标签:padding 创建 dex 允许 b+树 str class 唯一索引 pre
分为聚集索引和非聚集索引。
每个表有且一定会有一个聚集索引,整个表的数据存储在聚集索引中,mysql索引是采用B+树结构保存在文件中,叶子节点存储主键的值以及对应记录的数据,非叶子节点不存储记录的数据,只存储主键的值。当表中未指定主键时,mysql内部会自动给每条记录添加一个隐藏的rowid字段(默认4个字节)作为主键,用rowid构建聚集索引。
聚集索引在mysql中又叫主键索引。
也是b+树结构,不过有一点和聚集索引不同,非聚集索引叶子节点存储字段(索引字段)的值以及对应记录主键的值,其他节点只存储字段的值(索引字段)。
每个表可以有多个非聚集索引。
即一个索引只包含一个列。
即一个索引包含多个列。
索引列的值必须唯一,允许有一个空值。
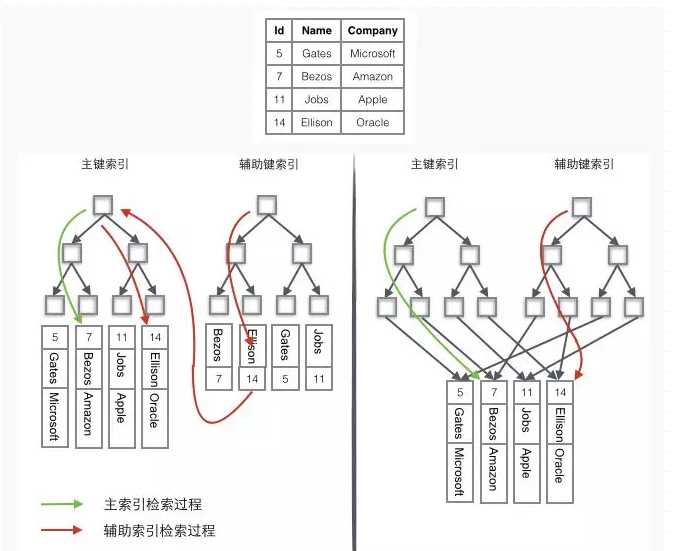
左边为innoDB(聚簇)表分布
上面的表中有2个索引:id作为主键索引,name作为辅助索引。
innodb我们用的最多,我们只看图中左边的innodb中数据检索过程:
如果需要查询id=14的数据,只需要在左边的主键索引中检索就可以了。
如果需要搜索name=‘Ellison‘的数据,需要2步:
先在辅助索引中检索到name=‘Ellison‘的数据,获取id为14
再到主键索引中检索id为14的记录
辅助索引相对于主键索引多了第二步。
create [unique] index 索引名称 on 表名(列名[(length)]);
alter 表名 add [unique] index 索引名称 on (列名[(length)]);
如果字段是char、varchar类型,length可以小于字段实际长度,如果是blog、text等长文本类型,必须指定length。
[unique]:中括号代表可以省略,如果加上了unique,表示创建唯一索引。
如果table后面只写一个字段,就是单列索引,如果写多个字段,就是复合索引,多个字段之间用逗号隔开。
drop index 索引名称 on 表名;
查看某个表中所有的索引信息如下:
show index from 表名;
可以先删除索引,再重建索引。
create index idx1 on test1 (id);
create unique index idx2 on test1(name);
select * from test1 a where a.email = ‘javacode1000085@163.com‘;
所有的email记录,每条记录的前面15个字符是不一样的,结尾是一样的(都是@163.com),通过前面15个字符就可以定位一个email了,那么我们可以对email创建索引的时候指定一个长度为15,这样相对于整个email字段更短一些,查询效果是一样的,这样一个页中可以存储更多的索引记录,命令如下:
create index idx3 on test1 (email(15));
show index from test1
我们删除idx1,然后再列出test1表所有索引,如下:
drop index idx1 on test1;
show index from test1;
标签:padding 创建 dex 允许 b+树 str class 唯一索引 pre
原文地址:https://www.cnblogs.com/biao/p/11778328.html