标签:缺点 汇总 指定 extra int 列表 ssi imp 文档

| 特征 | 科技(30篇) | 娱乐(60篇) | 汇总(90篇) |
|---|---|---|---|
| 商场 | 9 | 51 | 60 |
| 影院 | 8 | 56 | 64 |
| 支付宝 | 20 | 15 | 35 |
| 云计算 | 63 | 0 | 63 |
| 汇总(求和) | 100 | 121 | 221 |
现有一篇预测文档,出现了影院,支付宝,云计算,计算属于科技、娱乐的概率。
sklearn.naive_bayes.MultinomialNB (alpha = 1.0)
召回率(recall) - 真实为正例的样本中预测结果为正例的比例(查的全)

F1-score - 反映了模型的稳定性
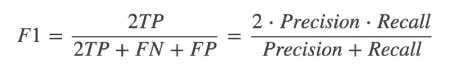
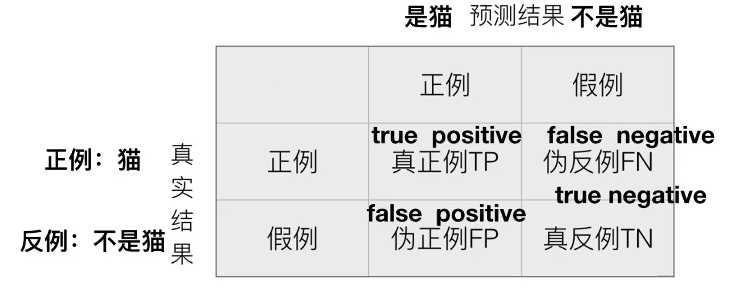
sklearn.metrics.classification_report(y_true, y_pred, target_names=None)
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
def naivebayes():
"""
朴素贝叶斯进行文本分类
:return: None
"""
news = fetch_20newsgroups(subset='all')
# 进行数据分割
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target_names, test_size=0.25 )
# 对数据集进行特征抽取
tf = TfidfVectorizer()
# 以训练集当中的词的列表进行每篇文章重要性统计
x_train = tf.fit_transform(x_train)
print(tf.get_feature_names())
x_test = tf.transform(x_test)
# 进行朴素贝叶斯算法的计算
mlt = MultinomialNB(alpha=1.0)
mlt.fit(x_train, y_train)
print(x_train)
y_predict = mlt.predict(x_test)
print("预测的文章类别为:", y_predict)
score = mlt.score(x_test, y_test)
print("分类准确率为:", score)
print("每个类别的精确率和召回率:", classification_report
(y_test,y_predict,target_names=news.target_names))
return None
if __name__ == '__main__':
naivebayes()标签:缺点 汇总 指定 extra int 列表 ssi imp 文档
原文地址:https://www.cnblogs.com/hp-lake/p/11909150.html