三:表相关的操作
1、创建表
create table table_name
属性名 数据类型[完整性约束],
属性名 数据类型[完整性约束],
...
属性名 数据类型[完整性约束]
)
注意:在数据库创建的时候要选取合适的数据类型,而且还要添加完整性约束
完整性约束条件有:
-------------------------------------
约束条件 | 说明
-------------------------------------
primary key | 修饰的属性是该表的主键
-------------------------------------
foreign key | 修饰的数据是该表的外键
-------------------------------------
not null |表示该字段不能为null
-------------------------------------
unique |修饰的属性值是唯一的
-------------------------------------
auto_increment |mysql的特色,表示该属性是自增的
-------------------------------------
default | 设置属性默认值
-------------------------------------
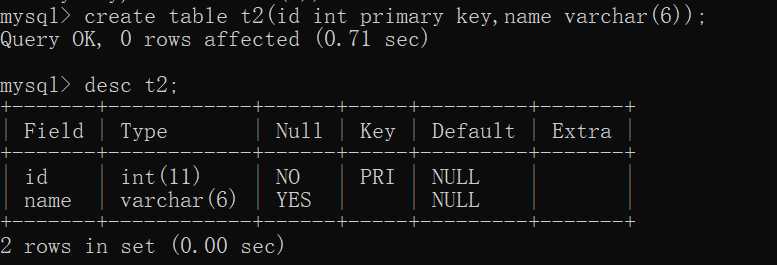
eg:create table t2(id int primary key, name varchar(5));
2.1、查看表
2.1.1、 desc table_name;
用desc可以查看表的字段名称(Fileld)、类型(Type)、是否为空(Null)、约束条件(Key)、默认值(Default)、备注信息(Extra)
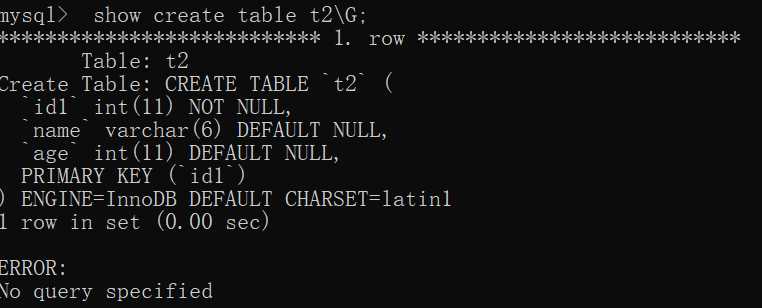
2.1.2 show create table table_name;
show create table可以打印创建的表的SQL,
并且显示该表的存储引擎和字符集编码(截图不方便,这样显示)
mysql> show create table t2;
+-------+--------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+--------------------------------------------------------------------------------------------------------------------------------------------+
| t2 | CREATE TABLE `t2` (
`id` int(11) NOT NULL,
`name` varchar(6) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 |
+-------+--------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
3.1 修改表
在使用的过程中不满足使用情况时,进行修改
3.1.1 修改表名SQL
alter table old_table_name rename [to] new_table_name;

3.1.2、修改表中字段类型SQL:
alter table table_name modify 属性名 数据类型;
eg:alter table t1 id bigint;
3.1.3、修改表中属性名SQL:
alter table table_name change 旧属性名 新属性名 新数据类型;
eg:alter table t1 change id idd int;
3.1.4、增加新的字段SQL:
alter table table_name add 属性名 数据类型 [完整性约束] [first|after 属性名2]
eg:alter table t1 add age int;
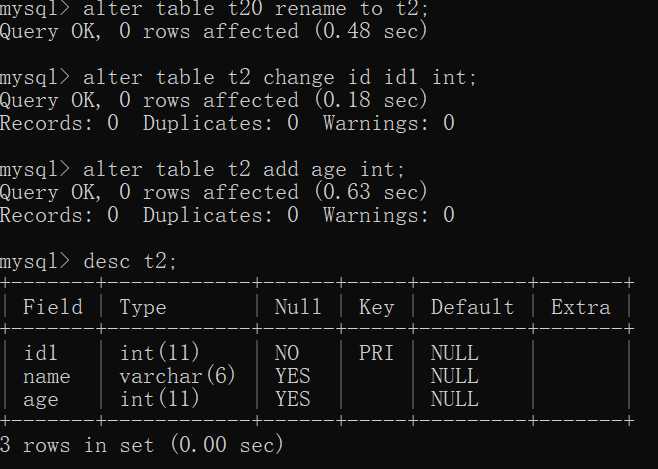
显示该表的存储引擎和字符集编码
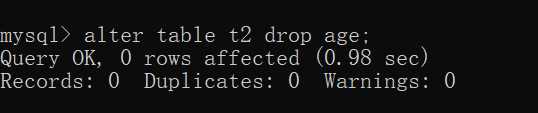
3.1.5、删除属性SQL:
alter table table_name drop 属性名;
eg:alter table t1 drop age2;
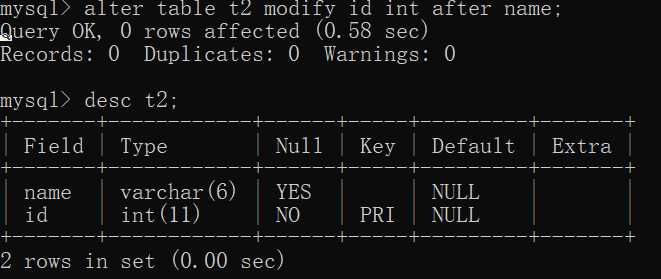
3.1.6、修改属性的排列顺序SQL:
alter table table_name modify 属性名1 数据类型 first | after 属性名2;
4. 查询表SQL
SQL基本的结构如下:
select 属性列表 from table_name [where 条件表达式1]
[group by 属性1 [having 条件表达式2]]
[order by 属性2 [asc | desc]]
插入属性值后显示表:
4.1 带in的子查询
[not] in(元素1,元素2...元素n)
eg:select * from Student where SID in (1,3,5);
4.2 带between and 的范围查询
[not] between 取值1 and 取值2
eg:select * from Student where SID between 3 and 7;
4.3 带like的模糊查询字符串
[not] like ‘abc‘;
注意:like可以结合通配符使用
%:表示0个或者是任意长度的字符串
_:只能表示单个字符
eg:select * from Student where Sname like ‘CJ%‘;
+-----+--------+------+------+
| SID | Sname | Ssex | Sage |
+-----+--------+------+------+
| 5 | CJ1210 | 1 | 11 |
| 7 | CJ1210 | 1 | NULL |
+-----+--------+------+------+
4.4 空值查询
is [not] null;
eg:select * from Student where Sage is not null;
4.5 带and 的多条件查询
条件表达式1 and 条件表达式2 [and ...条件表达式n]
eg:select * from Student where Ssex =‘nan‘ and Sage=20;
4.6 带or的多条件查询
条件表达式1 or 条件表达式2 [or ...条件表达式n]
4.7 去重复查询
select distinct 属性名
eg:select distinct Sage from Student;
4.8 对结果排序
order by 属性名 [asc| desc];
asc:升序(默认是胜序) desc:降序
eg:select * from Student order by SID asc;
4.9 分组查询
group by 属性名[having 条件表达式]
eg:select * from Student group by Ssex having Sage >= 18;
4.10 limit分页查询
不指定起始位置 limit是记录数
eg:select * from Student limit 3;
指定初始位置是limit的起始位置、记录数
eg:select * from Student limit 2,5;