标签:根据 sys 轻量 serve 不同的 har alt scan 读取
Microsoft SQL Server企业级平台管理实践 第11章
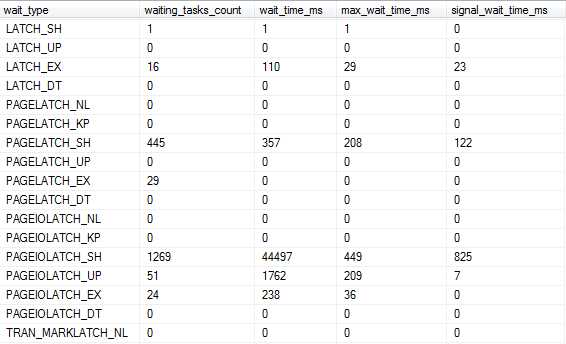
在分析SQL server 性能的时候你可能经常看到 PAGELATCH和PAGEIOLATCH。比方说执行如下TSQL语句
Select * from sys.dm_os_wait_stats
它输出结果里面就有Latch的有关信息,如下图所示:
Latch是SQL server内部用来同步资源访问的一个数据结构,和操作系统的critical section 或 ReaderWriterLock类似。Latch保护了那些想保护的资源,使得访问同步有序。比方说,当某个线程获得某个资源的latch的独占使用权的时候,别的线程如果也需要访问这个latch则它必须等待。那么又有新的疑问,latch和lock有什么区别呢?主要是使用的地方和目的不一样。Latch用来保护SQL server内部的一些资源(如page)的物理访问,可以认为是一个同步对象。而lock则强调逻辑访问。比如一个table,就是个逻辑上的概念,物理上一个表是有很多页组成的。访问一个表的记录的时候,首先可能需要获得表的共享锁,然后获得某个页的latch,然后就可以读取该页的记录。Lock是全局性的,由统一的lock manager管理。而latch没有统一的manager管理的。
PAGELATCH_x类型的latch是SQL Server在缓冲池里的数据页面上经常加的一类latch。它用来同步访问buff pool中的数据页。SQL server中的Buff pool里每个page都有一个对应的LATCH。 要访问某个PAGE必须首先获得这个PAGE的LATCH。PAGELATCH有很多种,如共享的PAGELATCH_SH,独占的PAGELATCH_EX等。独占的意思是排他性访问,只有一个线程可以访问,一般用户update,insert和delete操作。共享的意思是可以有多个线程同时获得这个latch。下面以在同一个data page中插入输入数据来说明pagelatch。可以参考博客:Buffer Latch Timeout的解析。
每个SQL Server的数据页面大致分成3个部分:页头、页尾偏移量和数据存储部分。假设现在有一个表格的结构是:
CREATE TABLE test (
a int,
b int
)
它在1:100这个页面上存储数据。那么这个页面结构大致如下图所示:
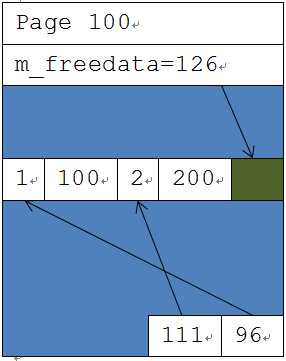
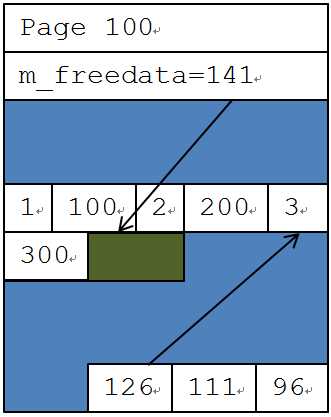
在页头部分,会记录页面属性,包括页面编号等,还会记录当前页面空闲部分的起始位置在哪里(m_freedata)。这样SQL Server在要插入新数据的时候,就能够很快地找到开始插入的位置。而页尾部的偏移记录了每一条数据行的起始位置。这样SQL Server在找每一条记录的时候,就能很快找到,不会把前一条记录和后一条搞混。在上图中page:100里现在有两条记录,(1,100)和(2,200)。第一条记录的开始位置是96,第二条的开始位置是111。从126开始,是空闲的空间。这页表明一列的长度是15。当页面里的数据行发生变化的时候,SQL Server不但要去修改数据本身,还要修改这些偏移量的值,以保证SQL Server能够继续准确地管理数据页面里的每一行。
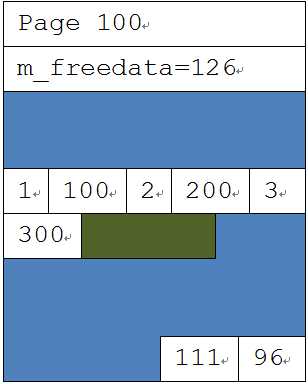
这时,另外一个进程要在页面100上,插入如下数据: INSERT VALUES(4, 400), 因为没有Latch锁,所以会覆盖之前的数据。导致数据插入出问题。如下图所示:
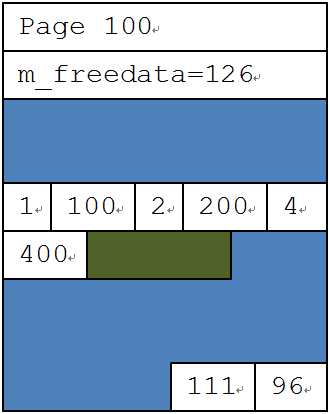
在逻辑层面上,插入两条数据是互不干扰的,但是在物理存储层面上,就出现了问题。要插入的两条数据读取的空闲空间位置m_freedata=126,都要往这个位置上面插入,那么总有一条数据会被另外一条数据所覆盖,从而导致插入错误。要想办法解决这个冲突,一定要定义出一个先后顺序。SQL Server为了解决这类问题,引入了另一类页面上的latch:PAGELATCH。当一个任务要修改页面时,它必须先申请一个EX的latch。只有得到这个latch,才能修改页面里的内容。所以这里的两个插入任务,不仅申请了页面上的锁,还要申请页面上的排他latch。假设(3,300)这个插入任务先申请到了,那(4,400)这个任务就会被阻塞住。所以,(3,300)这条记录能够被先插入,如下图所示。
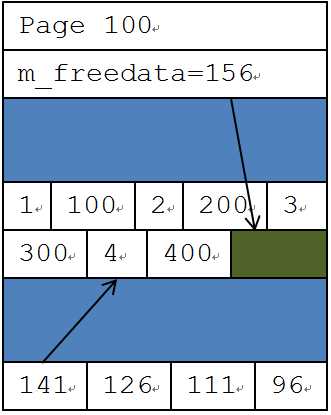
当(3,300)插入完成后,它申请的latch被释放,m_freedata的数据被更新。此时(4,400)就能得到latch资源,这是才读取m_freedata,然后往m_freedata位置插入数据。(4,400)被插在了(3,300)的后面。这样,两个插入都正确地完成了,如下图所示。
由于数据页的修改都是在内存中完成的,所以每次修改的时间都应该非常短,几乎可以忽略不计。而PAGELATCH只是在修改的过程中才会出现,所以PAGELATCH的生存周期应该也非常短。如果这个资源成为了SQL Server经常等待的资源,可说明以下问题。
当缓存在内存缓冲池区域里的数据页面,和磁盘上数据文件里的数据页面进行交互时(就是data page不在内存中),为了保证不会有多个用户同时读取/修改内存里的数据页面,SQL Server会像对待表格里的数据一样,对内存中的页面实行加锁的机制,以同步多用户并发处理。不同的是,在这里,SQL Server加的是latch(轻量级的锁),而不是lock。
例如,当SQL Server将数据页面从数据文件里读入内存时,为了防止其他用户对内存里的同一个数据页面进行访问,SQL Server会在内存的数据页面上加一个排他的latch。而当有任务要读缓存在内存里的页面时,会申请一个共享的latch。像lock一样,latch也会出现阻塞的现象。根据不同的等待资源,在SQL Server里等待的状态会是:

PAGEIOLATCH_DT : Destroy buffer page I/O latch PAGEIOLATCH_EX : Exclusive buffer page I/O latch PAGEIOLATCH_KP : Keep buffer page I/O latch PAGEIOLATCH_NL : Null buffer page I/O latch PAGEIOLATCH_SH : Shared buffer page I/O latch PAGEIOLATCH_UP : Update buffer page I/O latch
这里来举一个最容易发生的等待“PAGEIOLATCH_SH”,以它做例子,看看这种等待是怎么发生的。如下图所示:
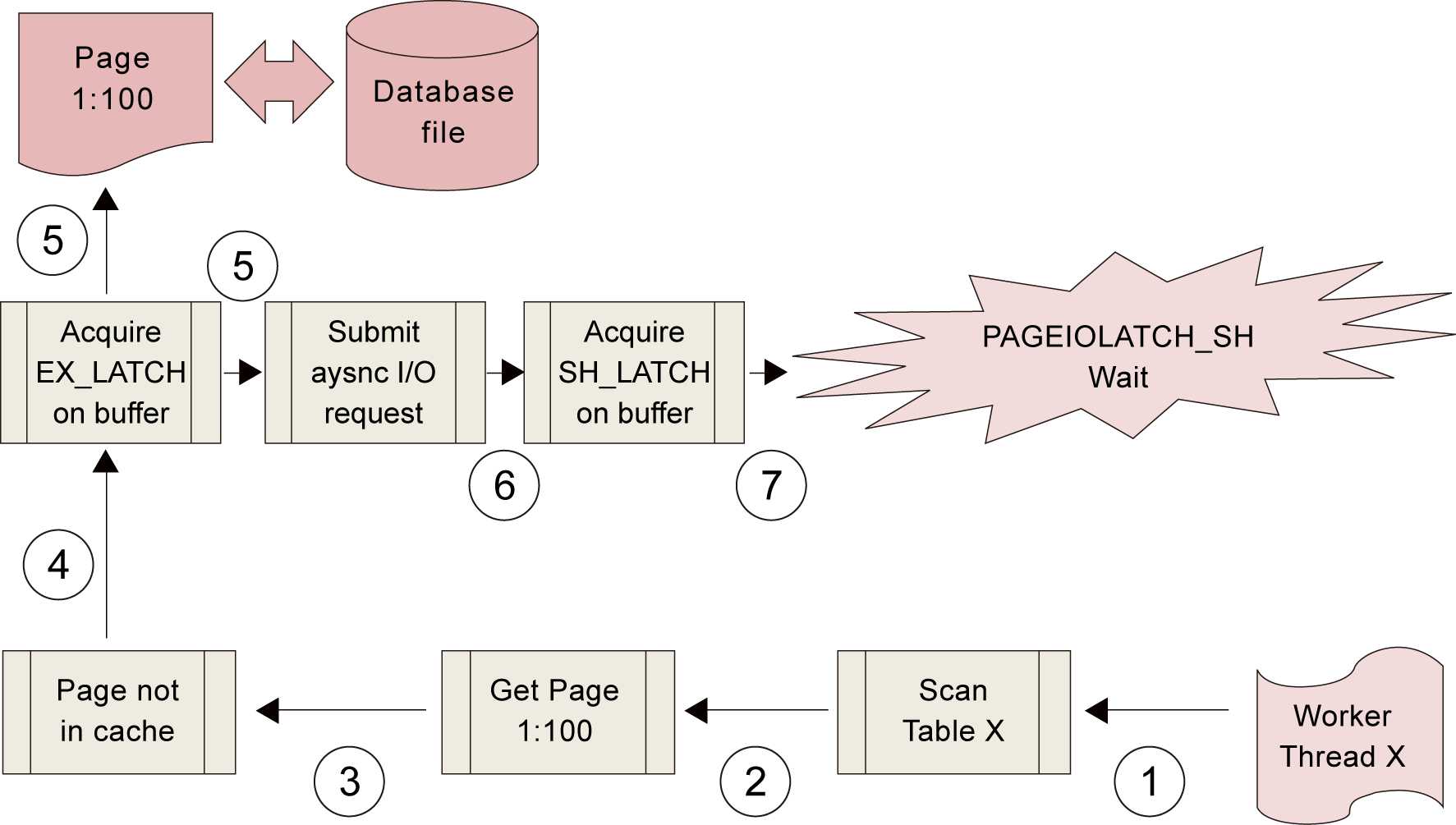
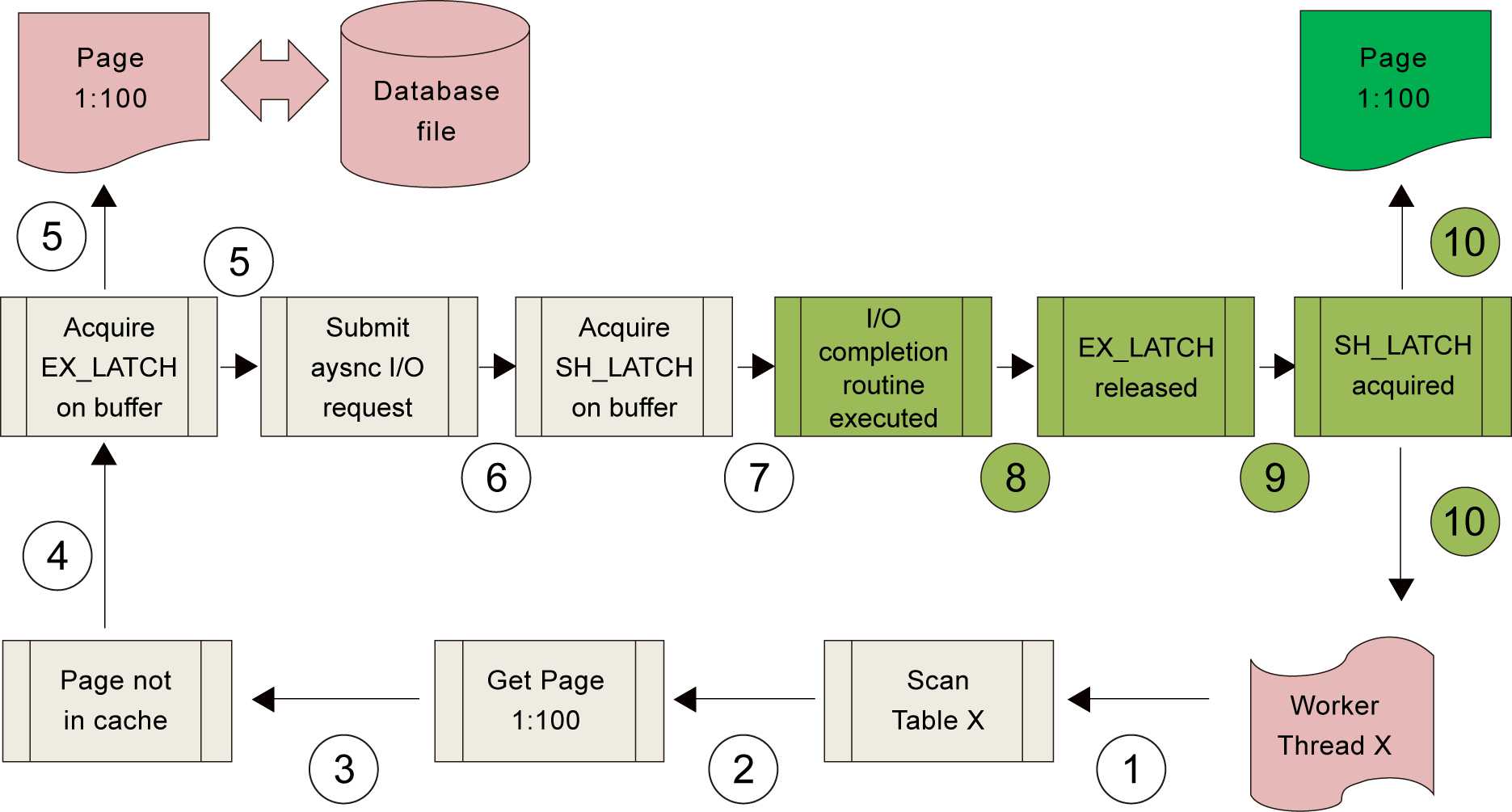
由此可以看到,在发生PAGEIOLATCH类型的等待时,SQL Server一定是在等待某个I/O动作的完成。所以如果一个SQL Server经常出现这一类的等待,说明磁盘的速度不能满足SQL Server的需要,它已经成为了SQL Server的一个瓶颈。
要强调的是,PAGEIOLATCH_x类型等待最常见的是两大类,PAGEIOLATCH_SH和PAGEIOLATCH_EX。PAGEIOLATCH_SH经常发生在用户正想要去访问一个数据页面,而同时SQL Server却要把这个页面从磁盘读往内存。如果这个页面是用户经常有可能访问到的,那么说到底,问题是因为内存不够大,没能够将数据页面始终缓存在内存里。所以,往往是先有内存压力,触发SQL Server做了很多读取页面的工作,才引发了磁盘读的瓶颈。这里的磁盘瓶颈常常是内存瓶颈的副产品。
而PAGEIOLATCH_EX常常是发生在用户对数据页面做了修改,SQL Server要向磁盘回写的时候,基本意味着磁盘的写入速度明显跟不上。这里和内存瓶颈没有直接的联系。
和磁盘有关的另一个等待状态是WRITELOG,说明任务当前正在等待将日志记录写入日志文件。出现这个等待状态,也意味着磁盘的写入速度明显跟不上。
SQL Server 中PAGELATCH_x和PAGEIOLATCH_x解析
标签:根据 sys 轻量 serve 不同的 har alt scan 读取
原文地址:https://www.cnblogs.com/VicLiu/p/11871249.html