标签:min() 假设 更新 iris mode array spl red append
在机器学习中,感知机(perceptron)是二分类的线性分类模型,属于监督学习算法。输入为实例的特征向量,输出为实例的类别(取+1和-1)。
感知机对应于输入空间中将实例划分为两类的分离超平面。感知机旨在求出该超平面,为求得超平面导入了基于误分类的损失函数,利用梯度下降法 对损失函数进行最优化(最优化)。
感知机的学习算法具有简单而易于实现的优点,分为原始形式和对偶形式。感知机预测是用学习得到的感知机模型对新的实例进行预测的,因此属于判别模型。
感知机由Rosenblatt于1957年提出的,是神经网络和支持向量机的基础。
假设输入空间(特征向量)为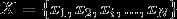 ,输出空间为
,输出空间为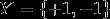 。
。
输入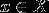
表示实例的特征向量,对应于输入空间的点;
输出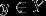
表示示例的类别。
由输入空间到输出空间的函数为
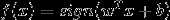
称为感知机。其中,参数w叫做权值向量(weight),b称为偏置(bias)。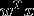 表示w和x的点积
表示w和x的点积
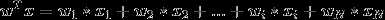
sign为符号函数,即
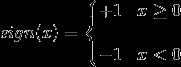
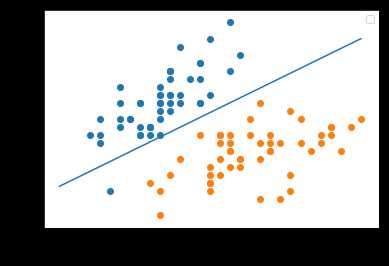
感知机算法就是要找到一个超平面将我们的数据分为两部分。
超平面就是维度比我们当前维度空间小一个维度的空间, 例如:我们当前的维度是二维的空间(由数据维度确定,x有多少列就有多大的维度),那么超平面就是一维的,即一条直线。如下图
数据集:
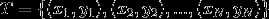
其中: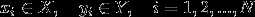
我们现在就是要找到一个超平面:
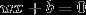
将数据集划分为正负两部分:

如果能得到这样一个超平面,则称我们的数据集T是线性可分的, 否则称数据集T是线性不可分的
感知机的损失函数是误分类点到超平面S的总距离

对于误分类的点:
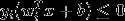
假设误分类点的集合为M,所有误分类点到超平面S的距离:
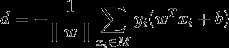
所以感知机的损失函数为:
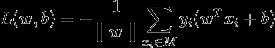
我们的问题就是要找到最优的w, b, 使得损失函数最小。
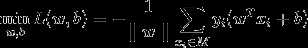
我们采用梯度下降算法:
梯度下降法就是利用导数,然后沿着导数的方向下降, 最后得到最优的解, 如图:
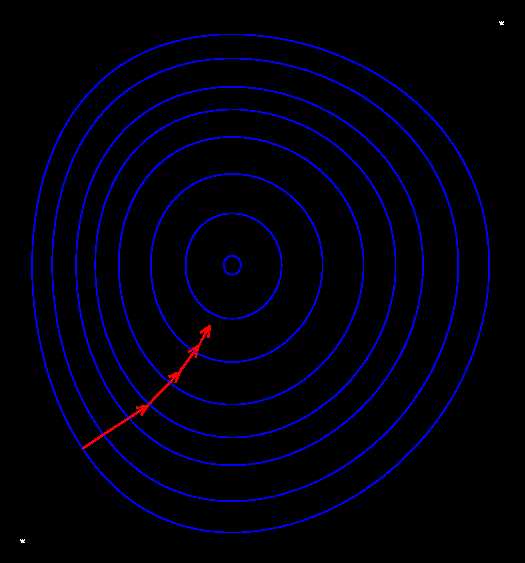
首先选择w0, b0,一般初始化为0.
然后分别对w, b求导:
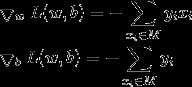
选择合适的步长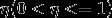 , 我们称为学习率。
, 我们称为学习率。
更新w,b:
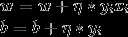
这样, 通过不断的更新w, b, 减小了损失函数,我们得到了最优的解
%pylab
%matplotlib inline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()#导入iris数据集
data = iris.data
data = data[:100]
labels = iris.target
labels = labels[:100]
feature_name = iris.feature_names
print("feature_name", feature_name)
#我们选择了sepal length (cm)', 'sepal width (cm)',并且更改了labels
data = data[:, 0:2]
labels[labels == 0] = -1
feature_name = feature_name[:2]
X_train, X_test, y_train, y_test = train_test_split(data, labels)#划分数据集class my_perceptron():
#初始化w,b,学习率
def __init__(self, lr=0.01):
self.w = 0
self.b = 0
self.lr = lr
def fit(self, X, y):
w = np.zeros(len(X[0]))
b = 0
lr = self.lr
all_true = False
#只要存在误分类点就继续循环
while not all_true:
all_true = True
for i in range(len(X)):
#误分类条件
if y[i]*(np.dot(w, X[i]) + b) <= 0:
all_true = False
#更新w,b
w += lr*y[i]*X[i]
b += lr*y[i]
self.w = w
self.b = b
def predict(self, X):
res = []
for i in range(len(X)):
if np.dot(self.w, X[i]) + b <= 0:
res.append(-1)
else:
res.append(1)
return np.array(res)
def score(self, y_predict, y_test):
return np.mean(y_predict == y_test)clf = my_perceptron()
clf.fit(X_train, y_train)
w = clf.w
b = clf.b
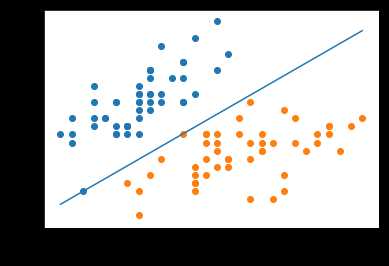
#绘图查看
plt.scatter(train[:50, 0], train[:50, 1])
plt.scatter(train[50:-1, 0], train[50:-1, 1])
xx = np.linspace(train[:, 0].min(), train[:, 0].max(), 100)
yy = -(w[0]*xx + b)/w[1]
plt.plot(xx, yy)
plt.xlabel(feature_names[0])
plt.ylabel(feature_names[1])
标签:min() 假设 更新 iris mode array spl red append
原文地址:https://www.cnblogs.com/hichens/p/11846945.html