标签:des style blog http os ar 使用 for sp
#-*-coding:-utf-8
import urllib
#url=‘http://iplaypython.com/‘
#url1=urllib.urlopen(url)#打开url地址,urlopen(url, data=None, proxies=None)
#print url1.read()#读取read() , readline() , readlines() , fileno() , close() :这些方法的使用方式与文件对象完全一样
#print url1.getcode()#getcode():返回Http状态码。如果是http请求,200表示请求成功完成;404表示网址未找到;
#print url1.geturl()#返回url地址
#print url1.info()#返回一个httplib.HTTPMessage 对象,表示远程服务器返回的头信息;
#c=html.read().decode(‘gbk‘).encode(‘utf-8‘)
#print c 也可以这样设置编码
#c=html.read().decode(‘gbk‘,‘ignore‘).encode(‘utf-8‘)
#print c
#‘ignore‘忽略
#urlretrieve()方法 ,回调函数应用
#需要3个参数才能使用它
#参数1,传入网址。,网址类型一定是字符串
#参数2,传入本地的网页保存路径+文件名
#参数3,一个函数的调用,可以任意的定义这个函数的行为,但是一定要保证这个函数有3个参数
"""
(1).到目前为此传递的数据块数量
(2).是每个数据块的大小,单位的byte(字节)
(3).远程文件的大小.(有时候返回-1)
"""
def cbk(a,b,c):
abc=100*a*b/c
if abc>100:
abc=100
print ‘%.2f%%‘%abc
url=‘http://www.qq.com‘
locpath=‘C:\Users\Administrator\Desktop\sinaa.html‘
print urllib.urlretrieve(url,locpath,cbk)
#获取远程数据时,内部会使用URLopener或者FancyURLOpener类,作炎urllib使用都,很少使用这2个类,如果对urllib的实现感兴趣, 或者希望urllib支持更多的协议,可以研究这两个类。在Python手册中,urllib的作者还列出了这个模块的缺陷和不足,感兴趣的同学可以打开 Python手册了解一下
"""
urllib中还提供了一些辅助方法,用于对url进行编码、解码。url中是不能出现一些特殊的符号的,有些符号有特殊的用途。我们知道以get方式提交数据的时候,会在url中添加key=value这样的字符串,所以在value中是不允许有‘=‘,因此要对其进行编码;与此同时服务器接收到这些参数的时候,要进行解码,还原成原始的数据。这个时候,这些辅助方法会很有用:
* urllib.quote(string[, safe]):对字符串进行编码。参数safe指定了不需要编码的字符;
* urllib.unquote(string) :对字符串进行解码;
* urllib.quote_plus(string [ , safe ] ) :与urllib.quote类似,但这个方法用‘+‘来替换‘ ‘,而quote用‘%20‘来代替‘ ‘
* urllib.unquote_plus(string ) :对字符串进行解码;
* urllib.urlencode(query[, doseq]):将dict或者包含两个元素的元组列表转换成url参数。例如 字典{‘name‘: ‘dark-bull‘, ‘age‘: 200}将被转换为"name=dark-bull&age=200"
* urllib.pathname2url(path):将本地路径转换成url路径;
* urllib.url2pathname(path):将url路径转换成本地路径;
"""
data1=‘name=~a+3‘
data1=urllib.quote(data1)
print data1#result:name%20%3D%20%7Ea%2B3
print urllib.unquote(data1)#name=~a+3
data2=urllib.quote_plus(data1)
print data2# result: name+%3D+%7Ea%2B3
print urllib.unquote_plus(data2) # result: name = ~a+3
data3 = urllib.urlencode({ ‘name‘: ‘dark-bull‘, ‘age‘: 200 })
print data3 # result: age=200&name=dark-bull
data4 = urllib.pathname2url(r‘d:\a\b\c\23.php‘)
print data4 # result: ///D|/a/b/c/23.php
print urllib.url2pathname(data4) # result: D:\a\b\c\23.php
如图: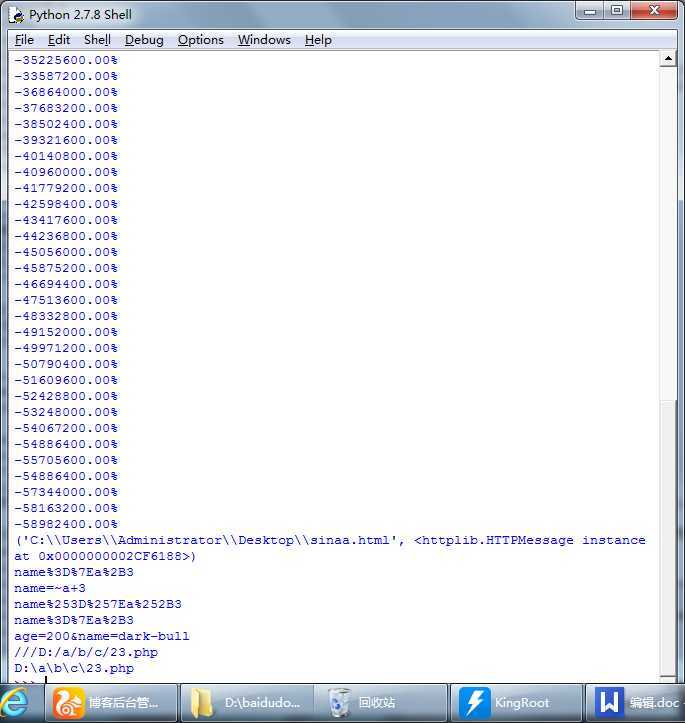
------------介绍2
#-*-coding:utf-8
# import urllib
# url=‘http://www.qq.com‘
# info=urllib.urlopen(url).info()
# print info
# print info.getparam(‘charset‘)#-*-coding:-utf-8获取网页编码
import chardet#字符集检测(用来实现字符串/文件编码检测模板)
import urllib
# url=‘http://www.jd.com‘
# conten=urllib.urlopen(url).read()
# print chardet.detect(conten)
# result=chardet.detect(conten)
# print result[‘encoding‘]
# print chardet.detect(‘我是中文‘)
def auto_chardet(url):
"""doc"""
content=urllib.urlopen(url).read()
result=chardet.detect(content)
encoding=result[‘encoding‘]
return encoding
urls=[‘http://WWW.IPLAYPYTHON.com‘,‘http://www.baidu.com‘]
for url in urls:
print url,auto_chardet(url)
----------介绍3
#-*-coding:utf-8
# import urllib
# url=‘http://blog.csdn.net/yuanmeng001‘
# html=urllib.urlopen(url)
# #print html.read()
# #print html.getcode()#403禁止访问:404网页不存在(例子:http://www.jd.com/robots.txt)
import urllib2,random
url=‘http://blog.csdn.net/happydeer‘
# my_header={‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.3.1.2000 Chrome/30.0.1599.101 Safari/537.36‘,
# ‘GET‘:url,
# ‘HOst‘:‘blog.csdn.net‘,
# ‘Referer‘:‘http://blog.csdn.net/‘
# }
# https=urllib2.Request(url,headers=my_header)
# #print https.head()#urllib2.HTTPError: HTTP Error 403: Forbidden禁止访问
# # req=urllib2.Request(url)#请求对象
# # # req.add_header(‘User-Agent‘,‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.3.1.2000 Chrome/30.0.1599.101 Safari/537.36‘)
# # # #add_header添加头部信息
# # # req.add_header(‘GET‘,url)
# # req.add_header(‘HOst‘,‘blog.csdn.net‘)
# # req.add_header(‘GET‘,url)
# # req.add_header(‘Referer‘,‘http://blog.csdn.net/‘)
# html=urllib2.urlopen(https)
#print html.read()#读取
# print html.headers.items()#获取信息
my1_header={‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.3.1.2000 Chrome/30.0.1599.101 Safari/537.36‘,
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.3.1.2000 Chrome/30.0.1599.101 Safari/537.36‘,
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.3.1.2000 Chrome/30.0.1599.101 Safari/537.36‘,
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.3.1.2000 Chrome/30.0.1599.101 Safari/537.36‘,
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.3.1.2000 Chrome/30.0.1599.101 Safari/537.36‘,}
def get_connect(url,heads):
‘‘‘@获取403禁止访问的网页‘‘‘
rand_head=random.choice(heads)
req=urllib2.Request(url)
req.add_header(‘User-Agent‘,rand_head)
req.add_header(‘HOst‘,‘blog.csdn.net‘)
req.add_header(‘Request‘,‘http://blog.csdn.net/‘)
req.add_header(‘GET‘,url)
content=urllib2.urlopen(req).read()
return content
print get_connect(url,my1_header)
标签:des style blog http os ar 使用 for sp
原文地址:http://www.cnblogs.com/mhxy13867806343/p/4058370.html