标签:code 最小 相同 最大 esc 组合 div 字母 效果
1.全套装备
select [select选项] 字段列表[字段别名]/* from 数据源[where 条件子句] [group by条件子句] [having 子句] [order by 子句] [limit 子句];
什么是select选项呢?select选项是值select对查出来的结果的处理方式,主要有两种。all:默认的,保留所有的结果;distinct: 对查询结果进行去重;
Select select_expr [,select_expr…] [ From table_references [ where where_condition] [ group by {col_name | position} [asc|desc],… ] [ having where_condition ] [ order by {col_name | expr | position} [asc|desc],… ] [ limit {[offset,] row_count|row_count offset offset} ] ]
查询顺序:select→where→group by→having→order by→limit
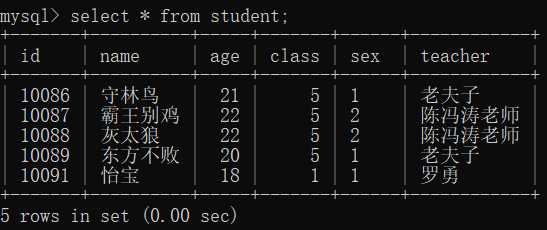
2.表中所有信息的查询 *
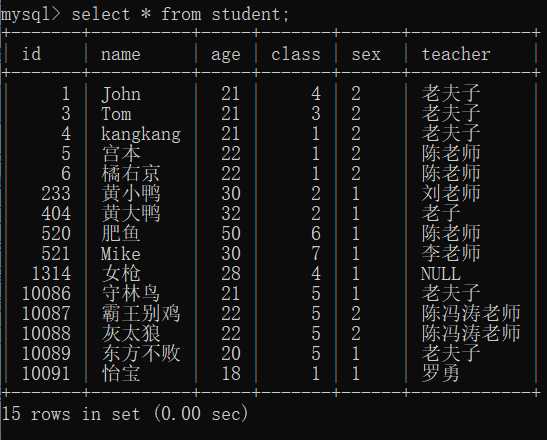
select * from student;
3.去重 distinct
select distinct class from student; select distinct class,teacher from student;
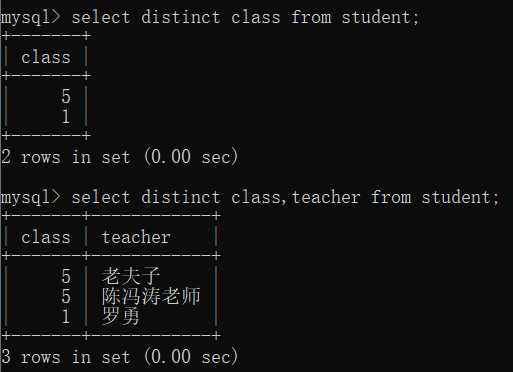
显然,所查询的列的值组合起来的行完全一样才会被去重。
4.指定列排序 order by,asc,desc
select * from student order by col_name {asc|desc};
asc 数值 :递增,字母:字典序
desc 数值:递减, 字母:反序
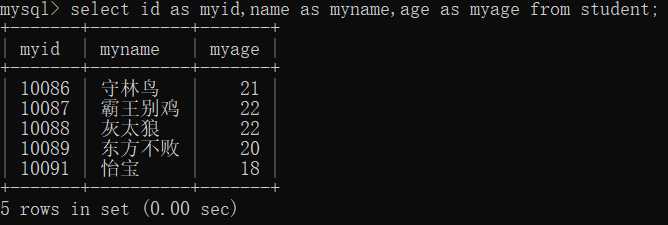
5.别名 as
select 列名 as 别名[,列名2 as 别名,...] from table_name;
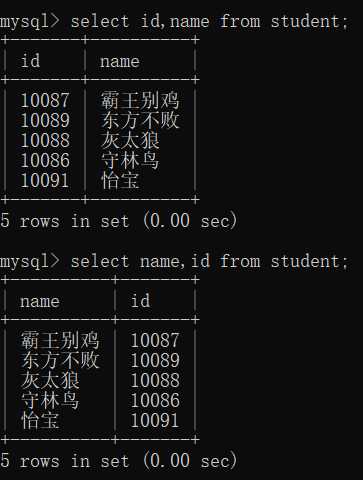
6.列查询(不同顺序结果不同)
select col_name[,col_name2...] from table_name;
7.聚合函数查询
sum()、avg()、max()、min()分别表示对某一列求和、平均、最大、最小。
count()表示查询记录出现的数量,count(列)不算null值的,count(*)有算null值。
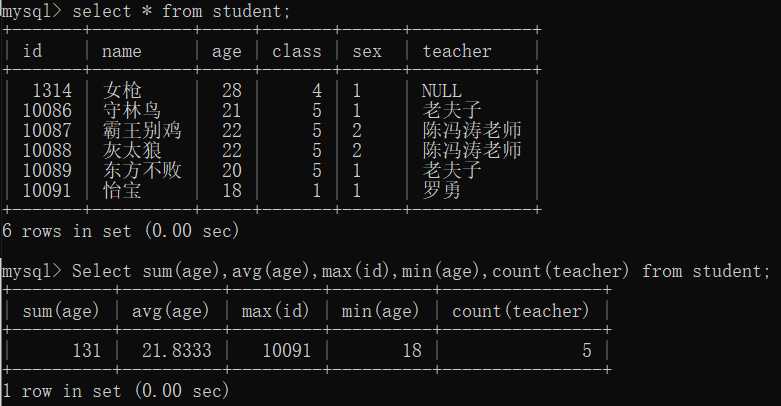
select sum(age),avg(age),max(id),min(age),count(teacher) from student
8.查询过滤 where(where子句不能用别名)
添加了几条记录测试模糊查询
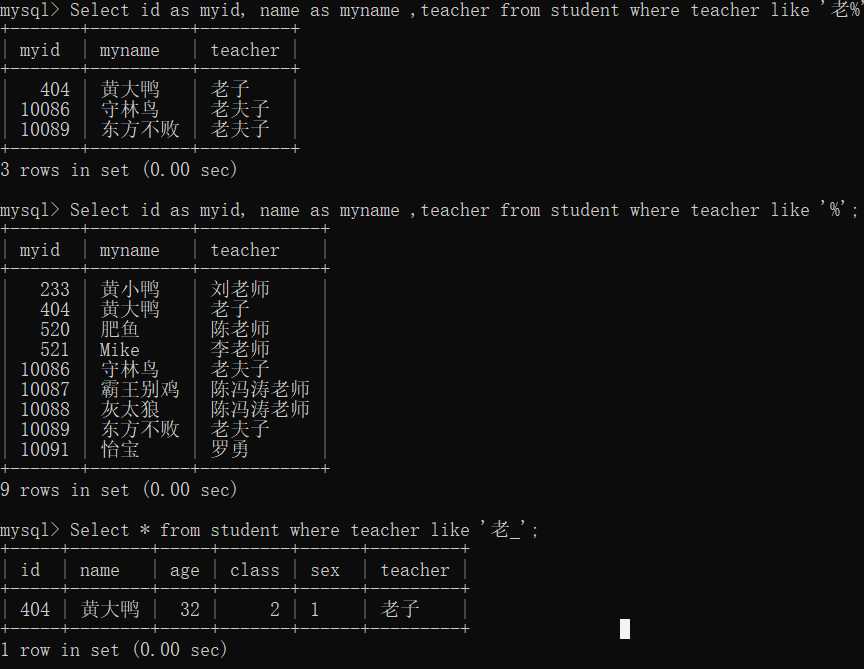
模糊查询的通配符:"%"表示任意长度的字符串(包括空字符但不包括空值),“_”表示单个字符。这里的汉字和字母都算1个字符。
Select id as myid, name as myname ,teacher from student where teacher like ‘老%’;--查询以"老"开头的 Select id as myid, name as myname ,teacher from student where teacher like ‘%’;--查询所有记录,除了null Select * from student where teacher like ‘老_’;--查询以老开头的两个字的记录
9.限制查询数量 limit
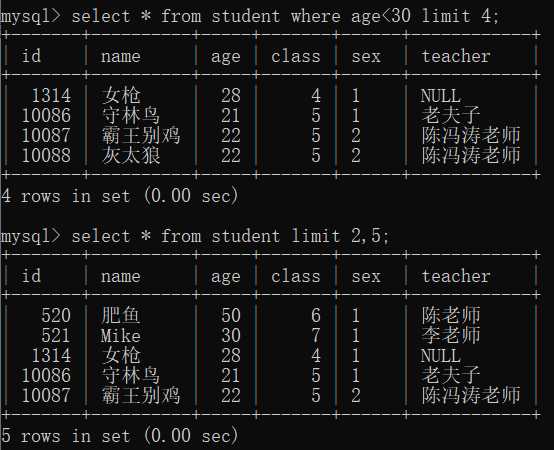
select * from student where age<30 limit 4;--默认从第一条记录开始搜寻,查找出4条记录就停止 select * from student limit 2,5;--记录的索引从0开始,这里限制从索引为2的开始即第3条语句,查找出5条语句 --如果数量不够则显示不出那么多记录
10.分组查询 group by
(1)最普通的用法,对于某一列相同的值只取1条语句,尝试后推测应该是记录中的第一条出现该列值的记录
select * from student group by class;
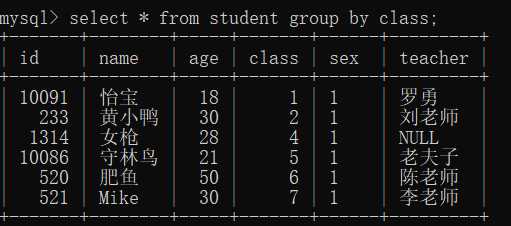
这样的记录显然没什么用,和去重效果一样,所以运用时需要加点东西。
(2)想知道该列的各个分组除了第一条记录的其他记录 group_concat(列名)
select group_concat(id),group_concat(name),age,class from student group by class;
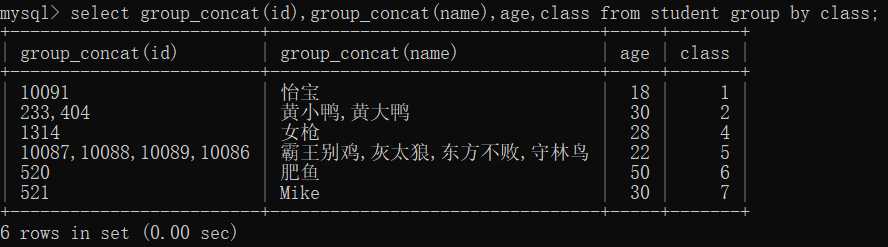
显然,没有使用group_concat()函数的都只显示一个值,id和name显示了所有的值并且一一对应,但是没有顺序可言,第4条记录的id可以看出。
(3)如果记录太多看不清一个组到底有多少人,用count()函数嵌套
select count(*),group_concat(name),group_concat(teacher),class from student group by class; select count(*),group_concat(name),count(teacher),class from student group by class;
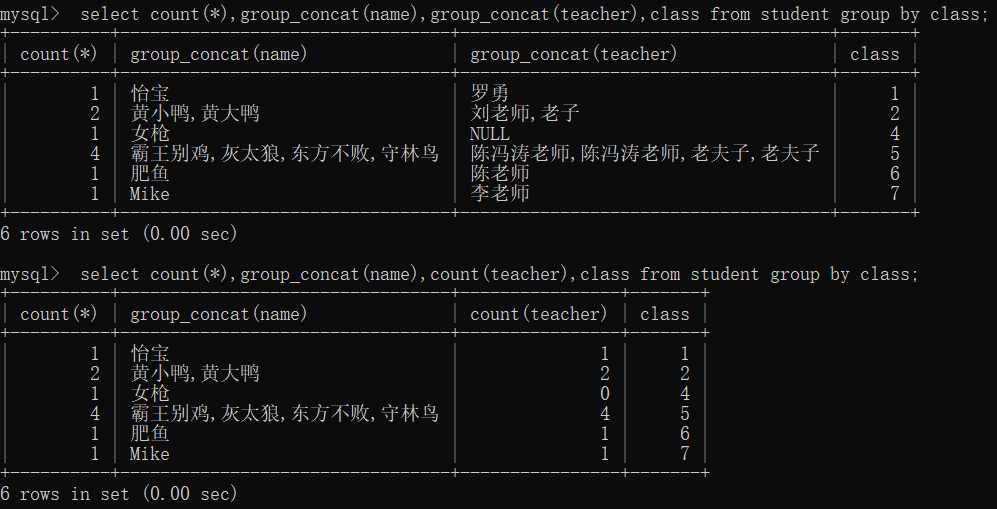
由图可知这样查询非常人性化,注意区分count(*)和count(列名)对于null值的计数。
其他聚合函数同理,例如查询每个班最大年龄的人则可以用max()函数嵌套。
11.二次筛选 having
担心数据不够又加了几组记录
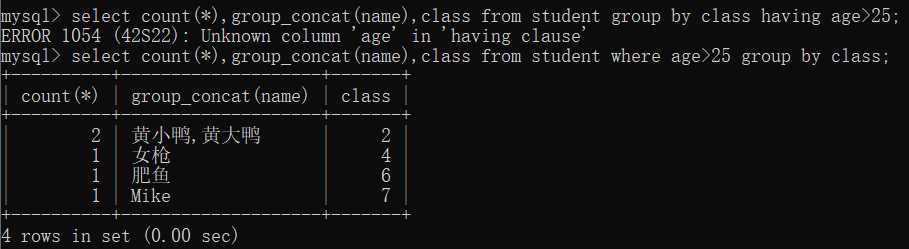
where和having的区别:where作用于表或视图,从中选择满足条件的元组。having短语作用于组,从中选择满足条件的组(所以一般与group by配合使用)。where是从查询满足条件的数据,用于查询数据之前;having用于在查出的数据中挑选满足条件的数据,在数据查出来之后处理。并且having的子句不能使用没有查出来的列名,where则可以,如下:
暂时就记录这些语句,以后遇到更复杂的再补充。
标签:code 最小 相同 最大 esc 组合 div 字母 效果
原文地址:https://www.cnblogs.com/shoulinniao/p/11863712.html