标签:存储空间 普通表 说明 技术 键值 详细信息 产生 因此 ima
成本值的计算是根据目标SQL所涉及的表、索引、列等相关对象的统计信息,运用CBO固有的成本值计算公示计算出来的。
什么是Oracle里的统计信息:
Oracle数据库里的统计信息是这样的一组数据:它存储在数据字典里,且从多个维度描述了Oracle数据库里对象的详细信息。
Oracle数据库里的统计信息可以分为如下6种类型:
5.2 Oralce里收集与查看统计信息的方法
5.2.1 收集统计信息
有两种方法:
5.3.1.1 用ANALYZE命令收集统计信息
5.2.1.3 ANALYZE和DBMS_STATS的区别
ANALYZE和DBMS_STATS相比存在如下缺陷:
(1)ANALYZE命令不能正确地收集分区表的统计信息,而DBMS_STATS包却可以。
(2)ANALYZE命令不能并行收集统计信息,而DBMS_STATS包却可以。
5.2.2 查看统计信息
5.4索引统计信息
索引统计信息维度中我们需要重点关注的是BLEVEL(索引层级)、LEAF_BLOCKS(索引叶子快数量)和CLUSTERING_FACTOR(聚簇因子),它们在CBO计算访问索引成本的过程中扮演者举足轻重的作用。
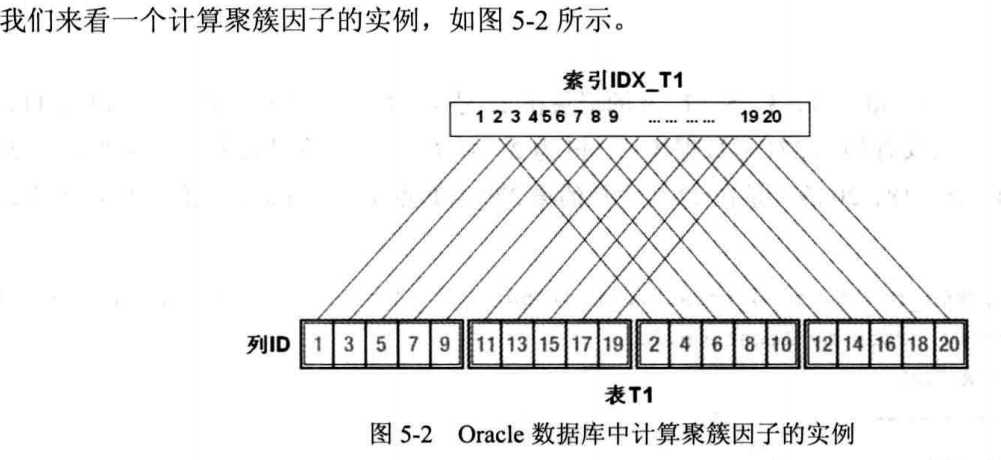
5.4.2 聚簇因子的含义及重要性
聚簇因子是指按照索引键值排序的索引行和存储于对应表中数据行的存储顺序的相似程度。(就是表中列的存储顺序和索引的值存储顺序越相似越好)
如果聚簇因子低,则说明索引行和存储于对应表中数据行的存储顺序相似,相邻行所对应的rowid极有可能处于同一个表块中,即Oralce在通过索引行记录的rowid回表第一次去读取对应的表块并将该表块缓存在buffer cashe中后,当再通过相邻索引行记录的rowid回表第二次去读取对应的表块时,就不需要再产生物理I/O了,因为这次要访问的和上次已经访问过的表块是同一个块,Oracle已经将其缓存在了buffer cache中。如果聚簇因子值大,则第二次通过rowid回表的时候,可能还会产生物理I/O,因此这次要访问的和上次已经访问的表块并不是同一个块。
换句话说,聚簇因子高的索引走索引范围扫描时比相同条件下聚簇因子低的索引要耗费更多的物理I/O,所以成本会更高。
标签:存储空间 普通表 说明 技术 键值 详细信息 产生 因此 ima
原文地址:https://www.cnblogs.com/studyking/p/11863497.html