标签:linear 归一化 上进 oid inf 处理流程 区域 结构 mamicode
一.网络结构
AlexNet由5层卷积层和3层全连接层组成。
论文中是把网络放在两个GPU上进行,为了方便我们仅考虑一个GPU的情况。
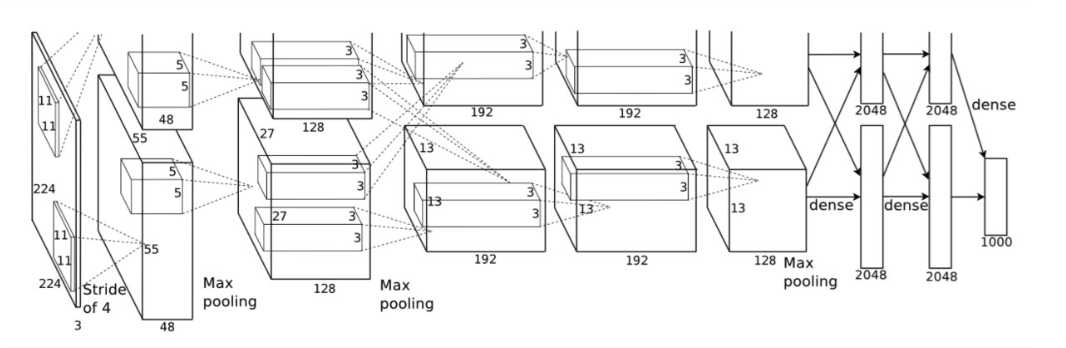
上图中的输入是224×224224×224,不过经过计算(224−11)/4=54.75(224−11)/4=54.75并不是论文中的55×5555×55,而使用227×227227×227作为输入,
卷积层C1:处理流程为:卷积、ReLU、LRN、池化、
卷积:输入为227x227x3,使用96个11x11x3的卷积核,步长为4x4,得到FeatureMap为55x55x96
池化:3x3最大池化,步长为2,得到27x27x96的FeatureMap
卷积层C2: 处理流程为:卷积、ReLU、LRN、池化
卷积:输入为27x27x96,使用256个5x5x96的卷积核(padding = 2),步长为1x1,得到FeatureMap为27*27*256
池化:3x3最大池化,步长为2,得到13x13x26的FeatureMap
卷积层C3: 处理流程为:卷积、ReLU
卷积: 输入为13x13x256,使用384个3x3x256的卷积核(padding = 1),,步长为1x1,得到13x13x384的FeatureMap
卷积层C4: 处理流程为: 卷积、ReLU
卷积:输入为13x13x384,使用256个3x3x384的卷积核(padding = 1),,步长为1x1,得到13x13x256的FeatureMap
卷积层C5:处理流程为:卷积、ReLU、池化
卷积:输入为13x13x256,使用256个3x3x256的卷积核,步长为1x1(padding = 1),,得到13x13x256的FeatureMap
池化:3x3的最大池化,步长为2,得到6x6x256的FeatureMap
全连接层FC6: 处理流程为:全连接、ReLU、Dropout
全连接;输入为6x6x256,使用4096个6x6x256的卷积核,得到1x1x4096
全连接层FC7: 处理流程为:全连接、ReLU、Dropout
全连接:输入1x1x4096,使用4096个1x1x4096的卷积核,得到1x1x4096
输出层:第七层4096个数据与第八层1000个神经元进行全连接,输出1000个float值
二.,模型特点
1.ReLU Nonlinearity
标准L-P神经元的输出一般使用tanh或者sigmoid函数作为激活函数,这些饱和的非线性函数计算机梯度的时候要比非饱和函数max(0,x)慢得多,把非饱和线性函数成为Rectified Linear Units(ReLUs)
2.在两个GPU上训练
使用的GPU为GTX 580,内存只有3GB,使用一个GPU可能会限制训练网络的大小规模,因此使用两个GPU。
并行方案为把一半的神经元放在一个GPU上,GPU的交流仅在一些层上。比如第三层的将第二层的所有输出作为输入,但是第四层将第三层只属于同个GPU的输出作为输入。
3.Local Response Normalization
引入LRN,是为了模仿生物上,被激活的神经元抑制相邻神经元,即侧抑制,归一化的目的就是抑制,LRN借鉴侧抑制实现局部抑制。
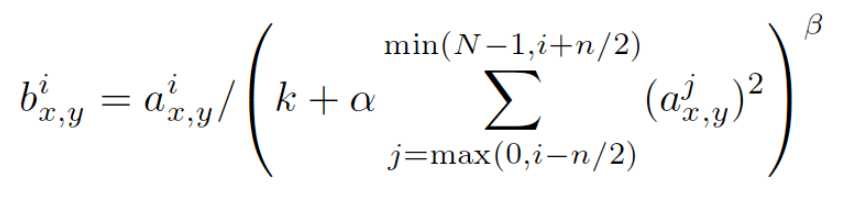
其中bix,y为归一化后的值,i表示通道的位置,x,y代表像素更新的位置
aix,y为输入值,是激活函数ReLU的输入值
k,alpja,beta,n/2为自定义系数,一般设置k=2,n=5,alpha=1Xe-4,beta=0.75。
∑叠加方向是沿着通道方向,也就是一个点同方向的前面n/2个通道和后n/2个通道的点的平方和(n+1个点)

3.4Overlapping pooling
重叠池化有助于减少过拟合。
设池化的大小为zxz,步长为s,如果s<z,即每次池化都会和相邻池化有一部分重叠,称为重叠池化
三.减少过拟合操作
1数据增强
模型随机从256x256大小的原始图像中截取224x224大小的区域,同时还得到图片进行水平翻转后的镜像,相当于数据扩充了2048倍(2^(5+5+2))
测试时,模型会先截取一张图片的四个角加中间位置,并进行左右翻转,这样会获得10张图片,将10张图片作为预测的输入并对得到的10个预测结果求平均值,就是这样图片的预测结果。
2.dropout
标签:linear 归一化 上进 oid inf 处理流程 区域 结构 mamicode
原文地址:https://www.cnblogs.com/wengyuyuan/p/11769965.html