标签:dia 通过 文件编辑 通用 size utf-8 中文 影响 data
1.
当用一个软件(比如Windows记事本或Notepad++)打开一个文本文件时,它要做的第一件事是确定这个文本文件究竟是使用哪种编码方式保存的,以便于该软件对其正确解码,否则将显示为乱码。
一般软件确定文本文件编码方式的方法有如下三种:
2.
文件头标识一般指的是字节顺序标记BOM(Byte Order Mark),位于文件的最开始。当打开一个文本文件时,就BOM而言,有如下几种情形:
3.
接下来,是见证诡异怪事的时刻。
当你在简体中文版的Windows记事本里新建一个文件,输入“联通”两个汉字之后,保存为一个txt文件。然后关闭,再次打开该txt文件后,你会发现刚才输入并保存的“联通”两个汉字竟然莫名其妙地消失了,取而代之的是几个乱码。如下图所示。
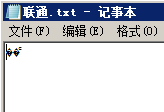
这是为什么呢?难道是微软跟联通有仇吗?
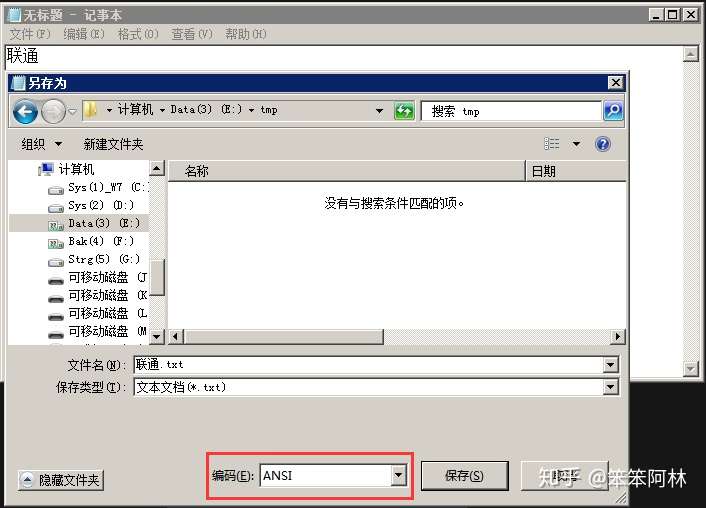
原来,当你用Windows记事本新建一个文本文件时,其编码方式默认为ANSI编码(在简体中文版Windows中实际为GBK编码),没有BOM。
(注:Windows系统中的ANSI编码指的是在区域设置中所设置的系统默认编码方式,在简体中文版Windows系统中指的是GBK,即CP936代码页,具体可参看前文《刨根究底字符编码之七——ANSI编码与代码页》)
(笨笨阿林原创文章,转载请注明出处)
在这种编码方式下,该文本文件仅仅保存了“联通”两个汉字的GB内码的四个字节,如下所示(左边为十六进制,右边为二进制)。
c1 1100 0001
aa 1010 1010
cd 1100 1101
a8 1010 1000
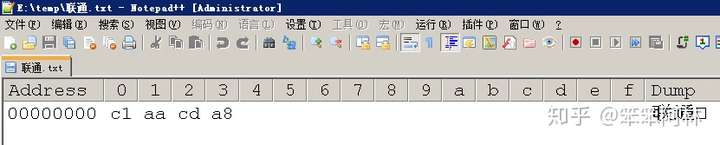
通过Notepad++的HEX-Editor插件可查看内码(十六进制),如下图所示。
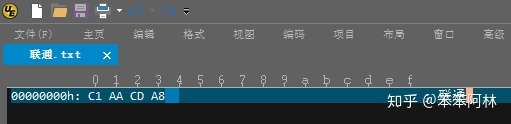
通过UltraEdit的“十六进制编辑”模式也可查看内码(十六进制),如下图所示。
4.
当用记事本再次打开该文本文件时,由于没有BOM,记事本又没有提供显式地提示用户手动选择编码方式的功能,于是就只能隐式地按其推断规则自行推断,推断的结果就是被误认为了这是一个UTF-8编码方式的文件。
为什么会推断错误呢?又为什么会将其编码方式错误地推断为UTF-8呢?
注意,“联通”两个汉字的GB内码,其第一第二个字节的起始部分分别是“110”和“10”,第三第四个字节的起始部分也分别是“110”和“10”,这刚好符合了UTF-8编码方式里的两码元序列的编码算法规则(即与UTF-8的两码元序列“110xxxxx 10xxxxxx”中的前缀码“110”和“10”刚好是完全一致的;详见本系列文章中《刨根究底字符编码之十二——UTF-8究竟是怎么编码的》一文的介绍)。
让我们按照UTF-8的编码算法规则,将第一个字节的前缀码110去掉,得到“00001”,将第二个字节的前缀码10去掉,得到“101010”,将两者组合在一起,得到“00001101010”,再去掉多余的前导的0,就得到了“0110 1010",这正好是Unicode字符集里的U+006A,也就是小写字母“j”的码点值。
同理,之后的第三个字节与第四个字节按同样的方法用UTF-8解码之后正好是Unicode字符集里的U+0368,这个字符为“?”(抱歉,这里的左双引号貌似被这个字符所影响,看起来像是半角左双引号,而无法正常显示为全角左双引号),很像是上标的一个小c,这应该是个组合字符(组合字符是Unicode字符集中的一种特殊字符,必须与其他字符组合在一起以形成一个新字符,一般不单独使用,可参看本系列文章前面相关文章中的介绍)。
这就是只有“联通”两个汉字的文本文件没有办法在记事本里被正确解码显示的原因。这里要特别说明的是,在记事本里打开时显示的不是“j”和“?”,而是显示为了“???”(注意右上角是“?”)。
而用UltraEdit打开,如果在设置中选择了“自动检测UTF-8文件”,显示的是“j”和“?”组合在一起的字符“j?”。注意这个字符不是小写字母“j”,而是小写字母“j”上面的点变成了一个上标的小c,因为U+0368这个字符“?”应该是个组合字符,与其前面的小写字母“j”组合在一起而形成了一个新字符——j?(再次提醒注意小写字母“j”上面的点变成了“c”)。
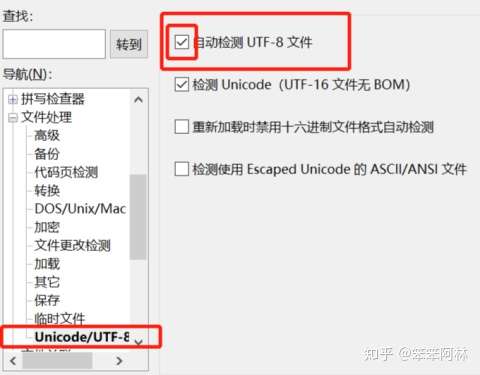 (注意:在UltraEdit的早期版本中,没有“自动检测UTF-8文件”这一选项)
(注意:在UltraEdit的早期版本中,没有“自动检测UTF-8文件”这一选项)
5.
这里还有一个问题:既然已经推断为了UTF-8,那为什么Windows记事本还是将前两个字节,亦即原本为“联”字的GB内码的那两个字节,显示为了“??”这样的乱码,而不是显示为小写字母“j”呢?
我想主要是因为小写字母“j”属于ASCII字符,在UTF-8编码中ASCII字符属于单字节编码,出现在双字节编码中是非正常的,因而被Windows记事本认为是错误编码,而UltraEdit则作了容错处理,仍然将其解读为了小写字母“j”。
而后两个字节,亦即原本为“通”字的GB内码的那两个字节,之所以Windows记事本将其按UTF-8编码的规则解读为了字符“?”,那是因为字符“?”的UTF-8编码正好就是双字节编码,因此按UTF-8编码的规则去解读的话不属于错误。
(笨笨阿林原创文章,转载请注明出处)
6.
其实,用记事本默认的编码方式(ANSI)分别单独保存“联”字和“通”字为两个独立的txt文件,则:
1) 再用记事本打开时,“联”字显示的是“??”,“通”字显示的是“?”;
2) 用UltraEdit打开时,
(1) 如果选择了“自动检测UTF-8文件”,“联”字显示的是小写字母“j”,“通”字显示的“?”(不过看不清,我开始还以为是个空格);
(2) 如果没有选择“自动检测UTF-8文件”,“联”字和“通”字均能正常显示(说明这种情况下UltraEdit正确地推断出了编码方式为GBK,从这一点来看,UltraEdit比Windows记事本要强);
3) 用NotePad++打开时,
(1) 如果在“格式”中选择的是“以ANSI格式编码”(亦即显式地手动选择了正确的编码方式),“联”字和“通”字均能正常显示;
(2) 如果编码方式选择的是UTF-8、UTF-8无BOM、UCS-2 Big Endian或UCS-2 Little Endian时,则“联”字均显示为“xC1xAA”(有意思的是,直接复制“xC1xAA”然后粘贴到Word里,则显示为了小写字母“j”),“通”字均显示为“?”。
而如果是用记事本默认的编码方式(ANSI)保存“联通通信”四个字,则用记事本、UltraEdit(即便选择的是“自动检测UTF-8文件”的情况下)打开后都可正常显示。
这充分说明,Windows记事本在文件头没有BOM的情况下,只能自行推断,由于“联通”两个汉字保存为ANSI编码方式时,内码只有四个字节,在信息不够充足的情况下(尤其是其内码又刚好符合了UTF-8的编码算法规则),于是被错误地推断为了UTF-8编码方式;当以ANSI编码方式保存的是“联通通信”四个汉字时,内码有八个字节,这时信息较为充足,因此被正确地推断为了ANSI编码方式(在简体中文版Windows中ANSI编码默认为GBK编码)。
7.
上面分析的是Windows系统中采用ANSI编码时没有添加BOM的情况。那么,对于采用非ANSI编码时添加了BOM的情况,是否就万事大吉了呢?其实,添加BOM来标记字符编码表面看起来貌似不错,但实际上经常会带来麻烦,因为它和很多协议、规范并不兼容。
Windows里的软件在采用非ANSI编码时,即便对于根本不存在字节序问题的UTF-8编码默认也会添加BOM(详见之前文章《刨根究底字符编码之十一——UTF-8编码方式与字节序标记》的介绍),而像Unix、Linux、Mac OS等*nix系统对于UTF-8编码都默认不添加BOM。
既然*nix系统都可以不添加BOM,那为什么Windows系统却非要添加BOM呢?这很可能是因为Windows系统有大量普通用户使用,在必须兼容传统ANSI编码的情况下,从用户体验角度考虑而没有采用显式地要求用户手动选择字符编码方式的做法,因此特别依赖于通过BOM来防止隐式地自行推断字符编码方式而出错。
微软这种为了照顾广大普通用户而从用户体验角度出发“好心办坏事”的例子其实还有很多。
8.
因此,在Windows系统中,尽量不要使用记事本来打开并编辑文本文件,尤其是作为程序员,应使用Notepad++或UltraEdit等更为专业的文本文件编辑软件。
这一方面是可以避免出现上述这样的“诡异”错误,另一方面也是为了避免Windows记事本“多此一举”地添加BOM(详见下面附文中的解释),从而给在与其他系统(比如*nix系统)交流时带来不必要的麻烦。
附:Windows记事本中对常用编码方式自行其是的“奇葩”命名
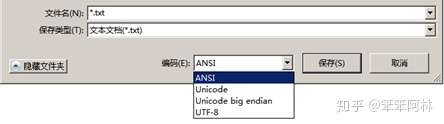
Windows记事本中,对常用编码方式的命名非常“奇葩”,微软这种自行其是的非标准命名,乍一看令人费解,现解释如下。
1) ANSI指的是对应当前系统区域设置(即系统locale)中的默认ANSI编码,不带BOM。在简体中文版Windows系统中默认ANSI编码指的就是GBK编码,即CP936,具体可参看前文《刨根究底字符编码之七——ANSI编码与代码页》。
2) Unicode指的是带有BOM的小端序UTF-16(即UTF-16LE with BOM)。
3) Unicode big endian指的是带有BOM的大端序UTF-16(即UTF-16BE with BOM)。
4) UTF-8指的是带有BOM的UTF-8(即UTF-8 with BOM)。UTF-8编码方式实际上并不存在字节序的问题,之所以仍然“多此一举”地添加BOM,应该是由于要兼容不添加BOM的ANSI编码,从用户体验角度考虑,避免用户显式地手动选择编码方式。
(注:如果UTF-8编码不添加BOM,则有两种不添加BOM的编码方式,从而导致隐式地自行推断编码方式更容易出错,上文所介绍的对“联通”推断出错即是明证。当然反过来也说明了Windows记事本对于不添加BOM的UTF-8编码其实同样是支持的,而并非简单粗暴地直接提示错误,这应该是为了兼容*nix系统不添加BOM的做法而不得不采取的策略。只是这样一来,就很难避免陷入左右为难的困境。)
(笨笨阿林原创文章,转载请注明出处)
(未完待续)
https://zhuanlan.zhihu.com/p/86871840
标签:dia 通过 文件编辑 通用 size utf-8 中文 影响 data
原文地址:https://www.cnblogs.com/findumars/p/11785075.html