标签:覆盖 nta 意义 table ip route 现在 原理图 img info
在Docker默认配置下,不同宿主机上的容器通过IP地址是无法相互通信的。
因此社区出现了很多用于解决容器跨主机通信问题的方案。
Flannel 支持三种后端实现:
先以 UDP 模式为例
假设有两台宿主机:
如果 container-1 要和 container-2 通信,那么进程发起的 IP 包的目的地址为 100.96.2.3,该 IP datagram 被 docker0 转发到宿主机,Node-1 根据宿主机的路由表来决定该 IP 包的下一跳 IP 地址。
位于Node-1上的Flannel预先在Node-1上添加一系列路由规则,如下:
# 在Node 1上
$ ip route
default via 10.168.0.1 dev eth0
100.96.0.0/16 dev flannel0 proto kernel scope link src 100.96.1.0
100.96.1.0/24 dev docker0 proto kernel scope link src 100.96.1.1
10.168.0.0/24 dev eth0 proto kernel scope link src 10.168.0.2可以看到,根据该路由表,目的 IP 为 100.96.2.3 的 IP 包会被发送给本机的 flannel0 接口。
这个flannel0接口是一个 TUN 设备(Tunnel 设备)。
在 Linux 中,TUN 设备是一个工作在网络层的虚拟网络设备,该设备的功能是在内核和用户应用进程之间传递 IP 包。这个用户应用进程就是创建了该 TUN 设备的进程,在我们这里当然就是宿主机上的 Flannel 进程。
所以,到这里,容器 container-1 发送的目的地址为 100.96.2.3 的 IP 包就被 Flannel 进程捕获,该 Flannel 进程在宿主机上的名称为 flanneld。
flanneld 需要根据该目的 IP,找到 Node-2 的 IP 地址才能继续进行转发。
这里就需要 Flannel 项目中的另一个非常重要的概念:子网。
在 Flannel 项目中,一台宿主机上的所有容器,都属于该宿主机被分配的一个子网,该子网地址就是该宿主机上 docker0 网桥的入口地址。比如在 Node-1 上,docker0 网桥所代表的子网的网络地址为 100.96.1.0/24,在 Node-2 上,docker0 网桥所代表的子网的网络地址为 100.96.2.0/24。
而这个对应关系是由Flannel项目维护的,所以站在上帝视角的 flanneld 进程通过 IP 包的目的地址就知道了目的 IP 所在的子网地址,它将所有的宿主机和子网地址的对应关系保存在 ETCD 中,就可以通过目的 IP 所在的子网地址找到该子网所在的节点。
$ etcdctl ls /coreos.com/network/subnets
/coreos.com/network/subnets/100.96.1.0-24
/coreos.com/network/subnets/100.96.2.0-24
/coreos.com/network/subnets/100.96.3.0-24上面的指令查看出容器IP和子网的对应关系,100.96.2.3 所在的子网为 100.96.2.0/24
$ etcdctl get /coreos.com/network/subnets/100.96.2.0-24
{"PublicIP":"10.168.0.3"}根据该子网地址,同样可以在 ETCD 中找到对应节点的 IP 地址为 10.168.0.3
在获得这个 IP 地址之后,flanneld 将原来的 IP 包封装进一个目的 IP 为 10.168.0.3 的 UDP 包,然后经过宿主机发送给 Node-2。此时,这个 UDP 包的源地址一定为 Node-1 节点的 IP 地址。当然,作为应用层的 flanneld 进程需要监听一个端口以捕获该 UDP 包中的内容,flanneld 进程的监听端口为 8285
当这个 UDP 包被发送到 Node-2 之后,首先经过 Node-2 上网络栈的层层解封,flanneld 进程将会获得 container-1 发出的 IP 包,然后它将该 IP 包通过 flanel0 接口再次发送给 Node-2 上的网络协议栈,Node-2 上的路由表:
# 在Node 2上
$ ip route
default via 10.168.0.1 dev eth0
100.96.0.0/16 dev flannel0 proto kernel scope link src 100.96.2.0
100.96.2.0/24 dev docker0 proto kernel scope link src 100.96.2.1
10.168.0.0/24 dev eth0 proto kernel scope link src 10.168.0.3Node-2 的网络协议栈将该 IP 包匹配路由规则后,首先通过 docker0 向子网 100.96.2.0/24 上的所有设备发送一个 ARP 请求,获得 100.96.2.3 的对应的 MAC 地址后,将该数据包发送给二层的虚拟交换机 docker0 网桥,docker0 网络将该数据包转发给 container-2 容器,然后 container-2 容器的网络栈层层解封装,将数据最终传递给 container-2 容器中的某个进程。
基本原理图:
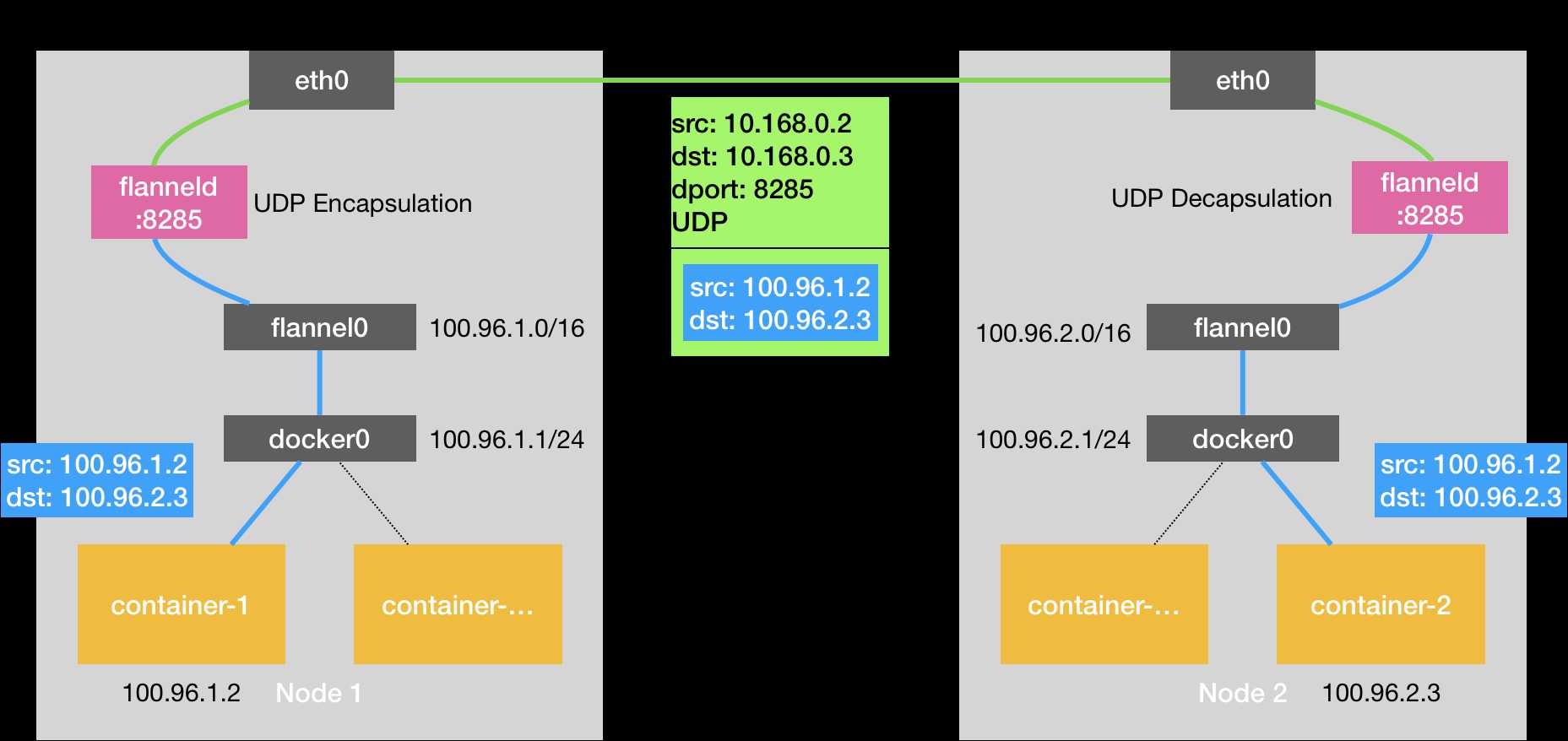
我们可以看到,实际上 Flannel 项目最关键的步骤都是由 flanneld 进程完成的,该进程从 Linux 内核网络协议栈的网络层直接获取 IP 包,然后利用保存在 etcd 中的映射关系,重新将该 IP 包作为数据,封装出一个新的 UDP 包,再将该 UDP 包通过宿主机网络栈发送到目的主机,再考虑数据从 container-1 通过 eth0 发送的过程,仅发送阶段,数据就需要在用户进程和内核之间拷贝三次。
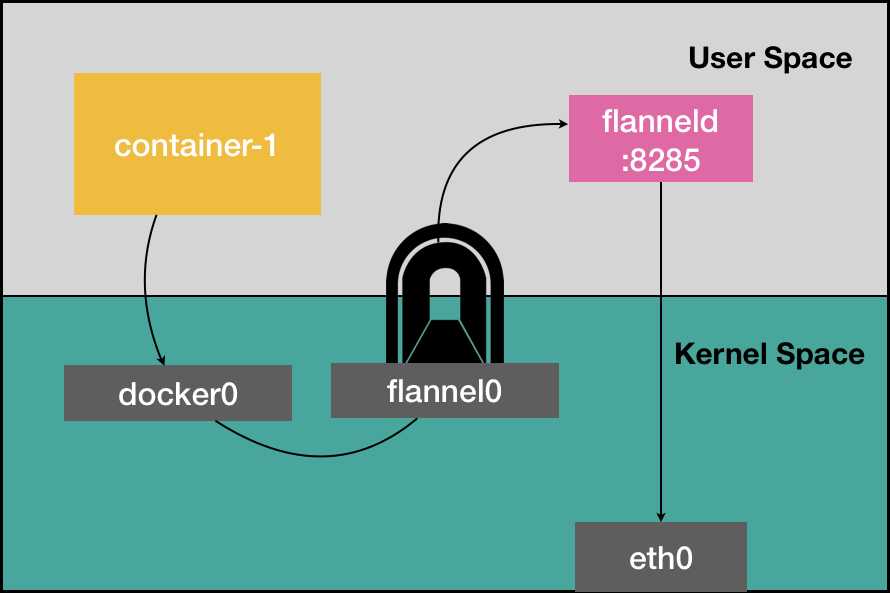
在 Linux 中,用户态操作以及数据在用户态和内核态之间的拷贝的代价是比较高的。这正是 Flannel UDP 模式性能不好的原因。
我们需要减少用户态和内核态的切换次数,并且把核心的处理逻辑都放在内核态进行。
VXLAN:Virtual Extensible LAN(虚拟可扩展局域网),是Linux内核中支持的一种网络虚拟化技术。
其基本思想是在现有的三层网络之上,“覆盖”一层虚拟的、由内核中的VXLAN模块维护的二层网络,使得连接在这个二层网络上的所有设备(网络适配器)可以像在同一个LAN中那样自由通信。
VETP设备,同时具有IP地址也有MAC地址,可以被理解成一个虚拟网络适配器。VETP设备被连接到我们前述的虚拟的二层网络之上。
和 UDP 模式一样,容器内的进程通过 ARP 获得连接在docker0网桥上的VETP设备flannel.1的MAC地址,然后将容器内的Inner IP datagram封装进一个二层数据帧,docker0将该数据帧转发到flannel.1接口。
flannel.1收到该二层数据帧之后,通过Node-1的网络协议栈,将该数据帧解封,Node-1得到Inner IP datagram。同样,Node-1 上的 flannel 进程会在 Node-2 启动并且加入 Flannel 网络之后,在网络内所有节点上添加一条如下的路由规则:
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
...
10.1.16.0 10.1.16.0 255.255.255.0 UG 0 0 0 flannel.1对照该规则,目的地址为 10.1.16.3 的 IP 数据包应该通过接口 flannel.1(源VETP设备) 发往网关 10.1.16.0,该目的网关正是 Node-2 的 flannel.1(目的VETP设备) 接口的 IP 地址,同时,在Node-2启动并且加入Flannel网络时,我们在Node-1上添加一条ARP table entry如下:
# 在Node 1上
$ ip neigh show dev flannel.1
10.1.16.0 lladdr 5e:f8:4f:00:e3:37 PERMANENT这样我们就知道了目的VETP设备的MAC地址为5e:f8:4f:00:e3:37,IP地址为10.1.16.0。有了这个MAC地址,我们可以构建一个二层数据帧,目的MAC地址为5e:f8:4f:00:e3:37,其中IP datagram 中的目的IP 为10.1.16.0。

到这一步,根据计算机网络的知识。我们已经预设Node-1和Node-2上的VETP设备(理解为网络适配器)都“插”在了这个虚拟二层网络VXLAN之上,那么我们通过这个二层数据包就应当能够完成链路层的工作,目的VETP设备就可以获得该二层数据包。
至于该二层数据包是如何通过宿主机,利用实际网络进行传送的,则是内核中的VXLAN模块完成的。
我们前面所使用的所有的IP地址以及MAC地址,实际上对于宿主机网络来说并没有什么意义。因为这些设备都是“虚拟的”。
将前面得到的二层数据帧称为“内部数据帧”。所以我们需要将内部数据帧,作为数据,封装进UDP包,在真实宿主机网络上进行传输。
Linux内核会在“内部数据帧”之前田间一个特殊的VXLAN头,表示该数据是一个VXLAN要使用的数据帧,这样当目的主机网络栈进行解封的时候,就可以将该数据帧传递给它自己的VXLAN。
然后,Linux内核会将该数据帧封装进一个UDP包里面。
我们现在知道“虚拟的”VXLAN接口的MAC地址,还需要目的主机真实的IP地址才能继续。
flannel进程预先为我们维护了这个映射关系
# 在Node 1上,使用“目的VTEP设备”的MAC地址进行查询
$ bridge fdb show flannel.1 | grep 5e:f8:4f:00:e3:37
5e:f8:4f:00:e3:37 dev flannel.1 dst 10.168.0.3 self permanent通过FDB转发数据库,我们可以查询到,目的主机的IP地址为10.168.0.3。接下来的流程就是正常的、宿主机网络上的封包工作。

当上述“外部数据帧”通过宿主机网络传递到目的主机的网络适配器之后,Node-2的内核网络栈将数据包逐步解封,一直到内核中的UDP模块获取到VXLAN头,根据其中的信息,决定将剩余数据帧转发给Node-2上的VETP设备,该设备(虚拟网络适配器)解封,获得 Inner IP datagram,然后根据其中的IP地址,通过ARP获得目的容器的eth0的MAC地址,再利用docker0进行转发,完成最后的步骤。
[Kubernetes][Kubernetes容器网络2]深入解析容器跨主机网络
标签:覆盖 nta 意义 table ip route 现在 原理图 img info
原文地址:https://www.cnblogs.com/hezhiqiangTS/p/11791244.html