标签:chrome mozilla 网页加载 lag 爬取 数据 pre 加载 bar
今天的任务是爬取拉勾网的职位信息。
首先,我们进入拉勾网,然后在职位搜索栏搜索Python 的同时,打开控制面板F12,来查看网页构成。
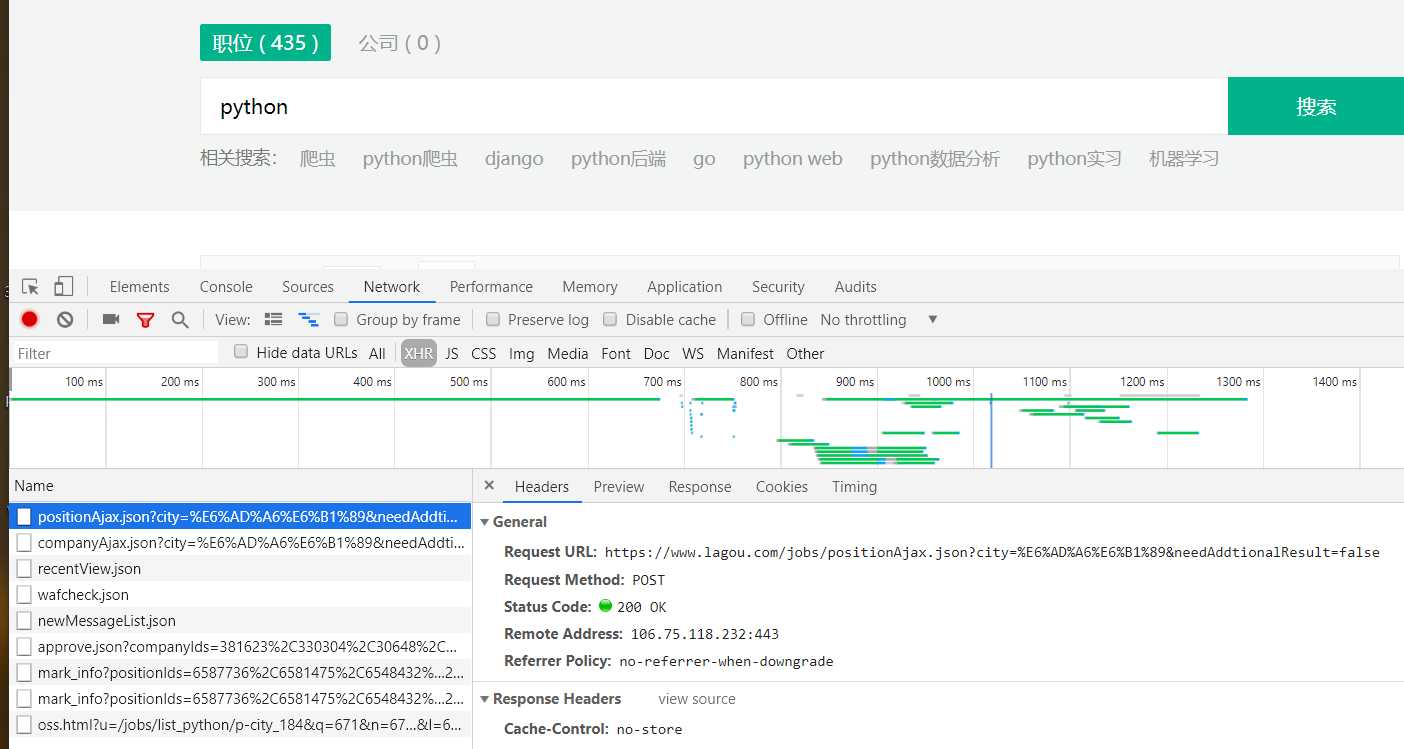
在XHR里,可以清楚的看见Ajax请求,所以需要使用session模块来模拟浏览器的行为来操作。
源代码如下:

import requests
import json
header = {
‘Accept‘: ‘application/json, text/javascript, */*; q=0.01‘,
‘Referer‘: ‘https://www.lagou.com/jobs/list_python%E7%88%AC%E8%99%AB/p-city_184?&cl=false&fromSearch=true&labelWords=sug&suginput=python‘,
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36‘
}
data = {
‘first‘: ‘true‘,
‘pn‘: ‘1‘,
‘kd‘: ‘python‘
}
url1 = ‘https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=‘ #主url
url = ‘https://www.lagou.com/jobs/positionAjax.json?city=%E6%AD%A6%E6%B1%89&needAddtionalResult=false‘ #ajax请求
s = requests.Session() #因为需要post和相关cookies,所以得创建session来帮忙获取cookies
s.get(url = url1 ,headers =header)
cookie = s.cookies
respon = s.post(url = url, headers = header, data = data, cookies = cookie)
res_json = json.loads(respon.text)
ret = res_json[‘content‘][‘positionResult‘][‘result‘]
for i in ret:
salary = i[‘salary‘]
name = i[‘positionName‘]
print(name,salary)
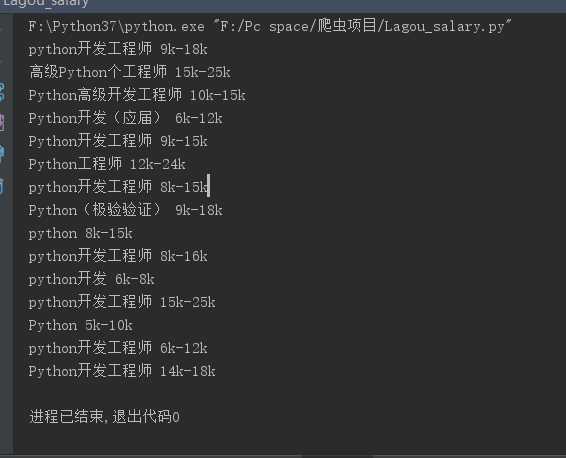
输出结果如下:
在爬取过程中,因为在使用requests模拟浏览器访问数据的时候,出现了访问频繁的问题。
拉钩的网页加载的时候有一个url专门返回除了招聘信息以外的其它东西,加载招聘信息的时候会产生另外一个ajax请求,请求返回的正是我们想要的内容,只需要在先发送主请求,之后用
requests.Session()建立Session,建立完成session之后通过session来获取cookie,拿到cookie就可以直接用了。该方法的缺点在于每次的获取,都相当于重新打开一次浏览器。
最后通过一系列的取key来获取我们想要的值:Python职位+职位对应的薪水
标签:chrome mozilla 网页加载 lag 爬取 数据 pre 加载 bar
原文地址:https://www.cnblogs.com/lesliechan/p/11827330.html