标签:pytho com 响应 构造 ext data 红色 try 本地
从百度图片下载一些图片当做训练集,好久没写爬虫,生疏了。没有任何反爬,随便抓。
网页:
动态加载,往下划会出现更多的图片,一次大概30个。先找到保存每一张图片的json,其对应的url:
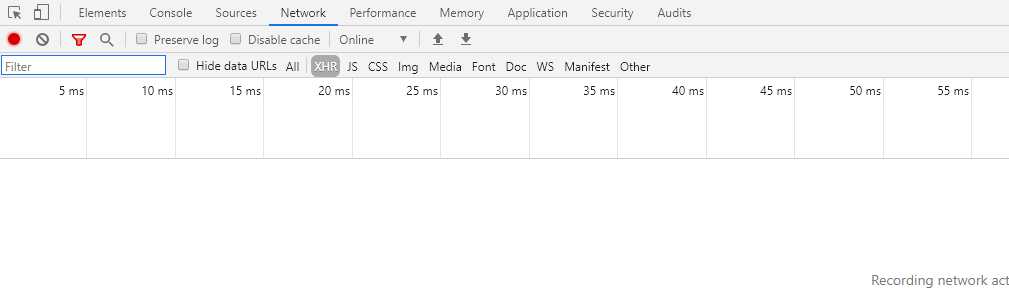
打开调试,清空,然后往下划。然后出现:

点击左侧的链接,出现右边的详细信息,对应的就是URL。对这个url做请求即可。以下是代码:
# -*- coding: utf-8 -*- # import tensorflow as tf # import os # import numpy as np import requests import my_fake_useragent as ua import re import random # 蓝色背景 def blue_print(*s, end=‘\n‘): for item in s: print(‘\033[46m {} \033[0m‘.format(item), end=‘‘) print(end=end) # 高亮,绿色字体,红色背景 def green_print(*s, end=‘\n‘): # print(‘\033[1m {} \033[0m‘.format(s), end=end) for item in s: print(‘\033[1;32;41m {} \033[0m‘.format(item), end=‘‘) print(end=end) class download_data(): def __init__(self): # 初始化常用参数 # 请求头 self.user_agent = ua.UserAgent() # 正则用于匹配响应内容中的图片url self.pattern_url = r‘"thumbURL":"(.*?)"‘ # 爬虫:从网上下载数据集 def get_url_from_internet(self, url): for i in range(5): try: # print(self.user_agent.random()) res = requests.get(url, headers={‘User-Agent‘: self.user_agent.random()}, timeout=5) # print(res.text) url_list = re.findall(self.pattern_url, res.text) # print(url_list) return url_list except: pass # 这里可以将请求失败的url存入数据库,防止数据丢失 return None def write_img(self, url): for i in range(3): try: # 真正下载图片数据的,就这两行代码 res = requests.get(url, headers={‘User-Agent‘: self.user_agent.random()}, timeout=5) img = res.content # print(img) # 将响应内容写入本地*.jpg文件中 with open(‘dataset/monkey{}.jpg‘.format(random.randint(10 ** 8, 10 ** 9)), ‘wb‘) as f: f.write(img) print(‘monkey{} 下载完成‘.format(random.randint(10 ** 8, 10 ** 9))) return except: pass # 这里可以将请求失败的url存入数据库,防止数据丢失 return None if __name__ == ‘__main__‘: tt = download_data() for page in range(0, 1000, 30): # 构造url,设置range的右边界越大,下载的图片就越多 url = ‘https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result &queryWord=%E7%8C%B4%E5%AD%90+%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic= &hd=&latest=©right=&word=%E7%8C%B4%E5%AD%90+%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face= &istype=&qc=&nc=&fr=&expermode=&force=&pn={}&rn=30&gsm=&1572502599384=‘.format(page) url_list = tt.get_url_from_internet(url) if url_list: for each_url in url_list: tt.write_img(each_url)
什么都不打印看着不舒服,随便打印一些结果出来:
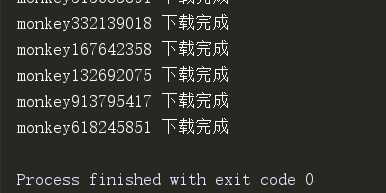
文件夹:
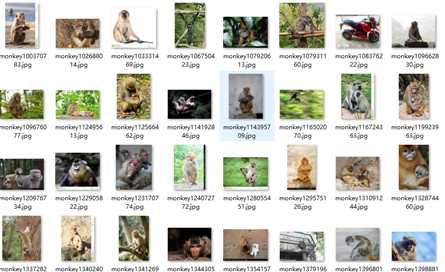
用网上的图片作训练集,而且还是自己抓的,效果估计不会太好。先用着看。自己手动将质量差的图片删一删。
python3 TensorFlow训练数据集准备 下载一些百度图片 入门级爬虫示例
标签:pytho com 响应 构造 ext data 红色 try 本地
原文地址:https://www.cnblogs.com/zrmw/p/11771710.html