标签:函数 指标 初始 提升 技术 fir滤波器 计算 相加 过程
传统的IIR和FIR滤波器在处理输入信号的过程中滤波器的参数固定,当环境发生变化时,滤波器无法实现原先设定的目标。自适应滤波器能够根据自身的状态和环境变化调整滤波器的权重。
自适应滤波器理论
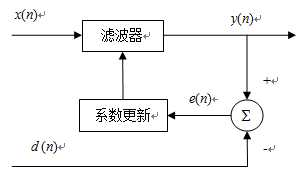
$x(n)$是输入信号,$y(n)$是输出信号,$d(n)$是期望信号或参考信号,$e(n)=d(n)-y(n)$为误差信号。根据自适应算法和误差信号$e(n)$调整滤波器系数。
自适应滤波器类型。可以分为两大类:非线性自适应滤波器、线性自适应滤波器。非线性自适应滤波器包括基于神经网络的自适应滤波器及Volterra滤波器。非线性自适应滤波器信号处理能力更强,但计算复杂度较高。所以实践中,线性自适应滤波器使用较多。
主要分为两类FIR滤波器、IIR滤波器。
自适应滤波器算法按照不同的优化准则,常见自适应滤波算法有:递推最小二乘算法(RLS),最小均方误差算法(LMS),归一化均方误差算法(NLMS),快速精确最小均方误差算法,子带滤波,频域的自适应滤波等等。
自适应AEC问题中应用最广泛的就是自适应滤波算法,其中最早是由Widrow和Hoff在1959年所提出的最小均方(Least Mean Square,LMS)算法
LMS算法基于维纳滤波理论,采用最速下降算法,通过最小化误差信号的能量来更新自适应滤波器权值系数。
归一化最小均方(Normalized Least Mean Squares,==NLMS)==算法是改进的LMS算法,根据原LMS算法中误差信号与远端输入信号的乘积,对远端输入信号的平方欧式范数进行归一化处理,将固定步长因子的LMS算法变为根据输入信号时变的变步长NLMS算法,
优点:收敛速度快,
缺点:算法的稳定性和跟踪能力上较易受输入噪声的影响
通过对回声路径模型的分析,发现回声能量中较活跃系数均在时域聚集,且比重很小,其数值只有很少不为零的有效值,大多数都是零值或者接近零值,这就是回声路径具有的稀疏特性
根据回声路径的稀疏性,Duttweiler引入了比例自适应的思想,提出了比例归一化最小均方算法 PNLMS,按比例分配滤波器的权值向量大小,该算法对回声消除的发展具有非常重要的意义。
该算法采用与滤波器抽头稀疏成正比的可变步长参数来调整算法收敛速度,利用其抽头稀疏的比例值来判断当前权重稀疏所属的活跃状态,根据状态的不同,所分配的步长大小也有所差异,活跃抽头系数分配较大的步长参数,这样可以加速其收敛,而不活跃的抽头系数则相反,通过分配其较小的步长参数来提高算法的稳态误差。每个滤波器抽头被分别赋予了不同估计值,算法的稳态收敛性得到了明显改善。然而,PNLMS 有一个明显的缺点,即比例步长参数的选择引入了定值,这会导致估计误差累积,最后使算法在后期的收敛速度减慢下来。
优点:使算法对于稀疏的回声路径,在初始阶段拥有快速的收敛速率,与此同时降低了稳态误差,
缺点:
PNLMS ++算法,在每个采样周期内,通过将NLMS算法和PNLMS算法之间进行交替来实现收敛速度方面的提升。但是PNLMS ++算法只在回声路径稀疏或高度非稀疏的情况下表现良好。
CPNLMS 算法(Composite PNLMS)通过比较误差信号功率和已设阈值大小,来判断算法采用 PNLMS 还是 NLMS 算法
$\mu$准则MPNLMS算法:为了解决PNLMS算法后程收敛速度慢的问题,将最速下降法应用到PNLMS算法中,使用$\mu$准则来计算比例因子(使用对数函数代替PNLMS算法中的绝对值函数)
IPNLMS算法,基于L1范数将估计的回声路径权值向量均值与比例步长参数之和作为比例矩阵的对角元素(通过调整滤波器的比例参数步长),使得IPNLMS有着和PNLMS相近的初始收敛速率,并且在非稀疏的回声路径条件下,IPNLMS的收敛速率相比PNLMS有所改善,但性能改善的同时也增加了计算复杂度。
在PNLMS类算法进行自适应迭代更新过程中,大抽头权值向量拥有大步长因子,这样提升了收敛速率,但滤波器自适应收敛至接近稳态时,大抽头权值向量将会产生较大的稳态误差。为了解决这一问题,P.A.Naylor提出了改进的IPNLMS(Improved IPNLMS,IIPNLMS)算法。IIPNLMS算法在IPNLMS算法的基础之上,对于数值较大的权值向量,使用较小的参数使得其步长成比例减小,从而降低系数噪声。
MPNLMS算法引入最优步长控制矩阵,均衡了滤波器大小系数之间的更新,修正了 PNLMS 算法收敛后期速度慢的缺点,但
SPNLMS算法,将MPNLMS滤波器更新过程中的对数运算化简为两段简单函数的形式。
改进的 MPNLMS算法,采用多个分段函数来近似 MPNLMS 的对数函数,从而降低算法的复杂度。
改进的 SPNLMS算法,通过控制步长控制矩阵迭代的频率降低算法复杂度。收敛速度也所下降
以上对 MPNLMS 的改进算法在减小算法运算复杂度的情况下损害了收敛性能和稳定性能。
有时候回声路径的稀疏程度会根据温度、压力以及房间墙面的吸声系数等等因素而产生变化,这就需要一种能够适应不同稀疏度变化的AEC算法。
稀疏控制比例回声消除算法(SC-PNLMS、SC-MPLNMS、SC-IPNLMS),使用新的稀疏控制方法动态地适应回声路径的稀疏程度,使得算法在稀疏和非稀疏的回声路径条件下都有良好的性能表现,体现了稀疏控制类的自适应滤波算法能够提高算法对回声路径稀疏程度的鲁棒性。
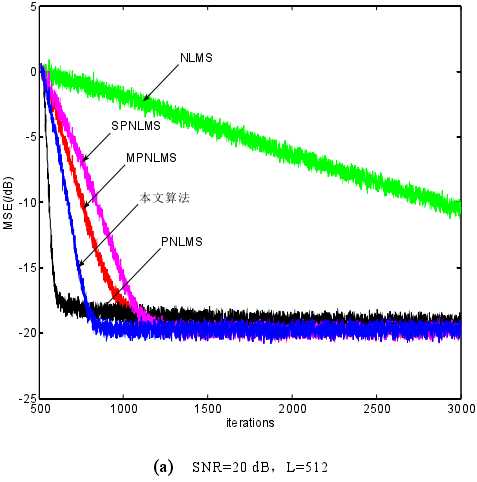
小总结:通过上述对 PNLMS 算法的分析,可知导致 PNLMS 算法整体收敛速度慢的原因主要是大系数和小系数之间收敛的不均衡。尽管很多学者针对此缺陷提出了修正算法,如 PNLMS++、CPNLMS 等,但是 PNLMS 忽略小系数收敛的缺陷并未从根本上得到改善,因此这些改进算法的效果不是十分理想。Deng通过对滤波器系数收敛过程的定量分析,在权系数更新过程中推导出最优步长的计算方式,提出一种改进的算法——MPNLMS 算法。MPNLMS 中 P 步长的计算方式克服了 PNLMS 过分注重大系数收敛忽略小系数收敛的缺点,修正了 PNLMS 收敛后期速度慢的缺陷。
一种新的改进型 PNLMS 算法,因 PNLMS 算法只注重大系数更新,忽视小系数收敛,致使算法在收敛后期速度下降,因此在 P 步长引入的同时必须注意小系数的更新。MPNLMS 算法通过建立 P 步长与当前滤波器权系数的函数关系,在一定程度上解决了 PNLMS 算法后期收敛速度慢的问题,但滤波过程包含了对数运算,不利于系统的实时实现。
? 本文通过定量分析滤波过程,并考虑到大、小系数的收敛,建立了一种新的 P步长与当前滤波器系数之间的映射关系,降低了算法的运算复杂度。 该改进算法以 PNLMS 算法为基础,通过改变收敛过程来克服 PNLMS 算法的缺陷
在声学回声消除应用中,远端输入语音信号的相关性较高,然而,传统的方法是基于“信号的无关性”假设的,传统的全带LMS 和NLMS 等计算复杂度低的随机梯度算法收敛速度明显下降。
远端语音信号相关性有两层含义:
一般来说,语音信号相比白色信号,前者明显有更大的频谱动态范围,即更大的信号相关性。因此,可以通过降低输入信号的相关性来加快算法收敛速度,但是行之有效的一种方法是将自适应滤波器和滤波器组理论相结合,提出了子带自适应滤波(subband adaptive filter,SAF)算法,
子带自适应滤波器:SAF算法将相关信号通过滤波器组分割成近似无关的各个子带独立信号(子带分割)。然后对子带信号进行多速率抽取来获得采样信号,再进行信号的自适应处理。为研究子带自适应滤波器,首先需要了解多速率信号抽取系统和滤波器组。
用于子带自适应滤波器的多速率抽取系统有下采样和上采样两种,主要通过抽取和插值方法来使系统获得不同采样率。输入信号经过 N 个滤波器分频后的总采样点数是原信号的 N 倍,大幅度提高的采样数增加了计算量。
信号子带分割通过滤波器组实现。滤波器组由分析滤波器和综合滤波器共同组成。而滤波器组的实质是一系列带通滤波器。
分析滤波器组将数字信号分割后抽取成多个子带信号,经过信号处理后,综合滤波器组再对子带信号进行插值和滤波相加而恢复成原来的信号。
在传统的 SAF中,子带自适应算法都是以最小化子带误差信号为目标的,这样基于局部目标函数误差的最小化不一定是全局误差能量最小化。而分析滤波器组在子带切割和综合滤波器组重建全带信号时皆会引入时延,在AEC 应用中,这样的时延会使包含近端语音的全带误差信号传到远端,为了消除时延的影响,无延时子带闭环结构系统以全局误差能量最小化为约束条件来调整滤波器系数。最后,确保自适应滤波算法能够收敛到最佳的滤波器系数。
子带自适应算法的后续发展
问题:针对SAF算法稳态误差较高的问题
解决:提出了 基于最小扰动原理提出了归一化的SAF(normalized SAF,NSAF)算法。
优点:由于SAF类算法固有的解相关特性,NSAF在处理相关输入信号时比全带的NLMS收敛速度快,而且计算成本与NLMS不相上下
近几年研究人员为了能够提升AEC算法的收敛性能和稳态性能,在NSAF的基础上结合全带自适应滤波算法的成比例理论,提出了几种改进的NSAF算法,例如不同形式的变步长因子NSAF以及变正则化参数NSAF。为了在识别稀疏回声路径时快速收敛,文献[22,23]将NLMS算法中的成比例思想以类比的方式融合到NSAF算法中,提出了比例NASF(proportionate NASF,PNSAF)算法和μ准则PNSAF(μ-law PNASF,MPNSAF)算法。
因为子带结构中存在混叠分量问题
2004年K. A. Lee 和 W. S. Gan提出了基于最小扰动原理的多带结构式自适应滤波器(Multiband Structured SAF,MSAF)算法,并给出了自适应滤波器抽头系数的更新方程。该结构完全不存在滤波器输出端的混叠分量问题。
子带自适应滤波器中每个子带单独使用一个子滤波器。该结构会导致输出端产生混叠分量,解决此问题的传统方法多以降低信号的质量或增大稳态误差为代价,Lee 和 Gan在 2004 年提出了一种全新多带结构。不同于子带滤波器在每个子带都使用不同的滤波器,多带结构的每个子带使用相同的全带滤波器,这很好地克服了输出端存在混叠分量的问题。
问题:针对回声路径很长且复杂,并且回升延迟较高时,时域自适应滤波算法计算复杂度高的问题,
解决:[12~14]提出了==多延迟频域分块滤波==(MDF)算法,MDF算法将长度为L的自适应滤波器分成FFT长度
的整数倍个子块,对输入信号的每个子块进行频域内的LMS算法。
《声学回声消除中子带和块稀疏自适应算法研究_魏丹丹》
远端输入语音信号的相关性较高,且声学回声信道的冲击响应一般只有少量的非零系数,因此是一个稀疏信道。
针对用于声学回声消除的子带和块稀疏算法进行了研究和改进,以达到提高算法跟踪性能和抗冲激鲁棒性的目的。本文的主要贡献如下:
首先,区别于传统文献中子带归一化自适应算法消除回声的方法,
我提出一种用于声学回声消除的新型子带归一化自适应滤波切换算法(LMS-NSAF)。
该算法核心思想是根据语音信号的状态不同,采用 VAD 快慢包络技术切换算法,当输入远端信号的瞬时能量值较大时,使用收敛速度快的子带 NLMS 算法,当输入信号的瞬时能量值较小时,则使用计算复杂度低的权重矢量更新公式,从而使得改进的子带 NLMS 算法在提高收敛性的同时又能降低算法的计算复杂度
基于多带结构的改进型自适应滤波切换算法NLMS-NSAF
首先远端语音信号利用包络法判别有无语音段,
然后将信号状态输出到自适应多带结构算法模块当中。
若语音区输入信号的短时能量较大,则使用收敛速度快的自适应滤波算法(NLMS);
若语音区输入信号的短时能量较小,需考虑计算量低的算法(NSAF),
当然,语音在无语音区时算法迭代停止。
对输入语音信号能量高低的判定是通过和阈值比较得到的。在充分考虑语音特性的情况下,切换算法实现了算法在收敛速度的优势,同时完成了同算法复杂度的优化选择。最后达到了提高滤波算法性能、降低运算量的目的。
有人说:基于维纳滤波发展起来的 LMS 算法因其结构简单,运算量小,稳定性好等特性,依然是目前得到广泛应用的一种自适应滤波算法。
回声路径是经典的稀疏路径,且语音信号作为远端输入时相关性较强,
其中最典型最有代表性的两类自适应算法就是:最小均值误差(LMS)算法、递推最小二乘(RLS)算法。[参考]( https://blog.csdn.net/tianwenzhe00/article/details/88192783 )
声学回声消除中子带和块稀疏自适应算法研究_魏丹丹
《车载免提系统降噪算法的研究以及硬件实现》__张雪
标签:函数 指标 初始 提升 技术 fir滤波器 计算 相加 过程
原文地址:https://www.cnblogs.com/LXP-Never/p/11773190.html