标签:http 爬虫 请求 字符串 robot 特定 协议 状态码 响应状态
编码格式的认识:
在Python中字符串分为两种类型:
str与bytes的转换:
encode() #str->bytes
decode() #bytes->str
a = ‘华南理工大学广州学院‘
print(type(a)) #<class ‘str‘>
b = a.encode() #参数不填默认utf-8编码
print(b)
print(type(b)) #<class ‘bytes‘>
a = b.decode(‘utf-8‘)
print(a) #华南理工大学广州学院
Http和Https:
Http
Https
Https比http更安全,但是性能更低(耗时更长)
Url的形式:

http请求格式:
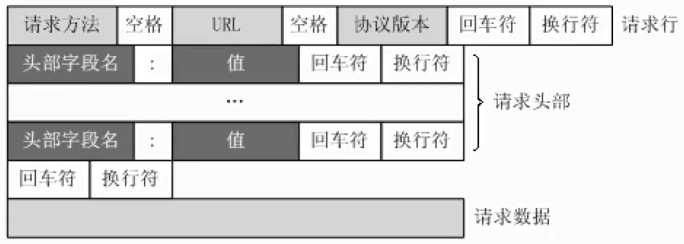
http常见请求头:

常见响应状态码:
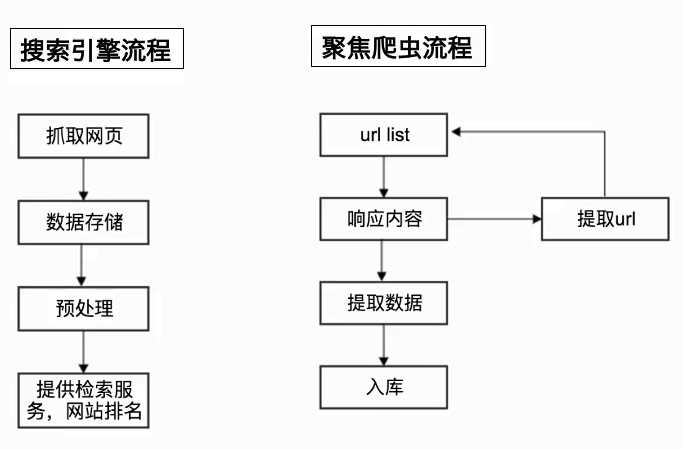
爬虫的分类:
通用爬虫与聚焦爬虫的流程:
Robots协议:
网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取
浏览器发送Http请求的过程:
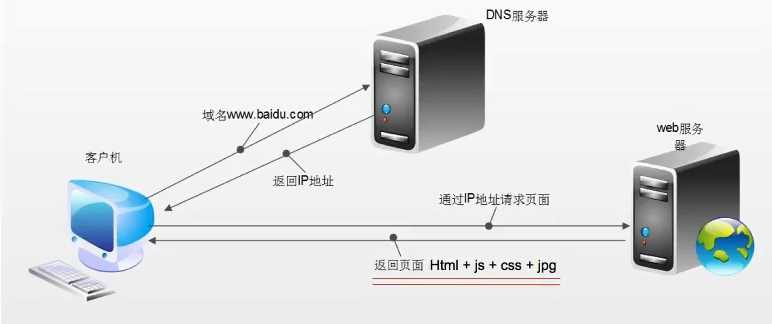
浏览器渲染出来的页面与爬虫请求的页面不一样
标签:http 爬虫 请求 字符串 robot 特定 协议 状态码 响应状态
原文地址:https://www.cnblogs.com/hhs1998/p/11841021.html