标签:标记 就是 缓存 pool 字节 适用于 运行 计数 cto
线程安全问题?
当多个线程共享同一个全局变量,做写的操作时,可能会受到其他线程的干扰。读不会发生线程安全问题。 -- Java内存模型。
非静态同步方法使用什么锁?
this锁
静态同步方法使用什么锁?
当前类的字节码文件
什么是ThreadLocal?
ThreadLocal是给每个线程提供局部变量,每个线程可独立改变自己的副本,不会影响其他线程所对应的副本,解决线程安全问题。
ThreadLocal底层原理是map集合。
ThreadLocal内存泄漏问题?
由于ThreadLocalMap的key是弱引用,而Value是强引用。这就导致了一个问题,ThreadLocal在没有外部对象强引用时,发生GC时弱引用Key会被回收,而Value不会回收,如果创建ThreadLocal的线程一直持续运行,那么这个Entry对象中的value就有可能一直得不到回收,发生内存泄露。
如何避免泄漏?
Key是弱引用,在调用ThreadLocal的get()、set()方法时完成后再调用remove方法,将Entry节点和Map的引用关系移除,这样整个Entry对象在GC Roots分析后就变成不可达了,下次GC的时候就可以被回收。
如果使用ThreadLocal的set方法之后,没有显示的调用remove方法,就有可能发生内存泄露,所以使用完ThreadLocal之后,记得调用remove方法。
ThreadLocal<Session> threadLocal = new ThreadLocal<Session>(); try { threadLocal.set(new Session(1, "abc")); // 其它业务逻辑 } finally { threadLocal.remove(); }
使用ThreadLocal的典型场景如数据库连接管理,线程会话管理等场景,只适用于独立变量副本的情况,如果变量为全局共享的,则不适用在高并发下使用。
4个方法:
ArrayBlockingQueue(ABQ)与LinkedBlockingQueue(LBQ)的区别?
ABQ:底层数组,创建时要指定数组大小。有两个索引指针putIndex和takeIndex,不管在读或写元素,如果数组达到最后一个元素,直接将索引移动到第一个位置。 ABQ内部一把锁,offer和take使用同一把锁。内存是预先分配,使用过程中内存开销较小(无须动态申请内存)。
LBQ:底层单向链表,元素到来时放入链表头,从链表尾取数据。链表好处是不同提前分配内存。
如果没有指定长度,默认Integer.MAX_VALUE。LBQ的offer和take使用不同锁。在链表头放元素和在链表尾去元素不再竞争锁,加快数据处理。
无界时注意内存溢出问题,由于使用中动态分配内存,可能增加JVM GC负担。
线程池目的?
1. 降低资源消耗。 2. 提高响应速度。3.提高线程的可管理性。
线程池4种创建方式?
Executors提供四种线程池:
newCachedThreadPool :创建一个可缓存线程池, 最大线程数Integer.MAX_VALUE。
newFixedThreadPool :创建一个定长线程池,超出的线程会在队列中等待。
newScheduledThreadPool :创建一个定长线程池,支持定时及周期性任务执行。最大线程数Integer.MAX_VALUE。
newSingleThreadExecutor :创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
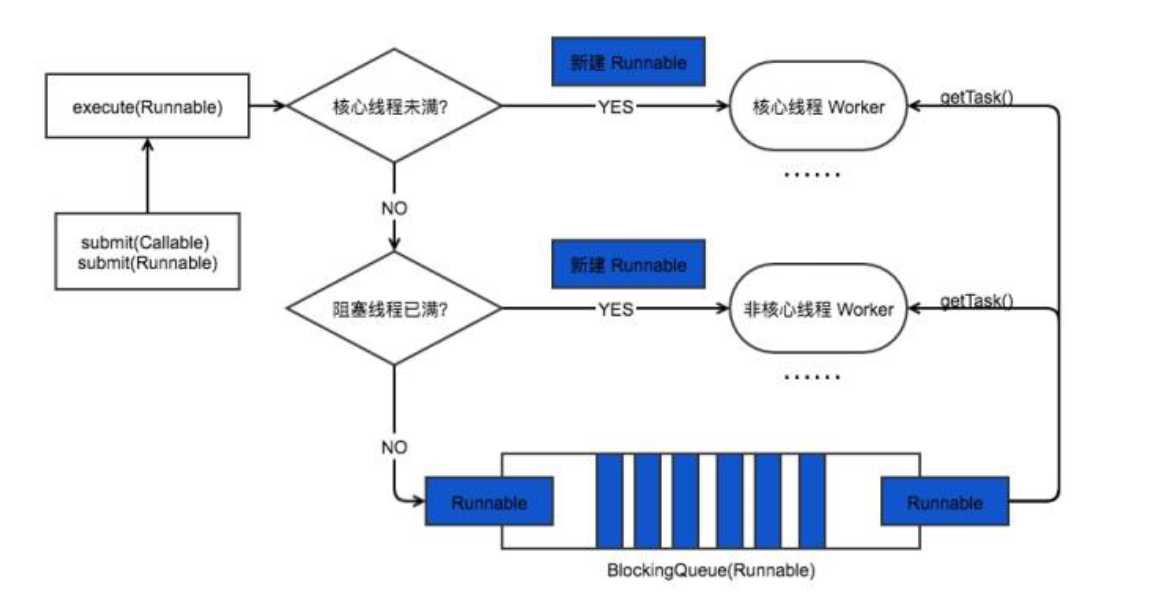
线程池原理/处理流程?
ThreadPoolExector的核心参数:
corePoolSize:核心线程数(实际运行线程数)
maximunPoolSize:最大线程数(线程池最多创建线程数)
keepAliveTime:当前线程池数量超过corePoolSize时,多余线程空闲时的存活时间
unit: keepAliveTime的时间单位
workQueue:任务队列,被提交但尚未被执行的任务
threadFactory:线程工厂,用于创建线程
handler:拒绝策略,当任务太多不能及时处理时,如何拒绝
JDK内置拒绝策略:
1. AbortPolicy:直接抛出异常
2. CallerRunsPolicy:来着不拒策略(直接调用run方法,而不是开启线程去执行任务)
3. DiscardOldestPolicy:丢弃最老的请求策略
4. DiscardPolicy:默认丢弃策略,超过工作队列容量的任务被丢弃
合理配置线程池:
CPU密集:应配置尽可能小的线程
IO密集:应配置尽可能多的线程,因为IO操作不占用CPU,不要让CPU闲下来,应加大线程数量。
CPU密集型时,任务可以少配置线程数,大概和机器的CPU核数相当,这样可以使得每个线程都在执行任务
IO密集型时,大部分线程都阻塞,故需要多配置线程数,2*CPU核数
什么是Callable和Future?
使用Callable和Future来实现获取任务结果的操作。Callable用来执行任务,产生结果,而Future用来获得结果。
Future: A和B两个线程,如果A需要B的执行结果,那么这个线程A不需要等待B执行完毕后才拿到结果。
使用Future模式可以先拿到一个未来的Future,等B有结果时再取真实的结果。类似ajax。
乐观锁
总是假设乐观情况,不上锁,使用版本号(version)机制和CAS操作。
原理:数据库表加version字段,当线程A要更新数据x时,读取x和version,提交更新时,刚才督导的version等于数据库种version时才更新。
悲观锁
总是假设最坏情况,每次操作数据认为其他线程会修改,所以都会加锁(读锁,写锁)。Synchronized是悲观锁。
CAS无锁原理
CAS: compare and swap。
三个参数:V:需要更新的值(主内存), E:预期值(本地内存) ,N: 新值
仅当V值等于E值时,才会将V的值设为N,如果V值和E值不同,则说明已经有其他线程做了更新,则当前线程什么都不做。最后,CAS返回当前V的真实值。
CAS的缺点: ABA问题
JUC提供带有标记的原子引用类AtomicStampedReference,通过控制变量版本保证CAS的正确性。
CountDownLatch(计数器)
CountDownLatch是使用AQS实现的,使用AQS的state变量来存放计数器的值。
在调用CountDownLatch的构造函数时,会调用内部类Sync的构造函数将值赋给state变量,当多个线程调用countdown方法时实际是使用CAS递减state变量的值;
当线程调用await方法后当前线程会被放入AQS阻塞队列等待计数器为0时返回,即所有线程都调用了countdown方法时。
最后,当计数器的值变为0时,当前线程还会调用AQS的doReleasedShared()方法激活调用await()方法而被阻塞的线程。
场景:开会,等待所有人(线程)到齐,主持人(主线程)才开始进行会议。
CyclicBarrier(循环栅栏)
允许多个线程相互等待,即多个线程到达同步点时被阻塞,直到最后一个线程到达同步点时栅栏才会被打开;
CyclicBarrier内部没有所谓的公平锁\非公平锁的静态内部类,只是利用了ReentrantLock(独占锁)、ConditionObject(条件对象)实现了线程之间相互等待的功能
用途让一组线程互相等待,直到都到达公共屏障点才开始各自继续做各自的工作
可重复利用,每正常走完一次流程,或者异常结束流程,那么接下来一轮还是可以继续利用CyclicBarrier实现线程等待功能(赛跑,初赛,复赛,决赛)
共存亡,只要有一个线程有异常发生中断,那么其它线程都会被唤醒继续工作,然后接着就是抛异常处理
Semaphore(信号量)
Semaphore 可以控制同时访问的线程个数,通过acquire()获取一个许可,如果没有就等待,而release()释放一个许可。
其实和锁有点类似,它一般用于控制对某组资源的访问权限。
适用场景:工厂有5 台机器,但是有8 个工人,一台机器同时只能被一个工人使用,只有使用完了,其他工人才能继续使用。
自旋锁与互斥锁的区别?
互斥锁:线程会从Sleep(加锁) -> Running (解锁), 过程又上下文切换,CPU抢占,信号发送等开销。
自旋锁:线程一直是Running(加锁->解锁),死循环检测锁的标志位。
公平锁与非公平锁的区别?
公平锁先到先得,按顺序进行(双向链表)。非公平是不排队直接获取锁。
Disruptor框架原理?
高性能队列,无锁机制(CAS),底层 ringbuffer(环形数组),基于事件驱动(观察者模式)。消息推送给消费者。
BlockingQueue阻塞队列,底层用锁。生产者->队列容器->消费者。
应用场景:Log4j2, Apache Storm等,它可以用来作为高性能的有界内存队列,基于生产者消费者模式,实现一个/多个生产者对应多个消费者。
它也可以认为是观察者模式的一种实现,或者发布订阅模式。
标签:标记 就是 缓存 pool 字节 适用于 运行 计数 cto
原文地址:https://www.cnblogs.com/fyql/p/11888262.html