标签:lte 查询语句 允许 str 独立 分解 自动 image 估算
最左匹配原则
1、先定位该sql的查询条件,有哪些,那些是等值的,那些是范围的条件。
2、等值的条件去命中索引最左边的一个字段,然后依次从左往右命中,范围的放在最后。
分析讲解
1、mysql的索引分为聚簇索引和非聚簇索引,mysql的表是聚集索引组织表。
聚集规则是:有主键则定义主键索引为聚集索引;没有主键则选第一个不允许为NULL的唯一索引;还没有就使用innodb的内置rowid为聚集索引。
非聚集索引也称为二级索引,或者辅助索引。
2、mysql的索引无论是聚集索引还是非聚集索引,都是B+树结构。聚集索引的叶子节点存放的是数据,非聚集索引的叶子节点存放的是非聚集索引的key和主键值。B+树的高度为索引的高度。
3、索引的高度
聚集索引的高度决定了根据主键取数据的理论IO次数。根据非聚集索引读取数据的理论IO次数还要加上访问聚集索引的IO次数总和。实际上可能要不了这么多IO。因为索引的分支节点所在的Page因为多次读取会在mysql内存里cache住。
mysql的一个block大小默认是16K,可以根据索引列的长度粗略估算索引的高度。
sql优化依据
SQL语句中的where条件,使用以上的提取规则,最终都会被提取到Index Key (First Key & Last Key),Index Filter与Table Filter之中。
Index First Key,只是用来定位索引的起始范围,因此只在索引第一次Search Path(沿着索引B+树的根节点一直遍历,到索引正确的叶节点位置)时使用,一次判断即可;
Index Last Key,用来定位索引的终止范围,因此对于起始范围之后读到的每一条索引记录,均需要判断是否已经超过了Index Last Key的范围,若超过,则当前查询结束;
Index Filter,用于过滤索引查询范围中不满足查询条件的记录,因此对于索引范围中的每一条记录,均需要与Index Filter进行对比,若不满足Index Filter则直接丢弃,继续读取索引下一条记录;
Table Filter,则是最后一道where条件的防线,用于过滤通过前面索引的层层考验的记录,此时的记录已经满足了Index First Key与Index Last Key构成的范围,并且满足Index Filter的条件,回表读取了完整的记录,判断完整记录是否满足Table Filter中的查询条件,同样的,若不满足,跳过当前记录,继续读取索引的下一条记录,若满足,则返回记录,此记录满足了where的所有条件,可以返回给前端用户
分析
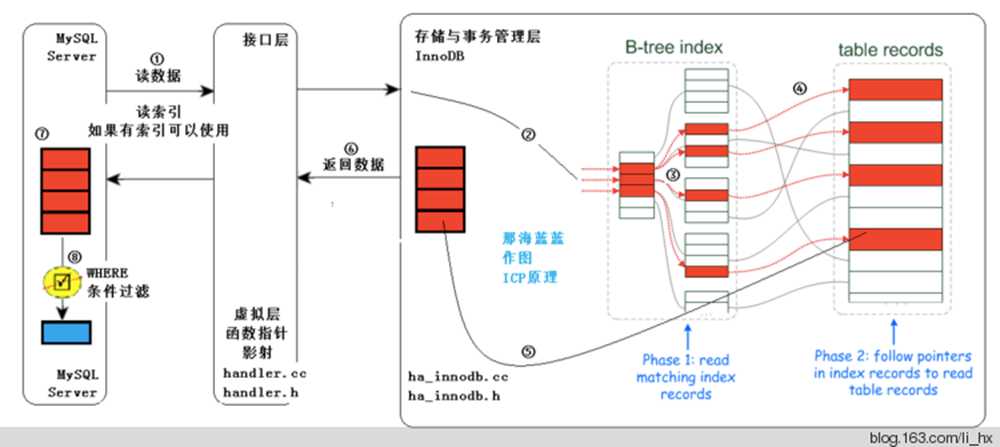
一条sql语句要执行完成需要经历什么样的过程
当一条sql语句提交给mysql数据库进行查询的时候需要经历以下几步
1、先在where解析这一步把当前的查询语句中的查询条件分解成每一个独立的条件单元
2、mysql会自动将sql拆分重组
3、然后where条件会在B-tree index这部分进行索引匹配,如果命中索引,就会定位到指定的table records位置。如果没有命中,则只能采用全部扫描的方式
4、根据当前查询字段返回对应的数据值
Mysql - 什么情况下索引不会被命中
1、如果条件中有 or ,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)
注意:要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
如果出现OR的一个条件没有索引时,建议使用 union ,拼接多个查询语句
2.、like查询是以%开头,索引不会命中
只有一种情况下,只查询索引列,才会用到索引,但是这种情况下跟是否使用%没有关系的,因为查询索引列的时候本身就用到了索引
3. 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
4. 没有查询条件,或者查询条件没有建立索引
5. 查询条件中,在索引列上使用函数(+, - ,*,/), 这种情况下需建立函数索引
6. 采用 not in, not exist
7. B-tree 索引 is null 不会走, is not null 会走

mysql索引命中规则
标签:lte 查询语句 允许 str 独立 分解 自动 image 估算
原文地址:https://www.cnblogs.com/starluke/p/11741041.html