标签:这不 验证 order euc 区域 png 缩减 效率 世界
本文是一篇介绍K近邻数据挖掘算法的文章,而所谓数据挖掘,就是讨论如何在数据中寻找模式的一门学科。
其实人类的科学技术发展的历史,就一直伴随着数据挖掘,人们一直在试图中数据中寻找模式,
接下来的问题就是,如何表示数据模式?
有价值的数据模式能够让我们对新数据做出非凡的预测,表示一个数据模式有两种极端的方法:
两种方法可能都可以做出好的预测,它们的区别在于被挖掘出的模式能否以结构的形式清晰地表现,这个结构是否经得起分析,理由是否充分,能否用来形成未来的决策。
如果模式能够以显而易见的方法获得决策结构,就称为结构模式(structural pattern),换句话说,结构模式能够帮助解释有关数据的一些现象,具备可解释性。
更进一步地,机器学习从数据中挖掘结构模式的过程,称为知识表达,机器学习所能发现的模式有许多不同的表达方式,每一种方式就是一种推断数据输出结构的技术,包括:
了解了来龙去脉的知识脉络之外,我们将视野缩小到”基于实例的机器学习“这个领域内。
在基于实例的学习中,训练样本被一字不差地保存,并且使用一个距离函数来判定训练集中的哪个实例与一个未知的测试实例最靠近。一旦找到最靠近的训练实例,那么最靠近实例所属的类就被预测为测试实例的类。
基于实例的算法,有时也称为基于记忆的学习,它不是明确归纳概率分布或者分界面,而是将新的问题例子与训练过程中见过的例子进行对比,这些见过的例子就在存储器中。
Relevant Link:
《数据挖掘 实用机器学习工具与技术》Ian H.Witten Eibe Frank,Mark A.Hall
我们先来看下面这张图,
假设我们现在的目标是寻找图中离绿色点最近的实例。这个问题的答案似乎是显而易见的,很显然是右下方向的红色三角。
但是我们只要对题目稍加改造,例如将空间维数从2维扩展到100维,图上的点密度增加10倍,这个时候,答案还依然明显吗?显然不是了!
最直观的想法是,我们需要建一张表(table),将图中所有的数据点的坐标都保存起来,例如:
| 点 | x1 | ...... | xn |
| A | 1 | ...... | 2 |
| .. | |||
| N | 5 | ...... | 3 |
这样,每输入一个新的点时,我们就遍历一遍整张表,根据一定的距离函数(例如欧氏距离)找出距离最近的1个或k个实例。
这个场景在现实中是非常常见的需求,例如:
尽管上面描述的查表法非常简单且有效,但是缺点是速度非常慢。这个过程与训练实例的数量成线性关系,换句话说,就是一个单独的预测所花费的时间与训练实例的数量成比例关系。处理整个数据集所花费的时间与训练集实例数量O(train)和测试集实例数量O(test)的乘积成正比。
如何解决这个关键矛盾呢?学者们从数据结构优化上入手,提出了一系列的高效数据结构与搜索算法,它们合称为K近邻算法,K近邻算法要解决的最核心问题就是如何有效寻找到最近邻的实例集,支撑这种搜索的结构就是一种知识表达。我们接下来来讨论它。
K近邻法(k-nearest neighbor KNN)是一种数据驱动(基于实例的算法(Instance-based Algorithms))的分类与回归方法。它属于一种判别模型。
在多分类问题中的k近邻法,k近邻法的输入为实例的特征向量,对应于特征空间的点,输出为实例的类别。
k近邻法假设给定一个训练数据集,其中的实例类别已定,分类时,对新的实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻法不具有显示的学习过程(或者说是一种延迟学习),k近邻法实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”。
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。
更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成正比。
输入训练数据集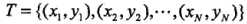 ,其中
,其中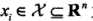 为实例的特征向量,
为实例的特征向量,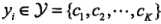 为实例的类别。
为实例的类别。
根据给定的距离度量,在训练集中找出与 x 最邻近的 K(需要人工设定调参) 个点,在由这 K 个点组成的邻域中根据分类决策规则决定 x 的类别 y
K近邻法的特殊情况是k=1的情形,称为最近邻算法,即对于输入的实例点(特征向量)x,最近邻法将训练数据集中与x最邻近的类作为x的类。
Y = P(y | x):这里概率函数P指某种最小化距离判定公式
可以看到,K近邻法没有显示的学习过程,作为判别模型的一种,k近邻法的判别函数的具体形式也不是很明显。
K近邻法使用的模型实际上对应于特征空间的划分,某种意义上来说,k近邻的模型就是样本特征空间本身。
在k近邻法中,当下列基本要素:
确定后,对于任何一个新的输入实例,它所属的类唯一地确定。这相当于根据上述基本要素将特征空间划分为一些子空间,确定子空间里的每个点所属的类。
特征空间中,对每个训练实例点x1,距离该点比其他点更近的所有点组成一个区域,叫作单元(cell)。每个训练实例点拥有一个单元,所有训练实例点的单元构成对特征空间的一个划分:
K近邻很好地体现了判别式模型的思想,k近邻不生成概率分布函数,它只是通过三个基本要素尽可能地“捕捉”训练样本中的概率密度特征。之所以输入样本会被分到不同的类别,其本质就在于在训练样本中存在不均匀的概率密度分布,即某一个区域某一个类别密度占比比其他的类多。
下面我们来具体谈谈K近邻模型的几个基本要素。
K值的选择会对K近邻法的结果产生重大影响。
近似误差和估计误差的核心区别在于是假设临近点的噪音扰动比较多还是远点的噪音扰动比较多。
在实际应用中,K值一般选取一个比较小的数值,即我们基本上认为近邻点的相关性是比较大的,而原点的相关性比较小
在实际项目中,K值的选择和样本中的概率密度分布有关,并没有一个定式的理论告诉我么该选什么样的K值,好在的是这个K值的搜索空间并不是很大,通常我们可以采取一个for循环交叉验证来搜索所有可能的K值,通过重复进行多次实验,每次随机选取不同的train set和validate set,查看KNN模型对train set和validate set的拟合和泛化能力来选择一个最好的K值。
理论上分析:
理论上说,当 k 和实例的数量 n 都变成无穷大,使得 k/n -> 0 时,那么在数据集上产生的误差概率将达到理论上的最小值。
特征空间中两个实例点的距离是两个实例点相似程度的一种数字化度量。
K近邻模型的特征空间一般是n维实数向量空间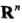 ,计算两个向量之间的距离有很多种方法,注意这不是KNN独有的算法,向量间距离模型是数学中的基础概念:
,计算两个向量之间的距离有很多种方法,注意这不是KNN独有的算法,向量间距离模型是数学中的基础概念:
设特征空间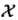 是n维实数向量空间
是n维实数向量空间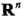 :
:
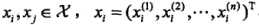 ,
,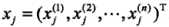
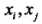 的Lp距离定义为:
的Lp距离定义为:
下图给出了二维空间中p取不同值时,与原点的Lp距离为1(Lp = 1)的点的集合图形
这张图很好地说明了取不同的距离策略对于KNN对于紧邻点的搜索范围是不同的,进而影响随后的判别分类结果
举一个例子说明由不同的距离度量所确定的最近邻点是不同的。已知二维空间的3个点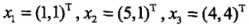 ,我们来对比一下在p取不同的值时,Lp距离下X1的最近邻点
,我们来对比一下在p取不同的值时,Lp距离下X1的最近邻点
| P值 | 和X2距离 | 和X3距离 |
| 1 | 4 | 6 |
| 2 | 4 | 4.24 |
| 3 | 4 | 3.78 |
| 4 | 4 | 3.57 |
可以看到,p = 1/2时,X2是X1的最近邻点;P >= 3,X3是X1的最近邻点。
近邻法中的分类决策规则往往是多数表决,即由输入实例的k个临近的训练实例中的多数的label决定输入实例的类。当K=1时算法退化为最近邻搜索。
多数表决规则(majority voting rule)本质也是最优化技术,它符合极大似然估计原则。
我们假设分类的损失函数为0-1损失函数为:
那么误分类的概率是:
对给定的实例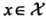 ,其最近邻的 k 个训练实例点构成集合
,其最近邻的 k 个训练实例点构成集合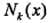 ,如果涵盖
,如果涵盖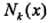 的区域的类别是Cj,那么误分类率是:
的区域的类别是Cj,那么误分类率是:
要使误分类率最小,即经验风险最小,就要使下式最大:
即模型对训练样本的预测准确度(拟合程度)最大。所以多数表决规则等价于经验风险最小化。
KNN的学习策略很简单,就是在训练集中寻找最近邻的K个实例点,并进行voting,选择最多类别的那个,即经验风险最小化。这同样体现了极大似然估计的核心思想。
KNN的策略非常直观易理解,算法要解决是具体的工程化问题,即如何在高维空间中选出 k 个近邻点,当维度很高且样本量很大的时候,如果不采取一些高效的算法而直接暴力搜索的话是非常耗时的。
解决该问题的思路就是利用特殊构造的存储数据结构以及特殊的搜索方法来完成,这也是本文的重点讨论部分。
最先被提出的一种数据结构是树结构,通过应用分治思想,树结构将原始的O(N)复杂度降低为O(logN)复杂度,我们接下来来讨论它。
KD树是一种对K维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是一个二叉树,一棵KD树就是一个超平面,表示对K维空间的一个划分(partition)。构造KD树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一系列的K维超矩形区域。KD树的每个结点对应于一K维超矩形区域。
这里K是数据集属性的数量。
下图展示了一个k=2的小例子:
树不一定会发展到相同的深度,训练集中的每一个实例与树中的一个结点相对应,最多一半的结点是叶子节点。
输入:k维空间数据集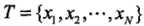 (样本数量是N),每个样本的维度是k,
(样本数量是N),每个样本的维度是k,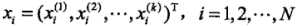
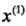 为坐标轴,以数据集T中所有实例的坐标的中位数做 i 为切分点,将根节点对应的超矩形区域切分为两个子区域,切分由通过切分点并与坐标轴垂直的超平面实现。由根节点生成深度为 1 的左,右子节点:
小于切分点的子区域大于切分点的子区域
为坐标轴,以数据集T中所有实例的坐标的中位数做 i 为切分点,将根节点对应的超矩形区域切分为两个子区域,切分由通过切分点并与坐标轴垂直的超平面实现。由根节点生成深度为 1 的左,右子节点:
小于切分点的子区域大于切分点的子区域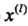 为切分的坐标轴,
为切分的坐标轴,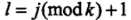 (取模循环不断根据每个维度进行二叉切分),以该节点的区域中所有实例的坐标的中位数作为切分点,将该结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴垂直的超平面实现。由该结点生成深度为 j + 1 的左、右子节点:
小于切分点的子区域;大于切分点的子区域;
(取模循环不断根据每个维度进行二叉切分),以该节点的区域中所有实例的坐标的中位数作为切分点,将该结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴垂直的超平面实现。由该结点生成深度为 j + 1 的左、右子节点:
小于切分点的子区域;大于切分点的子区域;用一个例子来说明kd树构造过程 ,给定一个二维空间的数据集:
轴,6个数据点的坐标的中位数是7,以平面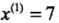 将空间分为左、右量子子矩形(子结点)
将空间分为左、右量子子矩形(子结点)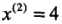 再分为两个子矩形;右矩形以
再分为两个子矩形;右矩形以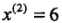 分为两个子矩形
分为两个子矩形与其他大部分机器学习方法相比,基于实例学习的一个优势是新的实例可以在任何时候加入到训练集里。
新的数据来临时,需要用新的数据点判断其属于哪个叶子节点,并且找出叶子节点的超矩形。如果超矩形为空,就将新数据点放置在那里,否则分裂超矩形,分裂在最长的边上进行,以保持方形。
这种简单的探索式方法并不能保证在加入一系列点后,树依然会维持平衡,也不能保证为搜索最近邻塑造良好的超矩形。有时候从头开始重建数不失为一个良策。例如,当树的深度达到最合适的深度值的两倍时。
完成了KD树建树后,接下来讨论如何利用KD树进行高效K近邻搜索:
输入:根据train set构造的kd树;目标点x
输出:x的最近邻
用下图来说明kd树的搜索过程,根节点为A,子节点是B,C,D,E,F,G;目标实例点S,求S的最近邻
我们已经看到,KD树是可用于有效寻找最近邻的良好数据结构,但是,并不完美。当面对不均匀数据的数据集时,便面临一些基本冲突和挑战:
这里所谓的平衡结构,就是指树的两边分叉要尽量分布平均,这样可以最大程度地发挥O(logN)的优化效果,但是如果数据点的分布非常不均衡,采用中值的方法也许会在同一个方向上产多多次后续分裂,从而产生瘦长型的超矩形。一个更好的解决方法是采用平均值作为分裂点而不是中位值。这样产生的KD树会更趋向于方形。
但是均值分裂点技术依然无法完全规避KD原生的问题,为此,学界提出了超球分界面代替超矩形分界面的改进方法。
KD tree的思想非常精妙,但是也存在一些问题, 形并不是用到这里最好的方式。偏斜的数据集会造成我们想要保持树的平衡与保持区域的正方形特性的冲突。另外,矩形甚至是正方形并不是用在这里最完美的形状,由于它的角。为了解决这些问题,引入了ball tree,即使用超球面而不是超矩形划分区域
Ball Tree就是一个K维超球面来覆盖训练样本点。
上图(a)显示了一个2维平面包含16个观测实例的图,图(b)是其对应的ball tree,其中结点中的数字表示包含的观测点数。
树中的每个结点对应一个圆,结点的数字表示该区域保含的观测点数,但不一定就是图中该区域囊括的点数,因为有重叠的情况,并且一个观测点只能属于一个区域。实际的ball tree的结点保存圆心和半径。叶子结点保存它包含的观测点。
Ball tree的建树过程和KD tree大体上一致,区别在于ball tree每次的切分点都是当前超球体的圆心。
使用Ball tree时:
Relevant Link:
http://blog.csdn.net/pipisorry/article/details/53156836
K近邻(k-Nearest Neighbor,KNN)算法,一种基于实例的学习方法
标签:这不 验证 order euc 区域 png 缩减 效率 世界
原文地址:https://www.cnblogs.com/w4ctech/p/11826681.html