标签:重复 let 特定 分组查询 distinct 作用 mit 插入数据 聚合函数
语法格式: select * | 字段列表 from 表1, 表2 where 表达式 group by ... having ... order by ... limit .. # 查询所有字段 select * from 表名; # 查询单个字段 select 列名 from 表名; # 查询多个字段 select 列名1, 列名2, ... from 表名; # 查询指定记录 select 列名 from 表名 where 查询条件; # 带IN关键字查询 select s_id, f_name, f_price from fruits where s_id IN (100, 110); # NOT 关键字检索不在条件范围内的条件。 select s_id, f_name, f_price from fruits where s_id NOT IN (100, 110); # between and select s_id, f_name, f_price from fruits where s_id between 100 and 110; # like select f_id, f_name from fruits where f_name like ‘b%‘; %:匹配多个字符 _:匹配任意单个字符 # 查询空值 select f_id, f_name from fruits where f_name is null; # 带and的多条件查询 select f_id, f_name from fruits where f_id=‘100‘ and f_name=‘apple‘; # 带OR的多条件查询 select f_id, f_name from fruits where s_id=100 or s_id=101; # 查询结果 去重 select distinct 字段名 from 表名; # 对查询结果排序 select 字段名 from 表名 order by 字段名; # 多列排序 select 列名 from 表名 order by 字段名1, 字段名2; # 指定排序方向 DESC 降序、ASC 升序 select 列名 from 表名 order by 字段名1, 字段名2 DESC; # 分组查询 GROUP BY 字段 HAVING 条件表达式 # 在 group by 子句中使用 WITH ROLLUP 在查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量。 例:GROUP BY s_id WITH ROLLUP # GROUP BY 和 ORDER BY 一起使用 # 使用 LIMIT 限制查询结果的数量 LIMIT 行数
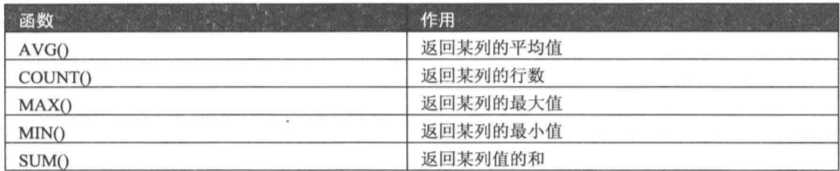
使用聚合函数查询
连接查询
# 内连接查询 INNER JOIN select 列名1, 列名2, ... from 表1 inner join 表1 ON 条件; # 外连接查询 左连接 LEFT JOIN:返回包括左表中的所有记录和右表中连接字段相等的记录。 右连接 RIGHT JOIN:返回包括右表中的所有记录和左表中连接字段相等的记录。 # 复合条件连接查询
子查询
# ANY 只要num1 大于 num2 的任何一个值,即符合查询条件 select num1 from tb1 where num1 > ANY (select num2 from tb2); # ALL num1 比 num2 所有值都大的值,即符合查询条件 select num1 from tb1 where num1 > ALL (select num2 from tb2); # EXISTS EXISTS 关键字后面的参数是一个任意的子查询,系统对子查询进行运算以判断它是否返回行,如果至少返回一行,那么EXISTS的结果为 true,此时外层查询语句将进行查询,反之,结果为false,此时外层语句将不进行查询。 # 带IN关键字的子查询 IN关键字进行子查询时,内层查询语句仅返回一个数据列,这个数据列的值将提供给外层查询语句进行比较操作。
合并查询数据 UNION
利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。
合并时,两个表对应的列数和数据类型必须相同。各个SELECT语句之间使用UNION或UNION ALL 关键字分割。
UNION不使用ALL,执行的时候删除重复的记录,所有返回的行都是唯一的;使用关键字ALL的作用是不删除重复行也不对结果自动排序。
基本语法格式如下:
SELECT column , ... FROM table1
UNION [ALL]
SELECT column , ... FROM table2;
为表和字段取别名
# 为表名取别名 表名 AS 表别名 # 为字段名取别名 列名 AS 列别名
使用正则表达式查询
MySQL中使用REGEXP关键字指定正则表达式的字符匹配模式。
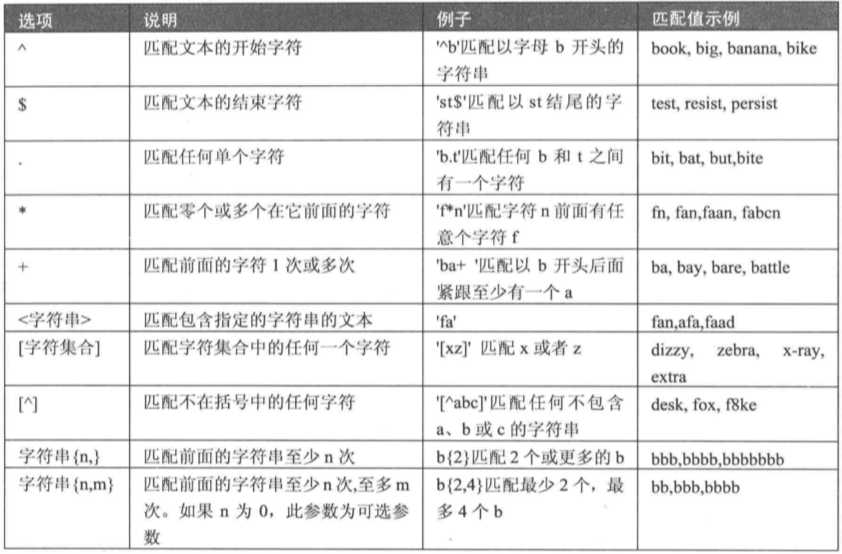
# 查询以特定字符或字符串开头的记录 ^ select * from fruits where f_name REGEXP ‘^b‘; # 查询以特定字符或字符串结尾的记录 select * from fruits where f_name regexp ‘y$‘; # 用符号 ‘.‘ 来替代字符串中的任意一个字符 select * from fruits where f_name regexp ‘a.g‘; # 使用 * 和 + 来匹配多个字符 * 匹配任意多次,包括0次。+ 匹配前面的字符至少出现一次。 # 匹配指定的字符串 只要这个字符串在查询中即可,如要匹配多个字符串之间使用分隔符 | 。 select * from fruits where f_name regexp ‘on|ap‘; # 匹配指定字符中的任意一个 方括号 [] 制动一个字符集合,只匹配其中任何一个字符,即为所查找的文本。 # 查找f_name 字段中包含字母 o 或者 t 的记录 select * from fruits where f_name regexp ‘[ot]‘; # 匹配指定字符以外的字符 [^字符集合] 匹配不在指定集合中的任何字符。 查询f_name 字段包含字母a~e和数字1~2以外的字符的记录 select * from fruits where f_id regexp ‘[a-e1-2]‘; # 使用 {n,} 或者 {n, m} 来指定字符串连续出现的次数 {n,} 表示至少匹配n次前面的字符;{n, m} 表示匹配前面的字符串不少于n次,不多于m次。 select * from fruits where f_name regexp ‘x{2,}‘;
2.1 为表的所有字段插入数据
INSERT INTO table_name (column_list) VALUES (values_list); 注意:使用该语句时 字段列和数据值的数量必须相同。 1、向表中所有字段插值的方法有两种:一种是指定所有的字段名,另一种是完全不指定字段名。 2、INSERT 语句后面的列名顺序可以不是表定义时的顺序。即插入数据时,不需要按照表定义的顺序插入,只要保证值的顺序与列字段的顺序相同就可以。 3、使用INSERT插入数据时,允许列名称列表为空,此时,列表中需要为表的每一个字段指定值,兵器人值的顺序必须和数据表中的阻断定义时的顺序相同。
2.2 为表的指定字段插入数据
为表的指定字段插入数据,就是在INSERT语句中只向部分字段中插入值,而其他字段为表定义时的默认值。
2.3 同时插入多条记录
INSERT 语句可以同时向数据表中插入多条记录,插入时指定多个值列表,每个值列表之间用逗号隔开,基本语法如下:
INSERT INTO table_name (column_list) VALUES (values_list1), (values_list2), ...;
2.4 将查询结果插入到表中
基本语法格式如下:
INSERT INTO table_name1 (column_list1)
SELECT (column_list2) FROM table_name2 WHERE (condition);
注意:column_list1 与 column_list2 列表中的字段个数相同,数据类型相同。
# 基本语法结构如下: UPDATE table_name SET column_name1=value1, column_name2=value2, ..., column_namen=valuen WHERE (condition); 例: UPDATE person SET age=15, name=‘hyp‘ WHERE id=11;
# 基本语法格式如下: DELETE FROM table_name [WHERE <condition>]; 例:DELETE FROM person where id=10; # 删除多条记录 DELETE FROM person WHERE age between 19 and 22; # 删除person表中所有数据, 但表还存在 DELETE FROM person;
标签:重复 let 特定 分组查询 distinct 作用 mit 插入数据 聚合函数
原文地址:https://www.cnblogs.com/pgxpython/p/11725708.html