标签:转换 取数 dom 代码 产生 提取 文件的 重要 list
文件操作有三种形式:读、写和追加
读模式r特点:(1)只能读,不能写;(2)文件不存在时会报错。
1.1 基础用法
例:读取当前目录下的test.txt文件,该文件如下所示。

f = open("test.txt", "r") print(f.read())
输出:
hello world!
hello python!
解析:
a、用open打开文件,在python3中只有open。python2可以用open和file。关闭文件是close()。一般有开就有关
b、如果在当前目录,可以直接写文件名,否则需添加路径。
c、如果不写 ‘r‘,即写成 f = open(‘books.txt‘),也是默认读模式。
d、read可以将文件所有的内容都读出来
e、另外,有时需要添加解码格式 encoding ,格式为:
f = open(‘books‘,‘r‘,encoding=‘utf-8‘)
1.2 读的方法
# read: 读取文件全部内容 f = open("test.txt", "r") print(f.read()) print("-"*20) f.close()
# readline: 读取一行 f = open("test.txt", "r") print(f.readline()) f.close() print("*"*20) # 可以用循环读取每一行 f = open("test.txt", "r") for line in f: line = line.split("\n")[0] # 转换每行中的换行符 print(line) f.close() print("-"*20)
# readlines: 读取每一行,并且放到一个list里 f = open("test.txt", "r") print(f.readlines()) f.close()
输出结果:
hello world! hello python! -------------------- hello world! ******************** hello world! hello python! -------------------- [‘hello world!\n‘, ‘hello python!‘]
读写模式r+特点:(1)文件不存在时会报错;(2)可以读,也可以写,是覆盖写,会从文件最前面的内容开始覆盖写f = open("test.txt", "r+")
f = open("test.txt", "r+") f.write("HEL") f.seek(0) f.close()
输出:
HELlo world!
hello python!
写模式w特点:(1)只能写,不能读;(2)写的时候会把原来文件的内容清空;(3)当文件不存在时,会创建新文件。
如下,写入‘你好,世界!’时,将原来的内容都清空。
f = open("test.txt", "w") f.write("你好,世界!") f.flush() f.close()
执行代码后的文件内容如下:

f.flush():有时我们用f.write()后,会发现没有写入文件,这是因为内容存在了缓冲区,需要等缓冲区满了之后,再把所有数据写入。此时可以用f.flush()强制把缓冲区里面的数据写到磁盘上。
写读模式w+特点:(1)可以写,也可以读;(2)写的时候会把原来文件的内容清空;(3)当文件不存在时,会创建新文件。
追加模式a特点:(1)不能读;(2)可以写,是追加写,即在原内容末尾添加新内容;(3)当文件不存在时,创建新文件。
f = open("test.txt", "a") f.write("你好,python!") f.flush() f.close()
将‘你好,python’添加到原内容的末尾

追加读a+模式特点:(1)可读可写;(2)写的时候是追加写,即在原内容末尾添加新内容;(3)当文件不存在时,创建新文件。
以上几种模式,可以用下表来总结:
| 读写模式 | 是否可读 | 是否可写 | 文件不存在时 |
| r | 是 | 否 | 报错 |
| r+ | 是 | 是,覆盖写 | 报错 |
| w | 否 | 是,清空原内容 | 创建新文件 |
| w+ | 是 | 是,清空原内容 | 创建新文件 |
| a | 否 | 是,追加写 | 创建新文件 |
| a+ | 是 | 是,追加写 | 创建新文件 |
四、文件指针
文件指针用来记录文件走到哪里。
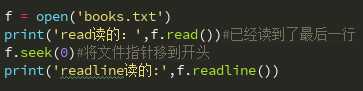
文件指针是很重要的,我们看下面的例子中,read将books.txt的内容全部读了出来,readline则没有读出任何内容。原因是read读完之后,文件指针到了文件的末尾,此时readline接着从这个位置开始读,肯定是没内容的。因此有时需要调整文件指针的位置。


seek可以移动文件指针,移动后只是针对读,用追加模式写的时候,还是在末尾写。
另外,seek(num),这个num指的是字符,不是行。
在上面的代码中,加一句f.seek(0),即可将指针移到文件开头。这次,readline就可以从头开始读了。

五、自动关闭文件
with可以自动关闭文件,用法如下:
with open(‘books.txt‘,‘a+‘) as f:
f.write(‘\n三体‘)
六、文件修改
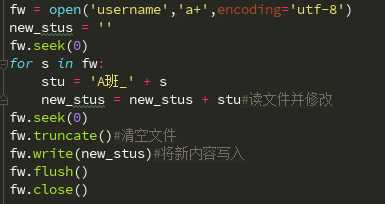
1、简单粗暴直接修改
最简单粗暴的修改文件,步骤是:
(1)打开文件,获取文件内容;
(2)对内容进行修改;
(3)清空原来文件的内容;
(4)把新的内容写进去。
这种方法很简单,下面看一个小例子----文件username里存放了姓名和密码,如下图格式。我们要在所有姓名前加上‘A班_’
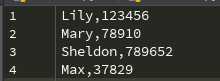
因为‘A班_‘中含有中文,需要叫上encoding=‘utf-8‘,否则会出现乱码。
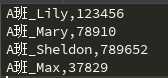
2、备份文件的方法
当文件很大时,刚刚的方法在一次性读取文件内容和写入新内容时,耗时长,占用磁盘空间也较大。
备份文件的方法可以建立一个备份文件,修改一行写一行,具体步骤如下:
(1)打开2个文件,原文件a和备份文件b。如a.txt b.txt.bak
(2)删除a文件,将b文件名改为a文件名
例:将文件words里的“花”改成“flower”


七、小练习
1、产生手机号 前几位一样1861253 后四位随机,写到文件里。
分析:(1)首先要随机产生一些四位数,位数不足的要补0,zfill可以给字符串补0;
(2)需要写到文件里,可以用w或者a模式。文件有打开就要有关闭。

import random
f = open(‘phones.txt‘,‘w‘)
num = int(input(‘请输入你要产生的手机号个数:‘))
for i in range(num):
start = ‘1861253‘
random_num = str(random.randint(1,9999))
new_num = random_num .zfill(4) #不够4位就补0,仅对字符串可以使用
phone_num = start + new_num
f.write(phone_num+‘\n‘)
f.close()
2、监控服务器日志,如果ip出现的次数大于50次,就把该ip加入黑名单。日志文件的格式如下图

分析:(1)首先,我们应该从日志里提取出所有ip。根据日志文件的格式,我们可以看到每一行的开头是ip,那么可以一行一行的读取数据,然后用空格进行分割,则该行第一个元素就是ip。(2)然后需要统计每一个ip出现的次数,最直接想到的就是count。(3)找到出现次数大于50次的ip,打印出来。
import time
point = 0#记录文件指针的位置
while True:
f = open(r‘D:\access.log‘,encoding=‘utf-8‘)
all_ips = []
f.seek(point)#移动文件指针,本次接着上次的位置继续读
for line in f:
ip = line.split()[0]#每行第一个元素为IP
all_ips.append(ip)#存放所有的ip,不去重
point = f.tell()# 获取文件当前指针位置
ips_set = set(all_ips)#去重
for i in ips_set:
if all_ips.count(i)>50:
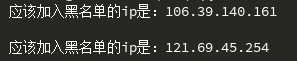
print(‘应该加入黑名单的ip是:%s\n‘%i)
time.sleep(60)#暂停60s
运行结果为:
标签:转换 取数 dom 代码 产生 提取 文件的 重要 list
原文地址:https://www.cnblogs.com/testlearn/p/11793923.html