标签:实战 算法思想 preview ssis www range 聚类分析 图片 and
介绍
kmeans算法又名k均值算法。
算法思想:先从样本集中随机选取 ??k 个样本作为簇中心,并计算所有样本与这 ??k 个“簇中心”的距离,对于每一个样本,将其划分到与其距离最近的“簇中心”所在的簇中,对于新的簇计算各个簇的新的“簇中心”。
实现kmeans算法的三点:
(1)簇个数 ??k 的选择
(2)各个样本点到“簇中心”的距离
(3)根据新划分的簇,更新“簇中心”
数据集:
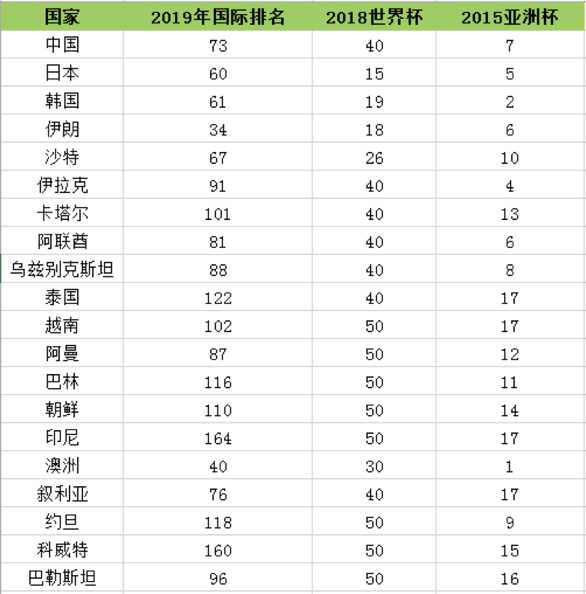
代码:
import numpy as np # vecA,vecB是数组形式 # 欧式距离 def distEclud(vecA,vecB): return sum((vecA-vecB)**2)**0.5
import numpy as np dataset=[ [73,40,7], [60,15,5], [61,19,2], [34,18,6], [67,26,10], [91,40,4], [101,40,13], [81,40,6], [88,40,8], [122,40,17], [102,50,17], [87,50,12], [116,50,11], [110,50,17], [164,50,17], [40,30,1], [76,40,17], [118,50,9], [160,50,15], [96,50,16] ] # 利用numpy.array函数将其转变为标准矩阵 dataset = np.array(dataset) print(dataset[0]) # 列数 print(np.shape(dataset)[1])
def kmeans0(dataset,k): # 样本的个数 m = np.shape(dataset)[0] # 保存每个样本的聚类情况,第一列表示该样本属于某一类,第二列是与聚类中心的距离 clusterAssment = np.mat(np.zeros((m,2))) # 产生随机质心,将列表形式转换为数组形式 centroids = np.array(randCent(dataset,k)) # 控制聚类算法迭代停止的标志,当聚类不再改变时,就停止迭代 clusterChanged = True while clusterChanged: # 先进行本次迭代,如果聚类还是改变,最后把该标志改为True,从而继续下一次迭代 clusterChanged = False for i in range(m): # 遍历每一个样本 # 每个样本与每个质心计算距离 # 采用一趟冒泡排序找出最小的距离,并找出对应的类 # 计算与质心的距离时,刚开始需要比较,记为无穷大 mindist = np.inf for j in range(k): # 遍历每一类 # print(np.array(dataset[i,:])) # print(centroids) distj =distEclud(dataset[i,:],centroids[j,:]) if distj<mindist: mindist = distj minj = j # 遍历完k个类,本次样本已聚类 if clusterAssment[i,0] !=minj: # 判断本次聚类结果和上一次是否一致 clusterChanged = True # 只要有一个聚类结果改变,就重新迭代 clusterAssment[i,:] = minj,mindist**2 # 类别,与距离 # 外层循环结束,每一个样本都有了聚类结果 # 更新质心 for cent in range(k): # 找出属于相同一类的样本 data_cent = dataset[np.nonzero(clusterAssment[:,0].A == cent)[0]] centroids[cent,:] = np.mean(data_cent,axis=0) return centroids,clusterAssment
结果1:
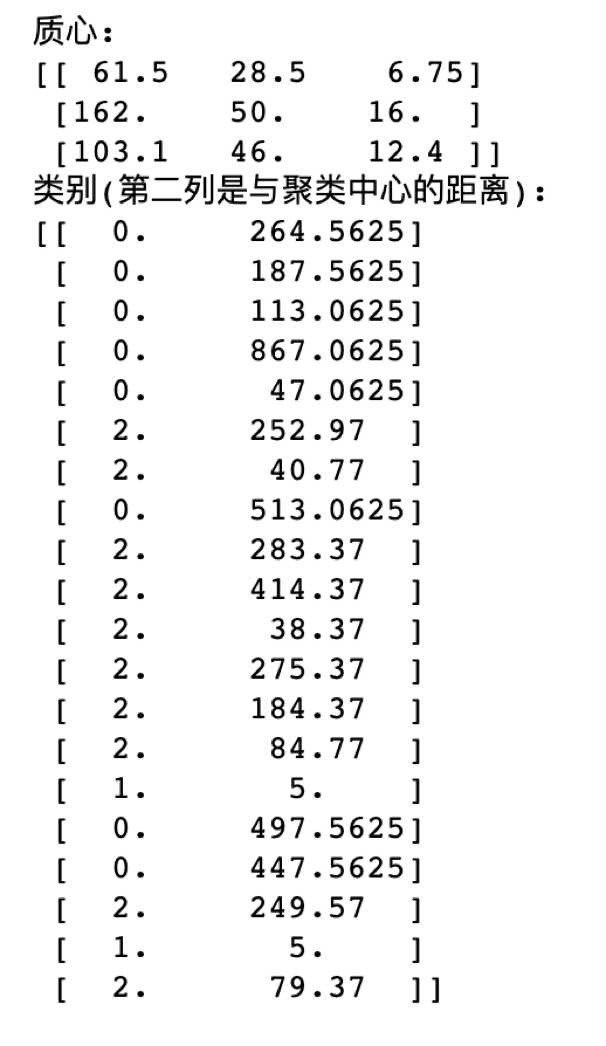
#提取不同类别的数据 n=(clusterAssment.size+1)//2 loan_data0=np.empty(shape=[0,2]) loan_data1=np.empty(shape=[0,2]) loan_data2=np.empty(shape=[0,2]) for i in range(n): # print(clusterAssment[i][0]) if(clusterAssment[i][0]==0.0): loan_data0=np.append(loan_data0,[[i,0]],axis = 0) if(clusterAssment[i][0]==1.0): loan_data1=np.append(loan_data1,[[i,1]],axis = 0) if(clusterAssment[i][0]==2.0): loan_data2=np.append(loan_data2,[[i,2]],axis = 0) print("第一类:") print(loan_data0) print("第二类:") print(loan_data1) print("第三类:") print(loan_data2)

作图
import matplotlib.pyplot as plt X0=[x[0] for x in loan_data0] Y0=[x[1] for x in loan_data0] X1=[x[0] for x in loan_data1] Y1=[x[1] for x in loan_data1] X2=[x[0] for x in loan_data2] Y2=[x[1] for x in loan_data2] plt.scatter(X0, Y0) plt.scatter(X1, Y1) plt.scatter(X2, Y2) plt.show()
结果3:
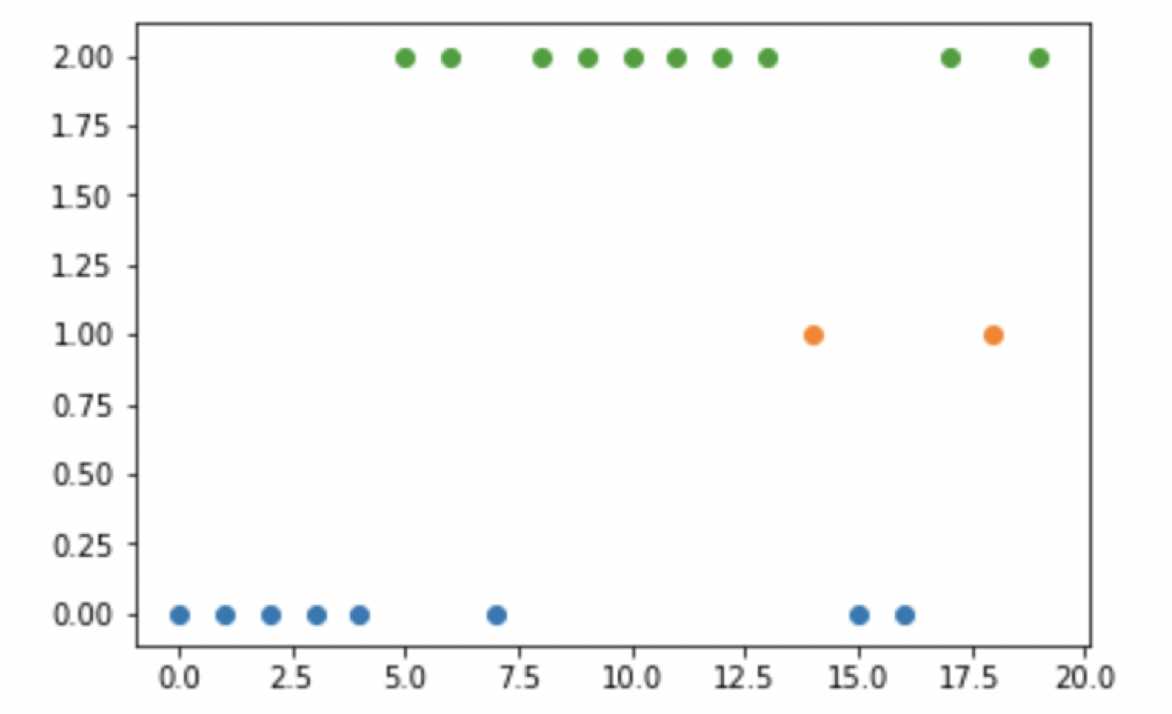
图说明:


标签:实战 算法思想 preview ssis www range 聚类分析 图片 and
原文地址:https://www.cnblogs.com/FYZHANG/p/11863330.html