台机器上是很不合理的。
第二,操作文件是一件很麻烦的事数据库的优势
1.程序稳定性 :这样任意一台服务所在的机器崩溃了都不会影响数据和另外的服务。
2.数据一致性 :所有的数据都存储在一起,所有的程序操作的数据都是统一的,就不会出现数据不一致的现象
3.并发 :数据库可以良好的支持并发,所有的程序操作数据库都是通过网络,而数据库本身支持并发的网络操作,不需要我们自己写socket
4.效率 :使用数据库对数据进行增删改查的效率要高出我们自己处理文件很多可以理解为 数据库 是一个可以在一台机器上独立工作的,并且可以给我们提供高效、便捷的方式对数据进行增删改查的一种工具。
如此就帮助我们解决了上面出现的问题,如果将所有的数据都存储在一个独立的机器上,而对用户提供服务的机器只是存放你写的代码。
? 
如何科学地组织和存储数据,如何高效获取和维护数据成了关键,这就用到了一个系统软件---数据库管理系统。
如MySQL、Oracle、SQLite、Access、MS SQL Server
mysql主要用于大型门户,例如搜狗、新浪等,它主要的优势就是开放源代码,因为开放源代码这个数据库是免费的,他现在是甲骨文公司的产品。
oracle主要用于银行、铁路、飞机场等。该数据库功能强大,软件费用高。也是甲骨文公司的产品。
sql server是微软公司的产品,主要应用于大中型企业,如联想、方正等。
数据库管理员 DBA(Database Administrator)
管理数据的工具有很多种,不止mysql一个。
最常使用的分类还是根据他们存取数据的特点来划分的,主要分为关系型和非关系型。
关系型数据库:数据与数据之间可以有关联合限制的,关系型数据库通常都是表结构,也意味着在使用关系型数据库的时候,要先确定表结构。
例如:MYSQL,oracle,sqlite,db2,sqlserver
非关系型数据库:通常都是以k、v键值形式存储数据,没有表结构。
例如:redis,mongodb(文档型数据库 非常接近关系型的非关系型数据),memcache
本质就是一款基于网络通信的应用软件
任何基于网络通信的软件 底层都是socket
mysql的架构
类似于 socket的客户端和服务端
流程:
1. mysql服务端先启动,监听在某一个特定的端口(3306)
2. mysql客户端连接服务端
3. mysql客户端就可以发送相关的操作命令,去操作服务端存储的数据MYSQL是一种关系型数据库管理系统,关系型数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了数据操作的速度,并提高了灵活性。
MYSQL不单单支持MYSQL的客户端来操作,也支持其他编程语言直接操作,Python,Java,C++,PHP等,他们语法都不一样,但都能操作MYSQL数据库。
在MYSQL中,客户端(mysql)发送一条SQL语句,服务端(mysqld)接收命令并相响应,从数据库中查找数据并返回。
库 >>> 文件夹
表 >>> 文件
记录 >>> 文件内一行行的数据叫做一条条的记录
表头 就是表格的第一行数据
字段 字段名+字段类型记录:1 朱葛 13234567890 22(多个字段的信息组成一条记录,即文件中的一行内容)
表:userinfo,studentinfo,courseinfo(即文件)
数据库:db(即文件夹)
数据库管理系统:如mysql(是一个软件)
数据库服务器:一台计算机(对内存要求比较高)
总结:
? 数据库服务器-:运行数据库管理软件
? 数据库管理软件:管理-数据库
? 数据库:即文件夹,用来组织文件/表
? 表:即文件,用来存放多行内容/多条记录
1.下载地址:https://dev.mysql.com/downloads/mysql/
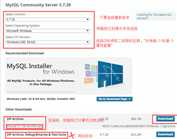
下载之后 是将MySQL的服务端和客户端都下载了下来
解压
查看文件目录
? MYSQL->bin->mysql.exe(客户端)/mysqld.exe(服务端)
服务端
mysqld
客户端
mysql2.启动流程:
先启动服务端mysqld(cmd以管理员身份运行,不然权限不足,报错。)
再启动客户端mysql(可以是普通的cmd)
1) 启动mysqld
1.切换到bin目录下
2.执行mysqld
ps:做前期MySQL配置的时候 终端建议你用管理员身份运行(”运行”--->输入”cmd"--->右键点击“cmd.exe”,以管理员身份运行
2) 启动mysql(终端可以是普通cmd)
1.切换到bin目录下
2.执行mysql -h 127.0.0.1 -P 3306 -uroot -p
其中:h表示本机(localhost),127.0.0.1是本机循环地址,P表示MYSQL端口(port),uroot表示用户名,p表示用户密码;所有参数都是以空格分开。
步骤2可以简写为:mysql -uroot -p,IP和port不需要指定,默认就是本地的。
注意:mysql在初始登陆的时候 是没有密码的 直接回车即可
mysql中的sql语句,是以分号结束的,不敲分号,默认你没有输入完,客户端还会让你继续输入
如果不输入用户名和密码 默认是访客模式登陆 所能用到的功能(库)很少,即在cmd内直接mysql回车,省去-uroot -p。
3)客户端退出登陆
exit;
quit;
查看所有的数据库
show databases;
查看某个进程
tasklist |findstr 名称
杀死进程
taskkill /F /PID 进程号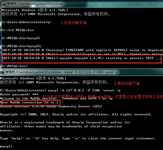
制作环境变量
将启动文件所在的路径添加到系统的环境变量中,这样就不需要切换到MYSQL/bin所在的磁盘区启动mysql客户端及服务端mysqld了。直接cmd读入mysql -uroot -p 连接服务端了。
注意:配置完之后一段要重新启动mysql服务端及cmd终端
将mysqld制作成系统服务(电脑一启动,服务端就自己启动,只需要启动客户端mysql连接)
? 制作系统服务 你的cmd终端一定要是管理员身份
cmd终端输入以下:
mysqld --install # mysqld添加到系统服务查看系统服务
services.msc # cmd输入
没有密码的情况下
mysqladmin -uroot -p password 123? 有密码的情况下
mysqladmin -uroot -p123 password 123456当命令输入错误的时候 可以用\c取消前面的命令 cancel1.现将已经启动的服务端停掉
2.修改管理员用户对应的密
update mysql.user set password=password(123) where user='root' and host='localhost';3.关闭当前服务端 重新以校验用户名密码的方式启动
4.正常以用户名密码的方式 连接mysql服务端
\s 查看 mysql服务端版本信息
在MySQL程序中重新建一个my.ini文件
# my.ini文件内容
[mysqld]
character-set-server=utf8
collation-server=utf8_general_ci
sql_mode="STRICT_TRANS_TABLES,PAD_CHAR_TO_FULL_LENGTH,ONLY_FULL_GROUP_BY "
[client]
default-character-set=utf8
[mysql]
user='root' # 用户名
password=123 # 我们设置的密码
default-character-set=utf8通常情况下配置文件的后缀都是ini结尾
mysql自带的配置文件(my-default.ini)不要修改
但是你可以新建一个配置文件 my.ini
mysql服务端在启动就会自动加载你的my.ini配置文件内的配置
修改完配置文件之后需要先将服务端停止 重新启动 才能生效
修改了配置文件一定要重启服务端1. 操作文件夹(库)
增:create database db1 charset utf8;
查:show databases; # 查所有
show create database db1; 查单个库的编码方式
改:alter database db1 charset latin1; # 修改编码
删: drop database db1; # 删库
2.操作文件(表)
在操作表的时候 需要先指定库
指定库: use 库名
先切换到文件夹下:use db1
查看当前虽在的库: select database()
增:create table t1(id int,name char);
查(三种):1)show tables; # 查看某个库下面的所有的表
2)show create table userinfo; # 查看指定表的表头所有的字段的名称及对应的约束条件;
3)desc userinfo; <==> describe userinfo; # 与2)相同,区别就是以表格的形式列出信息;
改:alter table t1 modify name char(3);
alter table t1 change name name1 char(2);
删:drop table t1;
3.记录
先创建一个库或者指定一个已经存在的库
切换到该库下 创建表
然后再操作记录
create database db1;
create table userinfo(id int,name char(32),password int);
增
insert into userinfo values(1,'jason',123); 插入单条数据
insert into userinfo values(1,'jason',123),(2,'egon',123),(3,'tank',123); 插入多条数据
查
select * from userinfo; 查询所有的字段信息
select name from userinfo; 查询指定字段信息
select id,name from userinfo where id=1 or name=tank; 带有筛选条件的字段信息
改
update userinfo set name='kevin' where id=1; 修改数据的一个字段信息
update userinfo set name='jason',password=666 where id=1; 修改数据的多个字段
删
delete from userinfo where id =1; 指定删符合条件的数据
delete from userinfo; 将表中的数据全部删除,如果有自增id,新增的数据,仍然是以删除前的最后一个id号数作为起始
truncate table userinfo;数据量大,删除速度比上一条快,且直接从零开始
*auto_increment 表示:自增
*primary key 表示:约束(不能重复且不能为空);加速查找标签:jason 模式 地址 from 结束 pre 数据不一致 删库 流程
原文地址:https://www.cnblogs.com/zhangchaocoming/p/11756231.html