标签:速度 str 简单 strong clear title 位置 优点 代码
优点:
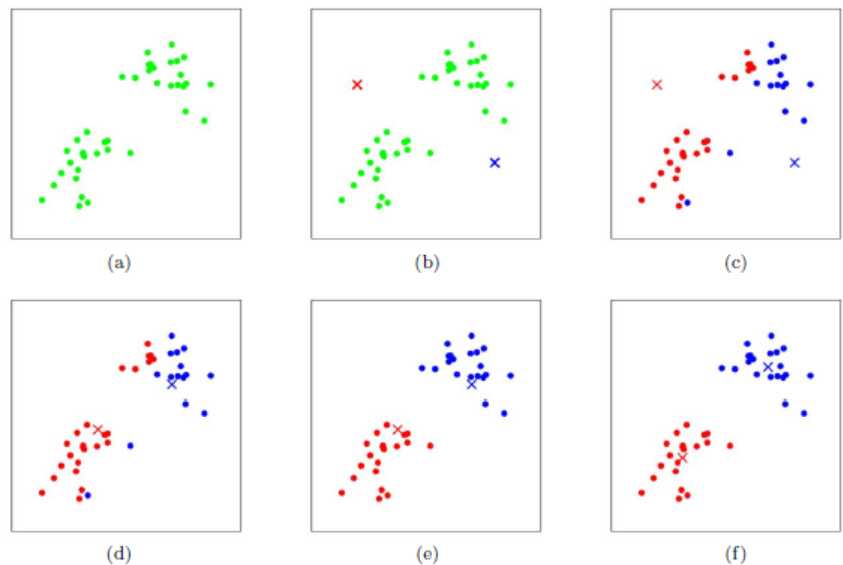
1、原理比较简单,实现也是很容易,收敛速度快。
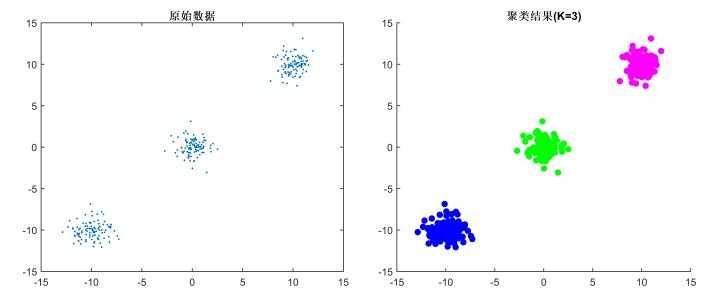
2、当结果簇是密集的,而簇与簇之间区别明显时, 它的效果较好。
3、主要需要调参的参数仅仅是簇数k。
缺点:
1、K值需要预先给定,很多情况下K值的估计是非常困难的。
2、K-Means算法对初始选取的质心点是敏感的,不同的随机种子点得到的聚类结果完全不同 ,对结果影响很大。
3、对噪音和异常点比较的敏感。用来检测异常值。
4、采用迭代方法,可能只能得到局部的最优解,而无法得到全局的最优解。
标签:速度 str 简单 strong clear title 位置 优点 代码
原文地址:https://www.cnblogs.com/dtmobile-ksw/p/11889802.html