标签:误差 水平线 根据 loss hot 权重 描述 stp resize
Lanenet
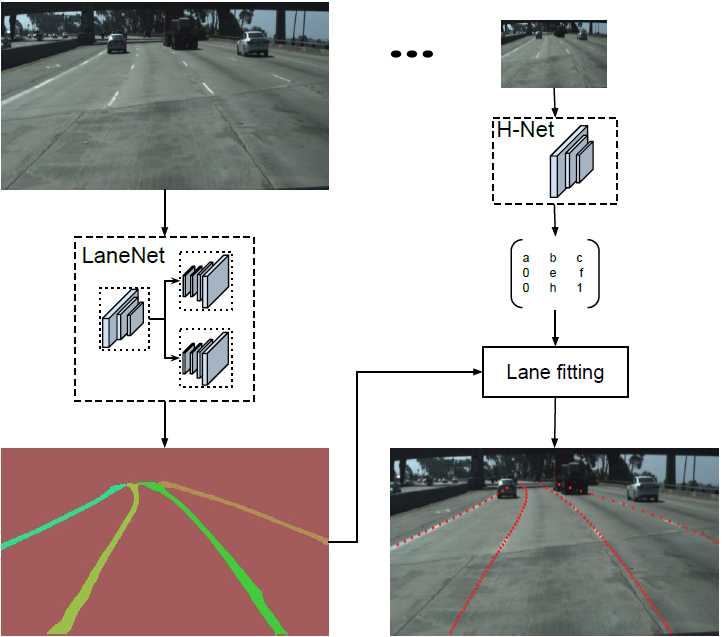
一个端到端的网络,包含Lanenet+HNet两个网络模型,其中,Lanenet完成对车道线的实例分割,HNet是一个小网络结构,负责预测变换矩阵H,使用转换矩阵H对同属一条车道线的所有像素点进行重新建模
将语义分割和对像素进行向量表示结合起来的多任务模型,最近利用聚类完成对车道线的实例分割。
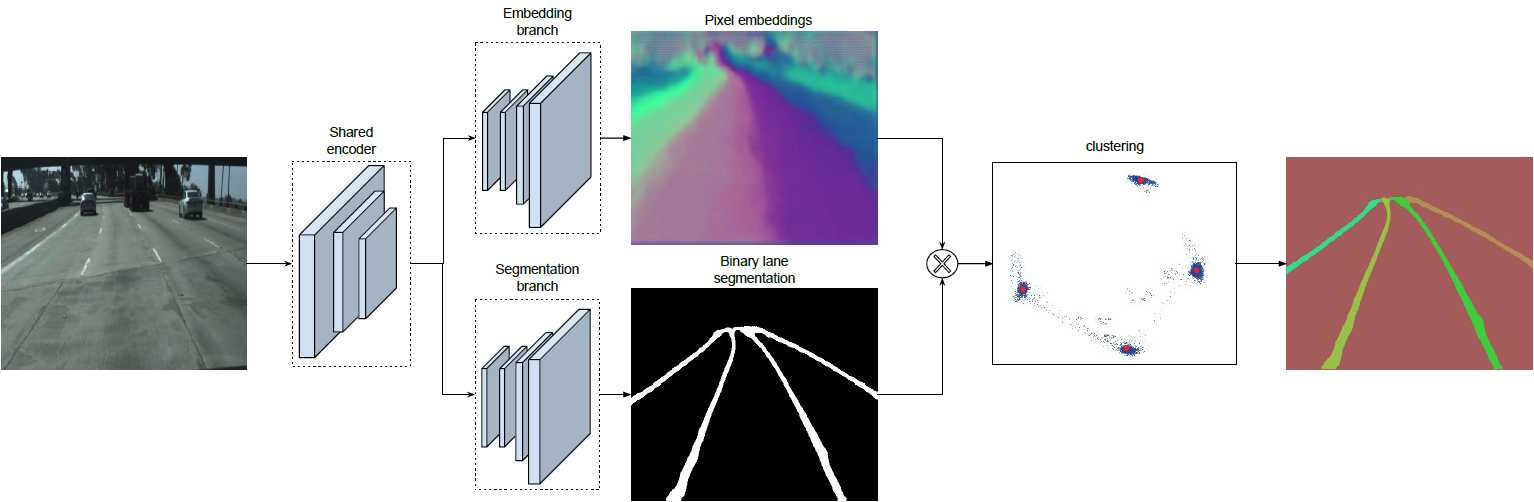
将实例分割任务拆解成语义分割和聚类,分割分支负责对输入图像进行语义分割(对像素进行二分类,判断像素属于车道线还是背景),嵌入分支对像素进行嵌入式表示,可将分割后得的车道线分离成不同的车道实例,训练得到的向量用于聚类。最后将两个分支的结果利用MeanShift算法进行聚类,得到实例分割的结果。
当得到车道实例后,就需要对每条线做参数描述,曲线拟合算法作为这个参数描述,常用的拟合算法有三次多项式,样条曲线,回旋曲线。为了提高拟合质量,通常将图像转到鸟瞰图后做拟合,再逆变换到原图。
1.语义分割
训练输出得到一个二值化的分割图,白色代表车道线,黑色代表背景。
设计模型时主要,主要考虑了以下两点:
1)在构建Label标签时,为了处理遮挡问题,将可能属于每条车道线对应的像素都连成线。好处是即使车道线被遮挡了,网络仍能预测车道位置。
2)Loss使用交叉熵,为了解决样本分布不均衡问题(属于车道线的像素远少于属于背景的像素),使用Bounded Inverse class weight 对 Loss进行加权:
Wclass=1ln(c + p(class))
其中,p为对应类别在总体样本中出现的概率,c是超参数。
 View Code
View Code 2.实例分割
当分割分支识别得到车道后,为了分离车道像素(就是为了知道哪些像素归这条,哪些归那条车道),我们训练了一个车道instance embedding分支网络,我们用基于one-shot的方法做距离度量学习,该方法易于集成在标准的前馈神经网络中,可用于实时处理。利用聚类损失函数,instance embedding分支训练后输出一个车道线像素点距离,归属同一车道的像素点距离近,反之远,基于这个策略,可聚类得到各条车道线.
大致原理如下:
有两股力在做较量,一股是方差项,主要是将每个embedding往某条车道线的均值方向拉(激活拉这个动作的前提是embedding太远了,远于阈值δv就开始pull),另一股是距离项,就是使两个类别的车道线越远越好(激活推这个动作的前提是两条车道线聚类中心的距离太近啦,近于阈值δd就push)。最后这个总损失函数L的公式如下:
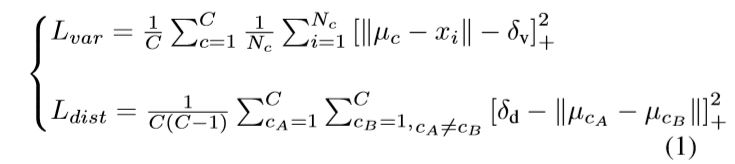
View Code
聚类
聚类可以看做是后处理,前一步的Embedding_branch 已经为聚类提供好了特征向量,利用这些特征向量可以用任何聚类算法完成实例分割的目标。
终止聚类的条件是:车道聚类(即各车道线间间距)中心间距离>δd,每个类(每条车道线)中包含的车道线像素离该车道线距离<δv 设置 δd > 6δv为迭代终止条件,使上述的loss做迭代。
网络架构
基于ENet的encoder-deconder模型,ENet由5个stage组成,其中stage2和stage3基本相同,stage1,2,3属于encoder,stage4,5属于decoder。
Lanenet网络共享前面两个stage1,2,并将stage3和后面的decoder层作为各自的分支进行训练。其中语义分割分支输出单通道的图像W*H*2。embedding分支输出N通道的图像W*H*N。两个分支的loss权重相同。

用H-NET做车道线曲线拟合
lanenet网络输出的是每条车道线的像素集合。常规处理是将图像转为鸟瞰图,这么做的目的就是为了做曲线拟合时弯曲的车道能用2次或3次多项式拟合(拟合起来简单些)。但变换矩阵H只被计算一次,所有图片使用相同变换矩阵,导致地平面(山地,丘陵)变化下的误差。
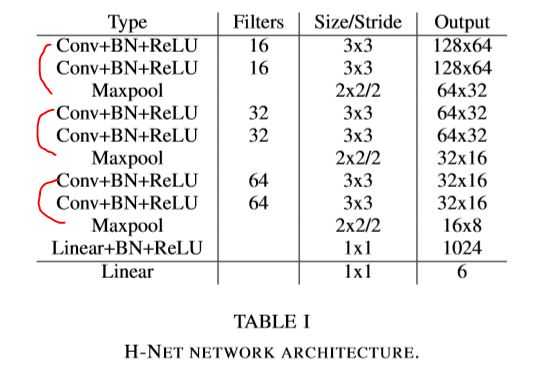
为了解决这个问题,需要训练一个可以预测变换矩阵H的神经网络HNet,网络输入是图片,输出是变换矩阵H:
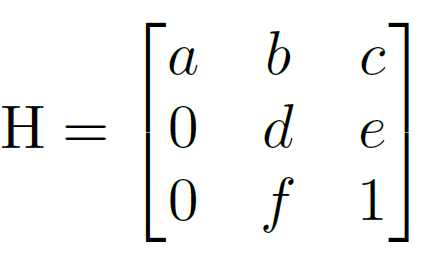
通过置0对转置矩阵进行约束,即水平线在变换下保持水平。(坐标y的变换不受坐标x的影响)
意思就是通过H-Net网络学习得到的变换矩阵参数适用性更好,转置矩阵H只有6个参数,HNet输出一个6维向量,HNet由6层普通卷积网络和一层全连接层构成。
曲线拟合
通过坐标y去重新预测坐标x的过程:
。对于包含N个像素点的车道线,每个像素点pi=[xi,yi,1]T∈Ppi=[xi,yi,1]T∈P, 首先使用 H-Net 的预测输出 H 对其进行坐标变换:
P′=HPP′=HP
w=(YTY)−1YTx′w=(YTY)−1YTx′
x′∗i=αy′2+βy′+γxi′∗=αy′2+βy′+γ
p∗i=H−1p′∗i
拟合函数
Loss=1/N∑Ni=1(x∗i−xi)2
LaneNet
Dataset : Tusimple embedding维度是4(输出4通道),δv=0.5,δd=3,输入图像resize到512x256,采用Adam优化器,batchsize=8,学习率=5e-4;
H-Net
Dataset : Tusimple,3阶多项式,输入图像128x64,Adam优化器,batchsize=10,学习率=5e-5;
评估标准:
accuracy=2/(1/recall+1/precision)
recall=|P1∩G1|/|G1| # 统计GT中车道线分对的概率
precision=|P0∩G0|/|G0| # 统计GT中背景分对的概率
设定 G1 代表 GT二值图里像素值为 1 部分的集合,P1 表示检测结果为 1 的集合。
View Codefp=(|P1|−|P1∩G1|)/|P1| # 统计Pre中的车道线误检率
View Codefn=(|G1|−|P1∩G1|)/|G1| # 统计GT车道线中漏检率
View Code相关试验:
1.替换Backbone为moblilenet_v2
2.调整embedding维度
3.预处理方式调整
4.上采样方式替换
5.学习率衰减方式
6.反卷积卷积核尺寸调整
代码结构:
lanenet_detection
├── config //配置文件
├── data //一些样例图片和曲线拟合参数文件
├── data_provider // 用于加载数据以及制作 tfrecords
├── lanenet_model
│ ├── lanenet.py //网络布局 inference/compute_loss/compute_acc
│ ├── lanenet_front_end.py // backbone 布局
│ ├── lanenet_back_end.py // 网络任务和Loss计算 inference/compute_loss
│ ├── lanenet_discriminative_loss.py //discriminative_loss实现
│ ├── lanenet_postprocess.py // 后处理操作,包括聚类和曲线拟合
├── model //保存模型的目录semantic_segmentation_zoo
├── semantic_segmentation_zoo // backbone 网络定义
│ ├── __init__.py
│ ├── vgg16_based_fcn.py //VGG backbone
│ └─+ mobilenet_v2_based_fcn.py //mobilenet_v2 backbone
│ └── cnn_basenet.py // 基础 block
├── tools //训练、测试主函数
│ ├── train_lanenet.py //训练
│ ├── test_lanenet.py //测试
│ └──+ evaluate_dataset.py // 数据集评测 accuracy
│ └── evaluate_lanenet_on_tusimple.py // 数据集检测结果保存
│ └── evaluate_model_utils.py // 评测相关函数 calculate_model_precision/calculate_model_fp/calculate_model_fn
│ └── generate_tusimple_dataset.py // 原始数据转换格式
├─+ showname.py //模型变量名查看
├─+ change_name.py //模型变量名修改
├─+ freeze_graph.py//生成pb文件
├─+ convert_weights.py//对权重进行转换,为了模型的预训练
└─+ convert_pb.py //生成pb文
语义分割之车道线检测Lanenet(tensorflow版)
标签:误差 水平线 根据 loss hot 权重 描述 stp resize
原文地址:https://www.cnblogs.com/jimchen1218/p/11811958.html