标签:python 获取 案例 网页数据 解析 爬虫 获取网页 image 第一步
*解析网页数据的仓库
用Beatifulsoup基于lxml包def get_html():
url="http://www.scetc.net"
response=request.get(url)
response.encoding="UTF-8"
return response.text
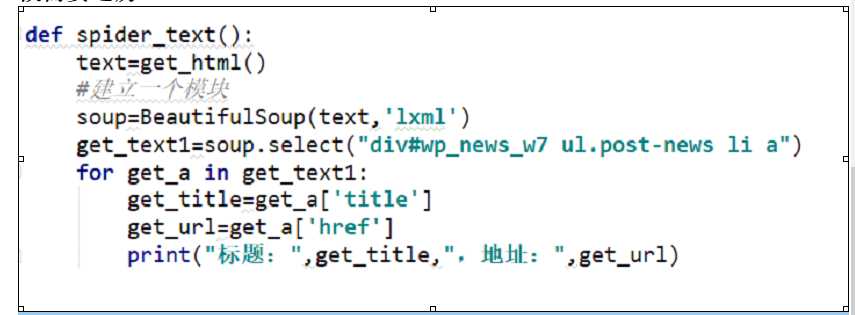
接着上次的python爬虫,今天进阶一哈,局部解析爬取网页数据
标签:python 获取 案例 网页数据 解析 爬虫 获取网页 image 第一步
原文地址:https://www.cnblogs.com/HYV587/p/11833876.html