标签:incr false src ack for 查找 nullable 四十 nbsp
group_by:根据某个字段进行分组,比如想要根据年龄进行分组,再统计每一组有多少人
having:对查找结果进一步过滤,类似于SQL语句的where
准备工作
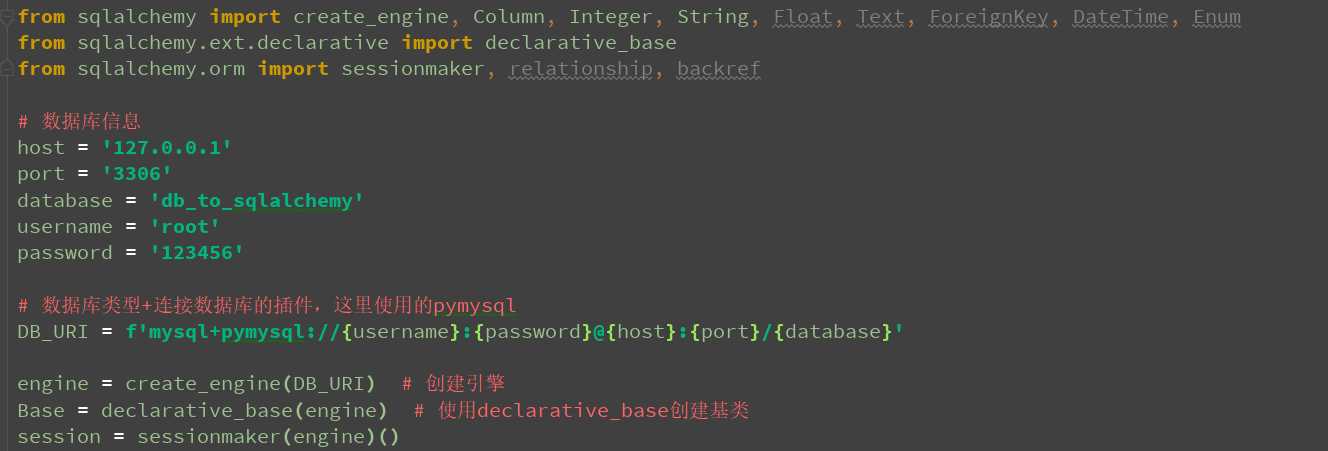
from sqlalchemy import create_engine, Column, Integer, String, Float, Text, ForeignKey, DateTime, Enum
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, relationship, backref
# 数据库信息
host = ‘127.0.0.1‘
port = ‘3306‘
database = ‘db_to_sqlalchemy‘
username = ‘root‘
password = ‘123456‘
# 数据库类型+连接数据库的插件,这里使用的pymysql
DB_URI = f‘mysql+pymysql://{username}:{password}@{host}:{port}/{database}‘
engine = create_engine(DB_URI) # 创建引擎
Base = declarative_base(engine) # 使用declarative_base创建基类
session = sessionmaker(engine)()
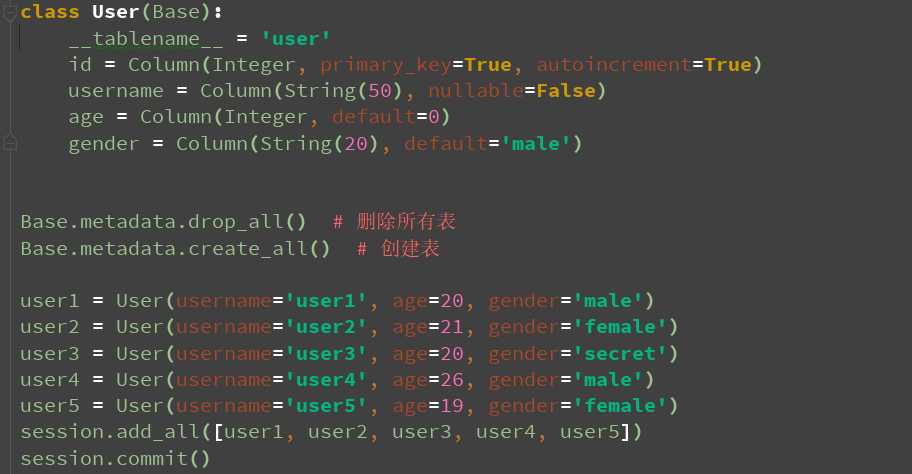
class User(Base):
__tablename__ = ‘user‘
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
age = Column(Integer, default=0)
gender = Column(String(20), default=‘male‘)
Base.metadata.drop_all() # 删除所有表
Base.metadata.create_all() # 创建表
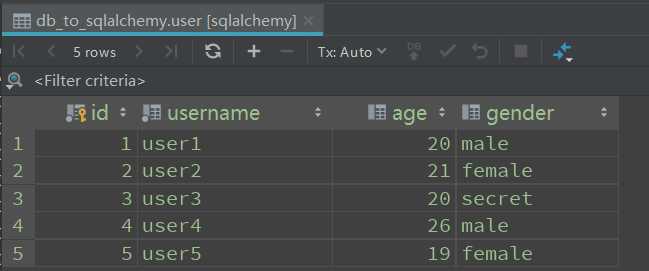
user1 = User(username=‘user1‘, age=20, gender=‘male‘)
user2 = User(username=‘user2‘, age=21, gender=‘female‘)
user3 = User(username=‘user3‘, age=20, gender=‘secret‘)
user4 = User(username=‘user4‘, age=26, gender=‘male‘)
user5 = User(username=‘user5‘, age=19, gender=‘female‘)
session.add_all([user1, user2, user3, user4, user5])
session.commit()
group_by:将数据根据指定的字段进行分组,如:根据年龄 分组,统计每个组的人数
先看一下转化的SQL语句
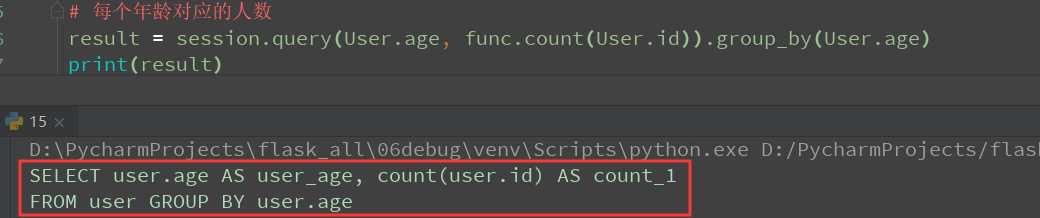
查询返回数据

having:对返回数据进行二次过滤,类似于where,如:根据年龄 分组,统计每个组的人数,然后再删选出年龄大于25的数据
先看一下转化的SQL语句

查询返回数据

四十三:数据库之SQLAlchemy之group_by和having子句
标签:incr false src ack for 查找 nullable 四十 nbsp
原文地址:https://www.cnblogs.com/zhongyehai/p/11828337.html