标签:数据类型 mic 增强 尺寸 基础上 故事 图片 冻结 div
这是继SRCNN(超分辨)之后,作者将CNN的战火又烧到了去压缩失真上。我们看看这篇文章有什么至今仍有启发的故事。
贡献:
ARCNN。
讨论了low-level的迁移学习优势。
现有的(传统的)方法要么只关注去除块效应,要么只关注去模糊,没有能兼得的。后果就是这两种操作相互矛盾,去块效应的同时导致模糊,去模糊的同时导致振铃效应。
作者尝试将3层的SRCNN直接用于去除压缩失真,发现效果不好。作者于是在中间增加了一层,美其名曰“feature enhancement”。
但“deeper is not better”,作者遇到了训练困难。为了解决这一问题,作者尝试了迁移学习。为了更好地迁移学习,作者探索了两种策略:
高质量压缩模型 迁移至 低质量压缩模型。
简单标准压缩模型 迁移至 复杂现实压缩模型。
作者声称,这是第一次在low-level视觉任务上研究迁移学习的优势。
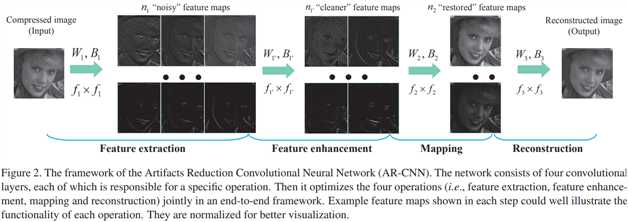
一看就懂,4层CNN,虽然每一层的功能命名很花哨。
只在亮度通道操作。
ReLU激活,
作者“辩称”:这可不是简单地在三层SRCNN的基础上加一层。如果只是加一层中间层,相当于增强了非线性的回归器。但对于JPEG压缩失真,其难点在于特征提取。因此我们是通过增加一层,增强了特征的提取能力。因此美其名曰“特征增强层”。
MSE loss,SGD优化。
在实验中,4层分别有64、32、16和1个滤波器,尺寸分别为9、7、1和5。
我们重点看迁移。
从浅模型迁移至深模型,比直接训练深模型更好:收敛更快,收敛更好。
从高质量压缩模型 迁移到 低质量压缩模型,比直接训练 低质量压缩模型 效果更好。
迁移 高质量压缩模型 到 真实压缩模型(从推特上收集的),比直接训练真实压缩模型更好。此外,迁移低质量压缩模型也不错,但不如高质量的。【这和数据类型有关,不能盖棺定论】
以上迁移后,网络没有冻结的部分。
Paper | Compression artifacts reduction by a deep convolutional network
标签:数据类型 mic 增强 尺寸 基础上 故事 图片 冻结 div
原文地址:https://www.cnblogs.com/RyanXing/p/11759112.html