标签:chinese text log 形式 href doc title ansi 设置
[========]
排序规则会作用到 order、where、group 语句中。
默认中文 Windows 系统中安装的数据库使用的排序规则为:Chinese_PRC_CI_AS
| 选项 | 描述 |
|---|---|
区分大小写 (_CS) |
区分大写字母和小写字母。 如果选择此项,排序时小写字母将在其对应的大写字母之前。 如果未选择此选项,排序规则将不区分大小写。 即 SQL Server 在排序时将大写字母和小写字母视为相同。 通过指定 _CI,可以显式选择不区分大小写。 |
区分重音 (_AS) |
区分重音字符和非重音字符。 例如,“a”和“?”视为不同字符。 如果未选择此选项,则排序规则将不区分重音。 即 SQL Server 在排序时将字母的重音形式和非重音形式视为相同。 通过指定 _AI,可以显式选择不区分重音。 |
区分全半角 (_WS) |
区分全角字符和半角字符。 如果未选择此选项,SQL Server 会在排序时将同一字符的全角和半角形式视为相同。 省略此选项是指定不区分全半角的唯一方法。 |
参考:
排序规则和 Unicode 支持
深入SQL Server 排序规则的原理
表结构如下:
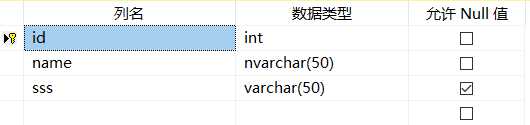
排序规则:
数据:
id,name,sss
1,123aaa啊,啊
2,123aaa啊(),啊aaa()
3,123aaa啊(),啊aaa()
4,123AAA啊(),啊AAA()查询语句:
select * from dbo.Table_1
where name = '123aaa啊()'
select * from dbo.Table_1
where sss = '啊aaa()'输出结果:

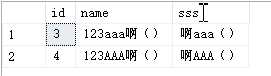
排序规则级别:
默认服务器排序规则是在 SQL Server 安装过程中设置的,由操作系统 (OS) 区域设置确定的默认排序规则。它将成为系统数据库和所有用户数据库的默认排序规则。
创建或修改数据库时,可使用 CREATE DATABASE 或 ALTER DATABASE 语句的 COLLATE 子句指定默认数据库排序规则。 如果未指定排序规则,将为该数据库分配服务器排序规则。
除非更改服务器的排序规则,否则无法更改系统数据库的排序规则。
可以修改数据库的排序规则:
ALTER DATABASE myDB COLLATE Chinese_PRC_CS_AS_WS;重要:更改数据库级排序规则不会影响现有列级排序规则或表达式级排序规则。
当创建或更改表时,可使用 COLLATE 子句指定每个字符串列的排序规则。 如果不指定排序规则,将为列分配数据库的默认排序规则。
可使用如下的 ALTER TABLE 语句更改列的排序规则:
ALTER TABLE myTable ALTER COLUMN mycol NVARCHAR(10) COLLATE Chinese_PRC_CS_AS_WS;查询条件后加 COLLATE语句,比如上面的第二个查询,这样只会查到一条结果。
select * from dbo.Table_1
where sss = '啊aaa()' collate Chinese_PRC_CS_AS_WS请使用 Unicode 数据类型(nchar 、nvarchar 和 ntext ),而不是非 Unicode 数据类型(char 、varchar 和 text )。
Unicode 是一种将码位映射到字符的标准。由于它旨在涵盖全球所有语言的所有字符,因此无需使用不同代码页来处理不同字符集。支持国际化客户端的数据库应始终使用 Unicode 数据类型,而不应使用非 Unicode 数据类型。
备注
对于 Unicode 数据类型,数据库引擎最多可以使用 UCS-2 表示 65,535 个字符;或者,如果使用了附属字符,则可表示整个 Unicode 范围(?1,114,111 个字符)。 如需详细了解如何启用增补字符,请参阅 补充字符。
二进制排序规则区分大小写。
对于非 Unicode数据类型,数据比较将基于 ANSI 代码页中定义的码位。
对于Unicode数据类型,数据比较将基于 Unicode 码位,不考虑区域设置。由于 Unicode 码位的比较相对简单,因此二进制排序规则有助于提高应用程序性能。
SQL Server 中有两种类型的二进制排序规则:
标签:chinese text log 形式 href doc title ansi 设置
原文地址:https://www.cnblogs.com/jerviscui/p/11791129.html