标签:执行sql 文件的 state udp 字符串 web应用 公众号 get 日志收集
XSSXSS的全称是跨站脚本(Cross Site Scripting),是WEB应用程序中最常见到的手段之一。跨站脚本指的是者在网页中嵌入恶意脚本程序, 当用户打开该网页时,脚本程序便开始在客户端的浏览器上执行,以盗取客户端cookie、 盗取用户名密码、下载执行病毒程序等等。
为了不和层叠样式表 (Cascading Style Sheets,CSS)的缩写混淆,故将跨站脚本缩写为XSS
有一种场景,用户在表单上输入一段数据后,提交给服务端进行持久化,其他页面上需要从服务端将数据取出来展示。还是使用之前那个表单nick,用户输入昵称之后,服务端会将nick保存,并在新的页面展现给用户,当普通用户正常输入hollis,页面会显示用户的 nick为hollis:
<body>
hollis
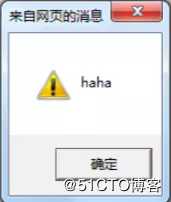
</body>但是,如果用户输入的不是一段正常的nick字符串,而是<script>alert("haha")</script>, 服务端会将这段脚本保存起来,当有用户查看该页面时,页面会出现如下代码:
<body>
<script>
alert("haha")
</script>
</body>其影响就是可能会在页面直接弹出对话框。
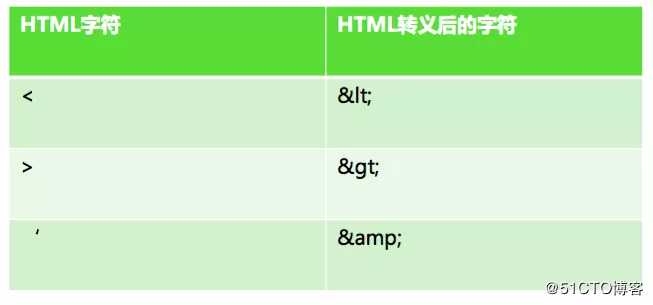
XSS之所以会发生,是因为用户输入的数据变成了代码。因此,我们需要对用户输入的数据进行HTML转义处理,将其中的“尖括号”、“单引号”、“引号” 之类的特殊字符进行转义编码。
如今很多开源的开发框架本身默认就提供HTML代码转义的功能,如流行的jstl、Struts等等,不需要开发人员再进行过多的开发。使用jstl标签进行HTML转义,将变量输出,代码 如下:
<c:out value="${nick}" escapeXml="true"></c:out>
只需要将escapeXml设置为true, jstl就会将变量中的HTML代码进行转义输出。
CSRF的全称是跨站请求伪造(cross site request forgery), 是一种对网站的恶意利用,你可以这么理解CSRF者盗用了你的身份,以你的名义向第三方网站发送恶意请求。CRSF能做的事情包括利用你的身份发邮件、发短信、进行交易转账等等,甚至盗取你的账号。
尽管听起来跟XSS跨站脚本有点相似,但事实上CSRF与XSS差别很大,XSS利用的是站点内的信任用户,而CSRF则是通过伪装来自受信任用户的请求来利用受信任的网站。
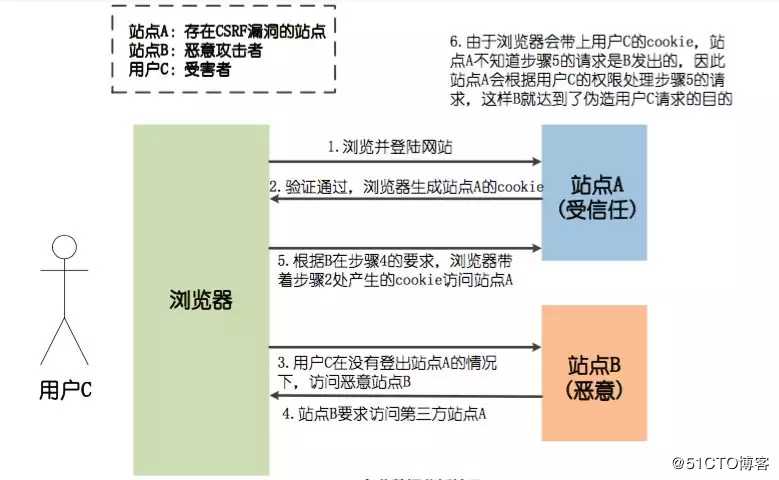
假设某银行网站A,他以GET请求来发起转账操作,转账的地址为www.xxx.com/transfer.do?accountNum=10001&money=10000,accountNum参数表示转账的目的账户,money参数表示转账金额。 而某大型论坛B上,一个恶意用户上传了一张图片,而图片的地址栏中填的并不是图片的地址,而是前面所说的转账地址:
<img src="http://www.xxx.com/transfer.do?accountNum=10001&money=10000">
当你登陆网站A后,没有及时登出,这个时候你访问了论坛B,不幸的事情发生了,你会发现你的账户里面少了10000块......
为什么会这样呢,在你登陆银行A的时候,你的浏览器端会生成银行A的cookie,而当你访问论坛B的时候,页面上的<img>标签需要浏览器发起一个新的HTTP请求,以获得图片资源, 当浏览器发起请求的时候,请求的却是银行A的转账地址www.xxx.com/transfer.do?accoun tNum=10001&money=10000,并且会带上银行A的cookie信息,结果银行的服务器收到这个请求后,会认为是你发起的一次转账操作,因此你的账户里边便少了10000块。
cookie设置为HttpOnly
CSRF很大程度上是利用了浏览器的cookie,为了防止站内的XSS漏洞盗取cookie,需要在cookie中设置"HttpOnly"属性,这样通过程序(如JavascriptS脚本、Applet等)就无法读取到cookie信息,避免了者伪造cookie的情况出现。
增加token
CSRF之所以能够成功,是因为者可以伪造用户的请求,该请求中所有的用户验证信息都存在于cookie中,因此者可以在不知道用户验证信息的情况下直接利用用户的cookie来通过安全验证。由此可知,抵御CSRF的关键在于:在请求中放入者所不能伪造的信息,并且该信息不存在于cookie之中。鉴于此,系统开发人员可以在HTTP请求中以参数的形式加入一个随机产生的token,并在服务端进行token校验,如果请求中没有token或者token内容不正确,则认为是CSRF而拒绝该请求。
通过Referer识别
根据HTTP协议,在HTTP头中有一个字段叫Referer,它记录了该HTTP请求的来源地址。在通常情况下,访问一个安全受限页面的请求都来自于同一个网站。比如某银行的转账是通过用户访问http://www.xxx.com/transfer.do页面完成,用户必须先登录www.xxx.com,然后通过点击页面上的提交按钮来触发转账事件。当用户提交请求时,该转账请求的Referer值就会是提交按钮所在页面的URL(本例为www.xxx.com/transfer.do)。如果者要对银行网站实施CSRF,他只能在其他的网站构造请求,当用户通过其他网站发送请求到银行时,该请求的Referer的值是其他网站的地址,而不是银行转账页面的地址。因此,要防御CSRF,银行网站只需要对于每一个转账请求验证其Referer值,如果是以www.xxx.com域名开头的地址,则说明该请求是来自银行网站自己的请求,是合法的。如果 Referer是其他网站的话,就有可能是CSRF,则拒绝该请求。
所谓SQL注入,就是通过把SQL命令伪装成正常的HTTP请求参数,传递到服务端,欺骗服务器最终执行恶意的SQL命令,达到目的。者可以利用SQL注入漏洞,查询非授权信息, 修改数据库服务器的数据,改变表结构,甚至是获取服务器root权限。总而言之,SQL注入漏洞的危害极大,者采用的SQL指令,决定的威力。当前涉及到大批量数据泄露的事件,大部分都是通过利用SQL注入来实施的。
假设有个网站的登录页面,如下所示:
假设用户输入nick为zhangsan,密码为password1,则验证通过,显示用户登录:

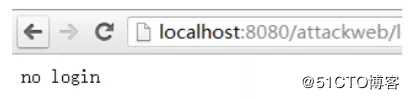
否则,显示用户没有登录:
**下面是一段普通的JDBC的Java代码,这段代码就可以被利用,进行SQL注入*:
Connection conn = getConnection();
String sql = "select * from hhuser where nick = ‘" + nickname + "‘" + " and passwords = ‘" + password + "‘";
Statement st = (Statement) conn.createStatement();
ResultSet rs = st.executeQuery(sql);
List<UserInfo> userInfoList = new ArrayList<UserInfo>();
while (rs.next()) {
UserInfo userinfo = new UserInfo();
userinfo.setUserid(rs.getLong("userid"));
userinfo.setPasswords(rs.getString("passwords"));
userinfo.setNick(rs.getString("nick"));
userinfo.setAge(rs.getInt("age"));
userinfo.setAddress(rs.getString("address"));
userInfoList.add(userinfo);
}当用户输入nick为zhangsan,密码为‘ or ‘1‘=‘1的时候,意想不到的事情出现了,页面显示为login状态:
当用户在密码栏输入“‘ or ‘1‘=‘1”后,代码中的SQL语句就会被拼接成:
"select * from hhuser user where nick = ‘zhangsan‘ and passwords = ‘‘ or ‘1‘=‘1‘",因为or后面的1=1是恒为true的,所以,该语句的执行结果就会有正常的数据返回。从而绕过密码校验。
以上便是一次简单的、典型的SQL注入。当然,SQL注入的危害不仅如此,假设用户输入用户名zhangsan,在密码框输入‘ ;drop table aaa;-- 会发生什么呢?
使用预编译语句
预编译语句PreparedStatement是java.sql中的一个接口,继承自Statement接口。通过 Statement对象执行SQL语句时,需要将SQL语句发送给DBMS,由DBMS先进行编译后再执行。而预编译语句和Statement不同,在创建PreparedStatement对象时就指定了SQL语句,该语句立即发送给DBMS进行编译,当该编译语句需要被执行时,DBMS直接运行编译后的SQL语句,而不需要像其他SQL语句那样首先将其编译。
前面介绍过,引发SQL注入的根本原因是恶意用户将SQL指令伪装成参数传递到后端数据库执行, 作为一种更为安全的动态字符串的构建方法,预编译语句使用参数占位符来替代需要动态传入的参数,这样者无法改变SQL语句的结构,SQL语句的语义不会发生改变,即便用户传入类似于前面‘ or ‘1‘=‘1这样的字符串,数据库也会将其作为普通的字符串来处理。
使用ORM框架
由上文可见,防止SQL注入的关键在于对一些关键字符进行转义,而常见的一些ORM框架,如 ibatis、hibernate等,都支持对相应的关键字或者特殊符号进行转义,可以通过简单的配置, 很好的预防SQL注入漏洞,降低了普通的开发人员进行安全编程的门槛。 Ibatis的insert语句配置:
<insert id="insert" parameterClass="userDO">
insert into users(gmt_create,gmt_modified,userid,user_nick,address,age,sex) values(now(),now(),#userId#,#userNick#,#address#,#age#,#sex#)
</insert>
通过#符号配置的变量,ibatis能够对输入变量的一些关键字进行转义,防止SQL注入***。
避免密码明文存放
对存储的密码进行单向Hash,如使用MD5对密码进行摘要,而非直接存储明文密码,这样的好处就是万一用户信息泄露,即圈内所说的被“”,无法直接获取用户密码,而只能得到一串跟密码相差十万八千里的Hash码。
处理好相应的异常
后台的系统异常,很可能包含了一些如服务器版本、数据库版本、编程语言等等的信息,甚至是数据库连接的地址及用户名密码,者可以按图索骥,找到对应版本的服务器漏洞或者数据库漏洞进行,因此,必须要处理好后台的系统异常,重定向到相应的错误处理页面,而不是任由其直接输出到页面上。
在上网的过程中,我们经常会将一些如图片、压缩包之类的文件上传到远端服务器进行保存, 文件上传指的是恶意者利用一些站点没有对文件的类型做很好的校验这样的漏洞, 上传了可执行的文件或者脚本,并且通过脚本获得服务器上相应的权利,或者是通过诱导外 部用户访问或者下载上传的病毒或者文件,达到目的。
为了防范用户上传恶意的可执行文件和脚本,以及将文件上传服务器当做免费的文件存储服务器使用,需要对上传的文件类型进行白名单(非黑名单,这点非常重要)校验,并且限制上传文件的大小,上传的文件,需要进行重新命名,使者无法猜测到上传文件的访问路径。
对于上传的文件来说,不能简单的通过后缀名称来判断文件的类型,因为恶意可以将可执行文件的后缀名称改成图片或者其他的后缀类型,诱导用户执行。因此,判断文件类型需要使用更安全的方式。很多类型的文件,起始的几个字节内容是固定的,因此,根据这几个字节的内容,就可以确定文件类型,这几个字节也被称为魔数(magic number)。
DDoS(Distributed Denial of Service),即分布式拒绝服务,是目前最为强大、最难以防御的方式之一。前不久(2018-03-01),GitHub就遭受了一次比较严重的DDoS,我的文章《GitHub遭受的DDoS到底是个什么鬼?》中有关于这次和DDoS的详细介绍。这里不再赘述。
DDoS的有很多种类型,如依赖蛮力的ICMP Flood、UDP Flood等等,随着硬件性能的提升,需要的机器规模越来越大,组织大规模的越来越困难,现在已经不常见,还有就是依赖协议特征以及具体的软件漏洞进行的,如Slowloris,Hash碰撞等等,这类主要利用协议以及软件漏洞发起,需要在特定环境下才会出现,更多的者采用的是前面两种的混合方式,即利用了协议、系统的缺陷,又具备了海量的流量, 如SYN Flood、DNS Query Flood等等。
DNS Query Flood实际上是UDP Flood的一种变形,由于DNS服务在互联网中不可替代的作用,一旦DNS服务器瘫痪,影响甚大。
DNS Query Flood采用的方法是向被的服务器发送海量的域名解析请求,通常,请求解析的域名是随机生成,大部分根本就不存在,并且通过伪造端口和客户端IP,防止查询请求被ACL过滤。被的DNS服务器在接收到域名解析请求后,首先会在服务器上查找是否有对应的缓存, 由于域名是随机生成的,几乎不可能有相应的缓存信息,当没有缓存,并且该域名无法直接由该DNS服务器进行解析的时候,DNS服务器会向其上层DNS服务器递归查询域名信息,直到全球互联网的13台根DNS服务器。大量不存在的域名解析请求,给服务器带来了很大的负载,当解析请求超过一定量的时候,就会造成DNS服务器解析域名超时,这样者便达成了目的。
CC(Challenge Collapsar)属于DDoS的一种,是基于应用层HTTP协议发起的DDos,也被称为HTTP Flood。
CC的原理是这样的,者通过控制的大量“肉鸡”或者利用从互联网上搜寻的大量匿名的HTTP代理,模拟正常用户给网站发起请求直到该网站拒绝服务为止。大部分网站会通过CDN以及分布式缓存来加快服务端响应,提升网站的吞吐量,而这些精心构造的HTTP请求往往有意避开这些缓存,需要进行多次DB查询操作或者是一次请求返回大量的数据,加速系统 资源消耗,从而拖垮后端的业务处理系统,甚至连相关存储以及日志收集系统也无法幸免。
喜欢的可以关注我的公众号,java小瓜哥的分享平台,平时整理的资料都放在里面了
标签:执行sql 文件的 state udp 字符串 web应用 公众号 get 日志收集
原文地址:https://blog.51cto.com/14611538/2451076