标签:space nlog 标识 tle res 遇到 man form over
GTID是MySQL 5.6的新特性,其全称是Global Transaction Identifier,可简化MySQL的主从切换以及Failover。GTID用于在binlog中唯一标识一个事务。当事务提交时,MySQL Server在写binlog的时候,会先写一个特殊的Binlog Event,类型为GTID_Event,指定下一个事务的GTID,然后再写事务的Binlog。主从同步时GTID_Event和事务的Binlog都会传递到从库,从库在执行的时候也是用同样的GTID写binlog,这样主从同步以后,就可通过GTID确定从库同步到的位置了。也就是说,无论是级联情况,还是一主多从情况,都可以通过GTID自动找点儿,而无需像之前那样通过File_name和File_position找点儿了。
MySQL 5.6使用server_uuid和transaction_id两个共同组成一个GTID。即:GTID = server_uuid:transaction_id
server_uuid是MySQL Server的只读变量,保存在数据目录下的auto.cnf中,可直接通过cat命令查看。MySQL第一次启动时候创建auto.cnf文件,并生成server_uuid(MySQL使用机器网卡,当前时间,随机数等拼接成一个128bit的uuid,可认为在全宇宙都是唯一的,在未来一百年,使用同样的算法生成的uuid是不会冲突的)。之后MySQL再启动时不会重复生成uuid,而是使用auto.cnf中的uuid。也可以通过MySQL客户端使用如下命令查看server_uuid,看到的实际上是server_uuid的十六进制编码,总共16字节(其中uuid中的横线只是为了便于查看,并没有实际意义)。
|
1
2
3
4
5
6
7
|
mysql> show global variables like ‘server_uuid‘;+---------------+--------------------------------------+| Variable_name | Value |+---------------+--------------------------------------+| server_uuid | b3485508-883f-11e5-85fb-e41f136aba3e |+---------------+--------------------------------------+1 row in set (0.00 sec) |
在同一个集群内,每个MySQL实例的server_uuid必须唯一,否则同步时,会造成IO线程不停的中断,重连。在通过备份恢复数据时,一定要将var目录中的auto.cnf删掉,让MySQL启动时自己生成uuid。
GTID中还有一部分是transaction_id,同一个server_uuid下的transaction_id一般是递增的。如果一个事务是通过用户线程执行,那么MySQL在生成的GTID时,会使用它自己的server_uuid,然后再递增一个transaction_id作为该事务的GTID。当然,如果事务是通过SQL线程回放relay-log时产生,那么GTID就直接使用binlog里的了。在MySQL 5.6中不用担心binlog里没有GTID,因为如果从库开启了GTID模式,主库也必须开启,否则IO线程在建立连接的时候就中断了。5.6的GTID对MySQL的集群环境要求是非常严格的,要么主从全部开启GTID模式,要么全部关闭GTID模式。
刚才提到,同一个server_uuid下的transaction_id一般是递增的,难道在某些情况下不是递增的吗?答案是肯定的。MySQL支持通过设置Session级别的变量gtid_next,来指定下一个事务的GTID,格式就是‘server_uuid:transaction_id‘。之后还可以改回AUTOMATIC(默认值)
|
1
2
3
4
5
6
7
8
|
mysql> set gtid_next = ‘b694c8b2-883f-11e5-85fb-e41f136aba3e:12000005‘;Query OK, 0 rows affected (0.00 sec)mysql> begin;Query OK, 0 rows affected (0.00 sec)mysql> commit;Query OK, 0 rows affected (0.00 sec)mysql> set gtid_next = AUTOMATIC;Query OK, 0 rows affected (0.00 sec) |
一般设置gtid_next是加1,用于主从同步时跳过一个事务。但是如果设置gtid_next之后,导致当前server_uuid下的transaction_id不连续,那么坑爹的地方也就出现了。在改回AUTOMATIC以后,再有事务执行时,MySQL生成transaction_id时,不是按当前最大的transaction_id继续增长,而是补缺口(使用最小的缺失的那个transaction_id作为下一个gtid)。这样的话,即使是同一个server_uuid,也不能通过transaction_id的大小来判断事务的顺序。
使用server_uuid:transaction_id共同组成一个GTID的好处是,由于server_uuid唯一,即使一个集群内多个节点同时有写入,也不会造成GTID冲突。
MySQL通过全局变量gtid_mode控制开启/关闭GTID模式。但是gtid_mode是只读的,可添加到配置文件中,然后重启mysqld来开启GTID模式。相关配置项如下:
|
1
2
3
4
5
|
gtid-mode = ONenforce_gtid_consistency = 1log-slave-updates = 1log-bin = mysql-binlog-bin-index = mysql-bin.index |
配置方式为gtid_mode=ON/OFF。让人诧异的是gtid_mode的类型为枚举类型,枚举值可以为ON和OFF,所以应该通过ON或者OFF来控制gtid_mode,不要把它配置成0或者1,否则结果可能不符合你的预期。开启gtid_mode时,log-bin和log-slave-updates也必须开启,否则MySQL Server拒绝启动。除此以外,enforce-gtid-consistency也必须开启,否则MySQL Server也拒绝启动。enforce-gtid-consistency是因为开启grid_mode以后,许多MySQL的SQL和GTID是不兼容的。比如开启ROW 格式时,CREATE TABLE ... SELECT,在binlog中会形成2个不同的事务,GTID无法唯一。另外在事务中更新MyISAM表也是不允许的。
刚才已经提到,当开启GTID模式时,集群中的全部MySQL Server必须同时配置gtid_mod = ON,否则无法同步。
一旦使用GTID模式同步以后,主从切换就可以使用GTID来自动找点儿了,使用方式是在CHANGE MASTER时指定MASTER_AUTO_POSITION=1。命令如下:
|
1
2
3
4
5
6
|
mysql> CHANGE MASTER TO \ -> MASTER_HOST = ‘‘, \ -> MASTER_PORT = 3306, \ -> MASTER_USER = ‘test‘, \ -> MASTER_PASSWORD = ‘‘, \ -> MASTER_AUTO_POSITION = 1; |
通过SHOW SLAVE STATUS也可以看到Auto_Position: 1,说明以后START SLAVE将使用GTID自动找点儿,开启GTID之后原理上还支持使用FileName和FilePosition的方式找点儿,但是不建议使用。如果非要使用的话,在CHANGE MASTER的时候要指定MASTER_AUTO_POSITION=0
MySQL通过若干变量可以查看GTID的执行情况
|
1
2
3
4
5
6
7
8
9
10
|
mysql> show global variables like ‘gtid_%‘;+---------------+----------------------------------------------------------------------------------------------+| Variable_name | Value |+---------------+----------------------------------------------------------------------------------------------+| gtid_executed | b694c8b2-883f-11e5-85fb-e41f136aba3e:1-10114525:12000000-12000005 || gtid_mode | ON || gtid_owned | b694c8b2-883f-11e5-85fb-e41f136aba3e:10114523#10:10114525#6:10114521#5:10114524#8:10114522#4 || gtid_purged | b694c8b2-883f-11e5-85fb-e41f136aba3e:1-8993295 |+---------------+----------------------------------------------------------------------------------------------+4 rows in set (0.00 sec) |
这里有4个变量,其中gtid_mode已经介绍过了,其他3个变量的含义如下
gtid_executed:这既是一个Global级别的变量,又是一个Session级别的变量,是只读变量。Global级别的gtid_executed表示当前实例已经执行过的GTID集合。Session级别的gtid_executed一般情况下是空的。
gtid_owned:这既是一个Global级别的变量,又是一个Session级别的变量,是只读变量。Global级别的gtid_owned表示当前实例正在执行中的GTID,以及对应的线程id。Session级别的gtid_owned一般情况下是空的。
gtid_purged:这是一个Global级别的变量,可动态修改。我们知道binlog可以被purge掉,gtid_purged表示当前实例中已经被purge掉的GTID集合,很明显gtid_purged是gtid_executed的子集。但是gtid_purged也不是可以随意修改的,必须在@@global.gtid_executed是空的情况下,才可以动态设置gtid_purged。
通过前面的介绍可以知道,GTID可以在binlog中唯一标识一个事务,要了解GTID找点儿原理,就必须知道Binlog的格式,首先看一段Binlog
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
# at 120#151222 9:07:58 server id 1026872634 end_log_pos 247 CRC32 0xedf993a8 Previous-GTIDs# b3485508-883f-11e5-85fb-e41f136aba3e:1-14,# b694c8b2-883f-11e5-85fb-e41f136aba3e:1-10115960:12000000-12000005# at 247#151222 9:08:03 server id 1026872625 end_log_pos 295 CRC32 0xc3d3d8ee GTID [commit=yes]SET @@SESSION.GTID_NEXT= ‘b694c8b2-883f-11e5-85fb-e41f136aba3e:10115961‘/*!*/;# at 295#151222 9:08:03 server id 1026872625 end_log_pos 370 CRC32 0x0a32d229 Query thread_id=18 exec_time=1 error_code=0BEGIN/*!*/;# at 370#151222 9:08:03 server id 1026872625 end_log_pos 480 CRC32 0x3c0e094f Query thread_id=18 exec_time=1 error_code=0use `db`/*!*/;SET TIMESTAMP=1450746483/*!*/;update tb set val = val + 1 where id = 1/*!*/;# at 480#151222 9:08:03 server id 1026872625 end_log_pos 511 CRC32 0x5772f16b Xid = 6813913COMMIT/*!*/;# at 511#151222 9:10:19 server id 1026872625 end_log_pos 559 CRC32 0x3ac30191 GTID [commit=yes]SET @@SESSION.GTID_NEXT= ‘b694c8b2-883f-11e5-85fb-e41f136aba3e:10115962‘/*!*/;# at 559#151222 9:10:19 server id 1026872625 end_log_pos 634 CRC32 0x83a74912 Query thread_id=18 exec_time=0 error_code=0SET TIMESTAMP=1450746619/*!*/;BEGIN/*!*/;# at 634#151222 9:10:19 server id 1026872625 end_log_pos 744 CRC32 0x581f6031 Query thread_id=18 exec_time=0 error_code=0SET TIMESTAMP=1450746619/*!*/;update tb set val = val + 1 where id = 1/*!*/;# at 744#151222 9:10:19 server id 1026872625 end_log_pos 775 CRC32 0x793f8e34 Xid = 6813916COMMIT/*!*/; |
这段Binlog从文件120偏移处(Format_description_log_event之后的第一个Binlog Event)开始截取。可以看到,第一个Binlog Event的类型为:Previous-GTIDs,它存在于每个binlog文件中。当开启GTID时,每个binlog文件都有且只有一个Previous-GTIDs,位置都是在Format_description_log_event之后的第一个Binlog Event处。它的含义是在当前Binlog文件之前执行过的GTID集合,可以充当索引用,使用这个Binlog Event,可以便于快速判断GTID是否位于当前binlog文件中。
下面看看gtid_purged和gtid_executed是如何构造的。MySQL在启动时打开最老的binlog文件,读取其中的Previous-GTIDs,那么就是@@global.gtid_purged。MySQL在启动时打开最新的binlog文件,读取其中的Previous-GTIDs,构造一个gtid_set,然后再遍历这个最新的binlog文件,把遇到的每个gtid都添加到gtid_set中,当文件遍历完成时,这个gtid_set就是@@global.gtid_executed。
前面说过只有在@@global.gtid_executed为空的情况下,才可以动态设置@@global.gtid_purged。因此可以通过RESET MASTER的方式来清空@@global.gtid_executed。这一点,类似Ares中的命令:set binlog_group_id=XXX, master_server_id=YYY with reset;(是会删除binlog的)
通过解析上面的binlog文件,我们也可以看到,每个事务之前,都有一个GTID_log_event,用来指定GTID的值。总体来看,一个MySQL binlog的格式大致如下:
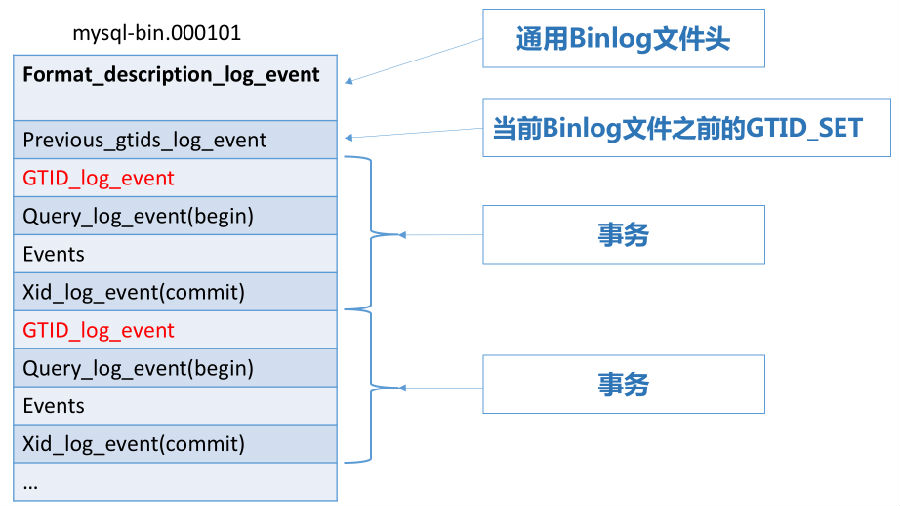
我们知道,在未开启GTID模式的情况下,从库用(File_name和File_pos)二元组标识执行到的位置。START SLAVE时,从库会先向主库发送一个BINLOG_DUMP命令,在BINLOG_DUMP命令中指定File_name和File_pos,主库就从这个位置开始发送binlog。
在开启GTID模式的情况下,如果指定MASTER_AUTO_POSITION=1。START SLAVE时,从库会计算Retrieved_Gtid_Set和Executed_Gtid_Set的并集(通过SHOW SLAVE STATUS可以查看),然后把这个GTID并集发送给主库。主库会使用从库请求的GTID集合和自己的gtid_executed比较,把从库GTID集合里缺失的事务全都发送给从库。如果从库缺失的GTID,已经被主库pruge了呢?从库报1236错误,IO线程中断。
通过GTID找到点儿的原理还是比较奇怪的,它过于强调主从binlog中GTID集合的一致性,弱化了Binlog执行的顺序性。
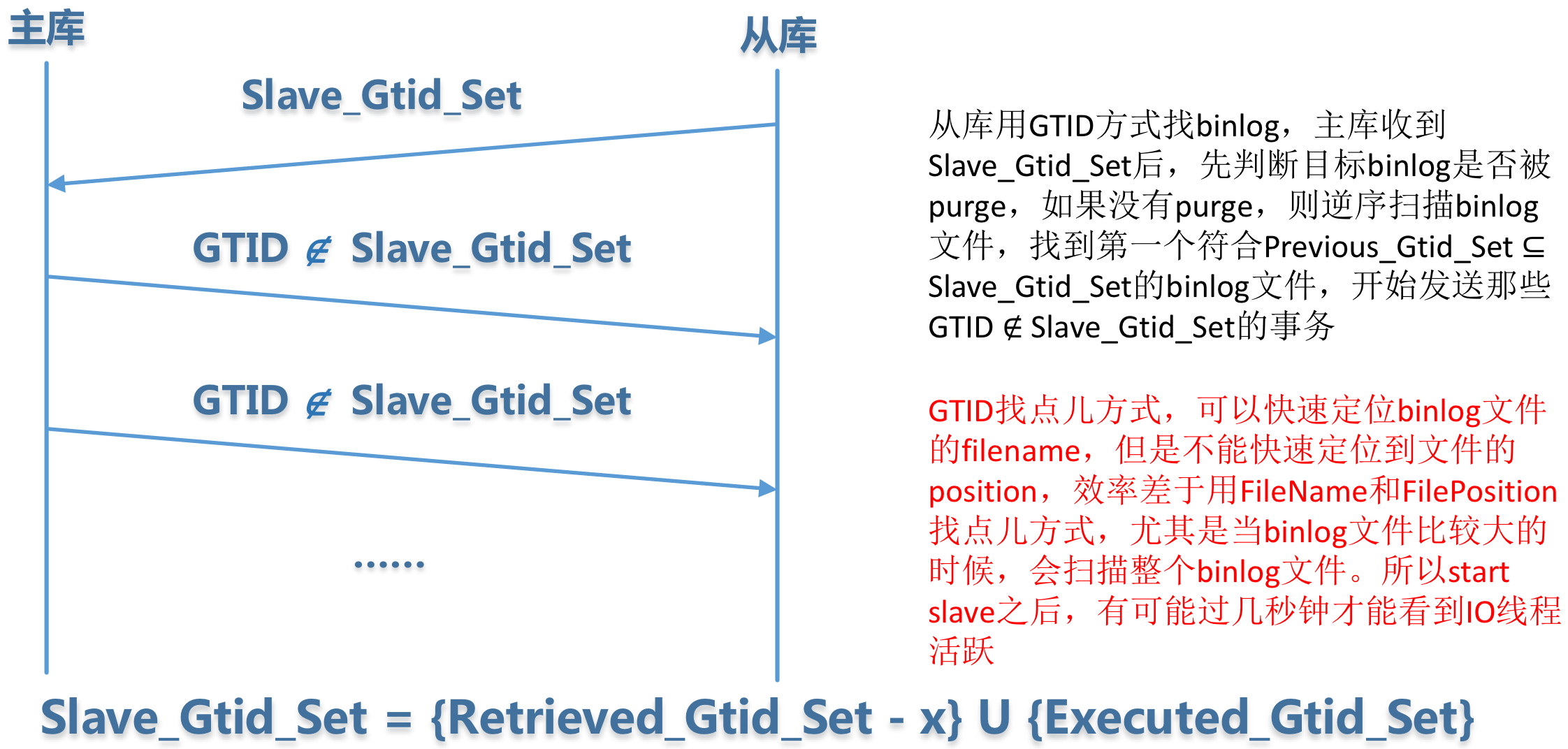
考虑下面这种情况,有个集群已经在使用GTID模式同步,小明想给集群增加一台从库,新做完一台从库,数据和主库一致,但是没有binlog,也就是说新从库的@@global.gtid_executed是空的。但是CHANGE MASTER时可以通过File_name和File_pos找到正确的同步点,然后START SLAVE,一切正常。过了一会儿,小明觉得还可以通过MASTER_AUTO_POSITION = 1的方式重新CHANGE MASTER,然后再START SLAVE。这种情况下,主库一看从库GTID里少了那么多binlog,然后把全部缺失的binglog再给从库发送一遍,那么悲剧就发生了。
为了解决这个问题,小明新做完从库以后,应该在从库上执行reset master; set global gtid_purged = ‘xxxxx‘,把缺失的GTID集合设置为purged,然后就可以直接使用MASTER_AUTO_POSITION=1自动找点儿了。
由此可见,开启GTID以后,Binlog和数据文件一样重要,不仅要求主从数据一致,还要求主从Binlog中GTID集合一致。
1)开启GTID以后,无法使用sql_slave_skip_counter跳过事务。前面介绍过了,使用GTID找点儿时,主库会把从库缺失的GTID,发送给从库,所以skip是没有用的。为了提前发现问题,MySQL在gtid模式下,直接禁止使用set global sql_slave_skip_counter = x。正确的做法是,通过set grid_next= ‘zzzz‘(‘zzzz‘为待跳过的事务),然后执行BIGIN;COMMIT产生一个空事务,占据这个GTID,再START SLAVE,会发现下一条事务的GTID已经执行过,就会跳过这个事务了
2)如果一个GTID已经执行过,再遇到重复的GTID,从库会直接跳过,可看作GTID执行的幂等性。
3)使用限制:https://dev.mysql.com/doc/refman/5.6/en/replication-gtids-restrictions.html
标签:space nlog 标识 tle res 遇到 man form over
原文地址:https://www.cnblogs.com/hankyoon/p/11905907.html