标签:led 复合 自动更新 图片 asp 基础 快速 定位 存储
索引的简介:
索引分为聚集索引和非聚集索引,数据库中的索引类似于一本书的目录,在一本书中通过目录可以快速找到你想要的信息,而不需要读完全书。
索引主要目的是提高了SQL Server系统的性能,加快数据的查询速度与减少系统的响应时间 。
但是索引对于提高查询性能也不是万能的,也不是建立越多的索引就越好。索引建少了,用 WHERE 子句找数据效率低,不利于查找数据。索引建多了,不利于新增、修改和删除等操作,因为做这些操作时,SQL SERVER 除了要更新数据表本身,还要连带立即更新所有的相关索引,而且过多的索引也会浪费硬盘空间。
索引的分类:
索引就类似于中文字典前面的目录,按照拼音或部首都可以很快的定位到所要查找的字。
唯一索引(UNIQUE):每一行的索引值都是唯一的(创建了唯一约束,系统将自动创建唯一索引)
主键索引:当创建表时指定的主键列,会自动创建主键索引,并且拥有唯一的特性。
聚集索引(CLUSTERED):聚集索引就相当于使用字典的拼音查找,因为聚集索引存储记录是物理上连续存在的,即拼音 a 过了后面肯定是 b 一样。
非聚集索引(NONCLUSTERED):非聚集索引就相当于使用字典的部首查找,非聚集索引是逻辑上的连续,物理存储并不连续。
PS:聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个。
什么情况下使用索引:
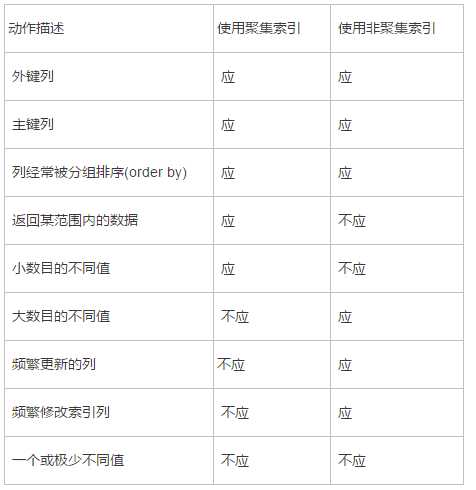
语法:

CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name
ON <object> ( column_name [ ASC | DESC ] [ ,...n ] )
[ WITH <backward_compatible_index_option> [ ,...n ] ]
[ ON { filegroup_name | "default" } ]
<object> ::=
{
[ database_name. [ owner_name ] . | owner_name. ]
table_or_view_name
}
<backward_compatible_index_option> ::=
{
PAD_INDEX
| FILLFACTOR = fillfactor
| SORT_IN_TEMPDB
| IGNORE_DUP_KEY
| STATISTICS_NORECOMPUTE
| DROP_EXISTING
}
参数:
UNIQUE:为表或视图创建唯一索引。 唯一索引不允许两行具有相同的索引键值。 视图的聚集索引必须唯一。如果要建唯一索引的列有重复值,必须先删除重复值。
CLUSTERED:表示指定创建的索引为聚集索引。创建索引时,键值的逻辑顺序决定表中对应行的物理顺序。 聚集索引的底层(或称叶级别)包含该表的实际数据行。
NONCLUSTERED:表示指定创建的索引为非聚集索引。创建一个指定表的逻辑排序的索引。 对于非聚集索引,数据行的物理排序独立于索引排序。
index_name:表示指定所创建的索引的名称。
database_name:表示指定的数据库的名称。
owner_name:表示指定所有者。
table:表示指定创建索引的表的名称。
view:表示指定创建索引的视图的名称。
column:索引所基于的一列或多列。 指定两个或多个列名,可为指定列的组合值创建组合索引。
[ ASC | DESC]:表示指定特定索引列的升序或降序排序方向。 默认值为 ASC。
on filegroup_name:为指定文件组创建指定索引。 如果未指定位置且表或视图尚未分区,则索引将与基础表或视图使用相同的文件组。 该文件组必须已存在。
on default:为默认文件组创建指定索引。
PAD_INDEX = {ON |OFF }:指定是否索引填充。默认为 OFF。
ON 通过指定的可用空间的百分比fillfactor应用于索引中间级别页。
OFF 或 fillfactor 未指定,考虑到中间级页上的键集,将中间级页填充到接近其容量的程度,以留出足够的空间,使之至少能够容纳索引的最大的一行。
PAD_INDEX 选项只有在指定了 FILLFACTOR 时才有用,因为 PAD_INDEX 使用由 FILLFACTOR 指定的百分比。
FILLFACTOR = fillfactor:用于指定在创建索引时,每个索引页的数据占索引页大小的百分比,fillfactor 的值为1到100。
SORT_IN_TEMPDB = {ON |OFF }:用于指定创建索引时的中间排序结果将存储在 tempdb 数据库中。 默认为 OFF。
ON 用于生成索引的中间排序结果存储在tempdb。 这可能会降低仅当创建索引所需的时间tempdb位于不同的与用户数据库的磁盘集。
OFF 中间排序结果与索引存储在同一数据库中。
IGNORE_DUP_KEY = {ON |OFF }:指定在插入操作尝试向唯一索引插入重复键值时的错误响应。默认为 OFF。
ON 向唯一索引插入重复键值时将出现警告消息。 只有违反唯一性约束的行才会失败。
OFF 向唯一索引插入重复键值时将出现错误消息。 整个 INSERT 操作将被回滚。
STATISTICS_NORECOMPUTE = {ON |OFF}:用于指定过期的索引统计是否自动重新计算。 默认为 OFF。
ON 不会自动重新计算过时的统计信息。
OFF 启用统计信息自动更新功能。
DROP_EXISTING = {ON |OFF }:表示如果这个索引还在表上就 drop 掉然后在 create 一个新的。 默认为 OFF。
ON 指定要删除并重新生成现有索引,其必须具有相同名称作为参数 index_name。
OFF 指定不删除和重新生成现有的索引。 如果指定的索引名称已经存在,SQL Server 将显示一个错误。
ONLINE = {ON |OFF}:表示建立索引时是否允许正常访问,即是否对表进行锁定。默认为 OFF。
ON 它将强制表对于一般的访问保持有效,并且不创建任何阻止用户使用索引和/表的锁。
OFF 对索引操作将对表进行表锁,以便对表进行完全和有效的访问。
例子:
创建唯一聚集索引:
-- 创建唯一聚集索引
create unique clustered --表示创建唯一聚集索引
index UQ_Clu_StuNo --索引名称
on Student(S_StuNo) --数据表名称(建立索引的列名)
with
(
pad_index=on, --表示使用填充
fillfactor=50, --表示填充因子为50%
ignore_dup_key=on, --表示向唯一索引插入重复值会忽略重复值
statistics_norecompute=off --表示启用统计信息自动更新功能
)
创建唯一非聚集索引:
-- 创建唯一非聚集索引
create unique nonclustered --表示创建唯一非聚集索引
index UQ_NonClu_StuNo --索引名称
on Student(S_StuNo) --数据表名称(建立索引的列名)
with
(
pad_index=on, --表示使用填充
fillfactor=50, --表示填充因子为50%
ignore_dup_key=on, --表示向唯一索引插入重复值会忽略重复值
statistics_norecompute=off --表示启用统计信息自动更新功能
)
--创建聚集索引 create clustered index Clu_Index on Student(S_StuNo) with (drop_existing=on) --创建非聚集索引 create nonclustered index NonClu_Index on Student(S_StuNo) with (drop_existing=on) --创建唯一索引 create unique index NonClu_Index on Student(S_StuNo) with (drop_existing=on)
PS:当 create index 时,如果未指定 clustered 和 nonclustered,那么默认为 nonclustered。
创建非聚集复合索引:
--创建非聚集复合索引 create nonclustered index Index_StuNo_SName on Student(S_StuNo,S_Name) with(drop_existing=on)
--创建非聚集复合索引,未指定默认为非聚集索引 create index Index_StuNo_SName on Student(S_StuNo,S_Name) with(drop_existing=on)
在 CREATE INDEX 语句中使用 INCLUDE 子句,可以在创建索引时定义包含的非键列(即覆盖索引),其语法结构如下:
CREATE NONCLUSTERED INDEX 索引名
ON { 表名| 视图名 } ( 列名 [ ASC | DESC ] [ ,...n ] )
INCLUDE (<列名1>, <列名2>, [,… n])
--创建非聚集覆盖索引 create nonclustered index NonClu_Index on Student(S_StuNo) include (S_Name,S_Height) with(drop_existing=on) --创建非聚集覆盖索引,未指定默认为非聚集索引 create index NonClu_Index on Student(S_StuNo) include (S_Name,S_Height) with(drop_existing=on)
PS:聚集索引不能创建包含非键列的索引。
创建筛选索引:
--创建非聚集筛选索引 create nonclustered index Index_StuNo_SName on Student(S_StuNo) where S_StuNo >= 001 and S_StuNo <= 020 with(drop_existing=on) --创建非聚集筛选索引,未指定默认为非聚集索引 create index Index_StuNo_SName on Student(S_StuNo) where S_StuNo >= 001 and S_StuNo <= 020 with(drop_existing=on)
修改索引:
--修改索引语法
ALTER INDEX { 索引名| ALL }
ON <表名|视图名>
{ REBUILD | DISABLE | REORGANIZE }[ ; ]
REBUILD:表示指定重新生成索引。
DISABLE:表示指定将索引标记为已禁用。
REORGANIZE:表示指定将重新组织的索引叶级。
--禁用名为 NonClu_Index 的索引 alter index NonClu_Index on Student disable
删除和查看索引:
--查看指定表 Student 中的索引 exec sp_helpindex Student --删除指定表 Student 中名为 Index_StuNo_SName 的索引 drop index Student.Index_StuNo_SName --检查表 Student 中索引 UQ_S_StuNo 的碎片信息 dbcc showcontig(Student,UQ_S_StuNo) --整理 Test 数据库中表 Student 的索引 UQ_S_StuNo 的碎片 dbcc indexdefrag(Test,Student,UQ_S_StuNo) --更新表 Student 中的全部索引的统计信息 update statistics Student
索引定义原则:
避免对经常更新的表进行过多的索引,并且索引中的列尽可能少。而对经常用于查询的字段应该创建索引,但要避免添加不必要的字段。
在条件表达式中经常用到的、不同值较多的列上建立索引,在不同值少的列上不要建立索引。
在频繁进行排序或分组(即进行 GROUP BY 或 ORDER BY 操作)的列上建立索引,如果待排序的列有多个,可以在这些列上建立组合索引。
在选择索引键时,尽可能采用小数据类型的列作为键以使每个索引页能容纳尽可能多的索引键和指针,通过这种方式,可使一个查询必需遍历的索引页面降低到最小,此外,尽可能的使用整数做为键值,因为整数的访问速度最快。
参考:
http://www.cnblogs.com/knowledgesea/p/3672099.html
https://msdn.microsoft.com/zh-cn/library/ms188783.aspx
标签:led 复合 自动更新 图片 asp 基础 快速 定位 存储
原文地址:https://www.cnblogs.com/liujianshe1990-/p/11791973.html