标签:code 列表 实现 int std sage bad 类型 bdc
#include <iostream> #include <string> using namespace std; void H_getMD5(const unsigned long Message[16]); static unsigned long State[4]; /* MD5值是由4个32bit的数组成的,也就是4个4Byte长的无符号整型 */ static unsigned long Count[2]; /* MD5算法除了要对原字符串按bit填充1和0之外,还需要在末尾附上64bit 的值,值是用字符串的bit长度 mod 2^64,这两整型是8byte,共64bit */ static unsigned char buffer[64]; /* MD5按每 512bit 一组来处理,这用来存放每组的 512bit */ /* Left_Shift表示,对x进行循环左移 n 位 */ #define Left_Shift(x,n) (((x)<<(n))|((x)>>(32-(n)))) /* F、G、H、I 4个函数是MD5的4个基本的非线性函数 */ #define F(x,y,z) (((x)&(y))|((~x)&(z))) #define G(x,y,z) (((x)&(z))|((y)&(~z))) #define H(x,y,z) ((x)^(y)^(z)) #define I(x,y,z) ((y)^((x)|(~z))) /* MD5主轮函数一共64次,每一次分别使用对应的位数来进行循环左移 */ const int shift_bit[64] = { 7 ,12,17,22, 7 ,12,17,22, 7 ,12,17,22, 7 ,12,17,22, 5 ,9 ,14,20, 5 ,9 ,14,20, 5 ,9 ,14,20, 5 ,9 ,14,20, 4 ,11,16,23, 4 ,11,16,23, 4 ,11,16,23, 4 ,11,16,23, 6 ,10,15,21, 6 ,10,15,21, 6 ,10,15,21, 6 ,10,15,21 }; /* ** K_Sin数组里存的是sin(i)*2^32的整数部分的绝对值, ** 提前打表,提高运行效率。 */ const unsigned long K_Sin[64] = { 0xd76aa478l, 0xe8c7b756l, 0x242070dbl, 0xc1bdceeel, 0xf57c0fafl, 0x4787c62al, 0xa8304613l, 0xfd469501l, 0x698098d8l, 0x8b44f7afl, 0xffff5bb1l, 0x895cd7bel, 0x6b901122l, 0xfd987193l, 0xa679438el, 0x49b40821l, 0xf61e2562l, 0xc040b340l, 0x265e5a51l, 0xe9b6c7aal, 0xd62f105dl, 0x02441453l, 0xd8a1e681l, 0xe7d3fbc8l, 0x21e1cde6l, 0xc33707d6l, 0xf4d50d87l, 0x455a14edl, 0xa9e3e905l, 0xfcefa3f8l, 0x676f02d9l, 0x8d2a4c8al, 0xfffa3942l, 0x8771f681l, 0x6d9d6122l, 0xfde5380cl, 0xa4beea44l, 0x4bdecfa9l, 0xf6bb4b60l, 0xbebfbc70l, 0x289b7ec6l, 0xeaa127fal, 0xd4ef3085l, 0x04881d05l, 0xd9d4d039l, 0xe6db99e5l, 0x1fa27cf8l, 0xc4ac5665l, 0xf4292244l, 0x432aff97l, 0xab9423a7l, 0xfc93a039l, 0x655b59c3l, 0x8f0ccc92l, 0xffeff47dl, 0x85845dd1l, 0x6fa87e4fl, 0xfe2ce6e0l, 0xa3014314l, 0x4e0811a1l, 0xf7537e82l, 0xbd3af235l, 0x2ad7d2bbl, 0xeb86d391l, }; /* ** 要对字符串按bit位填充一个1,然后紧接着若干个0, ** 使得它的bit长度 % 512 == 448,最多需要拼接512bit, ** 也就是 64 字节 */ const unsigned char PADDING[64] = { 0x80, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 }; void Encode(unsigned char* str_out, const unsigned long* ulong_in, int char_len) { /************************************************** @brief : 因为X86体系结构是小端模式,所以需要对输入的unsigned long数组进行字节序调整, 以满足可以按unsigned long为单位(按4字节为单位)读取。 @param[out] : 无 @param[in] : const unsigned long* ulong_in 需要调整字节序的unsigned long数组 @param[in] : unsigned char* str_out 已调整完字节序的字符数组 @param[in] : int char_len 以字符位单位的数组的长度 **************************************************/ //因为输入的字符串是4的倍数,所以肯定能被4整除 // circle_time是循环的次数,也就是 int circle_time = char_len / 4; for (int i = 0; i < circle_time; i++) { //取unsigned long的最低位的1字节 str_out[i*4] = (unsigned char)(ulong_in[i] & 0xff); //取unsigned long的次低位的1字节 str_out[i * 4 + 1] = (unsigned char)((ulong_in[i] >> 8) & 0xff); //取unsigned long的次高位的1字节 str_out[i * 4 + 2] = (unsigned char)((ulong_in[i] >> 16) & 0xff); //取unsigned long的最高位的1字节 str_out[i * 4 + 3] = (unsigned char)((ulong_in[i] >> 24) & 0xff); } } void Decode(unsigned long* ulong_out, const unsigned char* str_in, int char_len) { /************************************************** @brief : 因为X86体系结构是小端模式,所以需要对输入的unsigned char数组进行字节序调整, 以满足可以按unsigned long为单位(按4字节为单位)读取。 @param[out] : 无 @param[in] : const unsigned char* str_in 需要调整字节序的unsigned char数组 @param[in] : unsigned long* ulong_out 已调整完字节序的unsigned long数组 @param[in] : int char_len 以字符位单位的数组的长度 **************************************************/ //因为输入的字符串也肯定是4的倍数,所以肯定能被4整除 // circle_time是循环的次数,也就是 int circle_time = char_len / 4; for (int i = 0; i < circle_time; i++) { ulong_out[i] = ((unsigned long)str_in[i * 4]) | (((unsigned long)str_in[i * 4 + 1]) << 8) | (((unsigned long)str_in[i * 4 + 2]) << 16) | (((unsigned long)str_in[i * 4 + 3]) << 24); } } void Transform_64(const unsigned char block[64]) { /************************************************** @brief : 将512bit转换成可以(在小端模式下)按照64bit为单位正确读取的字节序 @param[out] : 无 @param[in] : const unsigned char block[64] 输入是以字节为单位排序的512bit **************************************************/ //新建一个512bit的数组用以保存调整好的字节序 unsigned long Message[16]; //进行调整 Decode(Message, block, 64); //对调整完的字节序进行主轮函数(每一主轮函数共有64次运算) H_getMD5(Message); } void H_getMD5(const unsigned long Message[16]) { /************************************************** @brief : 输入一组512bit的数据,进行64次运算,更新State[0]~State[3] @param[out] : 无 @param[in] : unsigned long Message[16],4字节*16=64字节,等于512bit **************************************************/ unsigned long A = State[0], B = State[1], C = State[2], D = State[3]; unsigned long Func; int g; for (int i = 0; i < 64; i++) { //64次运算,每轮16次 if (i < 16) { //第一轮 Func = F(B, C, D); g = i; } else if (i < 32) { //第二轮 Func = G(B, C, D); g = (5 * i + 1) % 16; } else if (i < 48) { //第三轮 Func = H(B, C, D); g = (3 * i + 5) % 16; } else { //第四轮 Func = I(B, C, D); g = (7 * i) % 16; } unsigned long temp = D; D = C; C = B; B = B + Left_Shift(A + Func + K_Sin[i] + Message[g], shift_bit[i]); A = temp; } State[0] += A; State[1] += B; State[2] += C; State[3] += D; } void Init_State() /************************************************** @brief : 初始化MD5的State[0]、State[1]、State[2]、State[3],和Count[0]、Count[1] @param[out] : 无 @param[in] : 无 **************************************************/ { Count[0] = 0; Count[1] = 0; /* 初始化State[]为各自对应的4个幻数 */ State[0] = 0x67452301lL; State[1] = 0xefcdab89lL; State[2] = 0x98badcfelL; State[3] = 0x10325476lL; } void Update(const unsigned char* input, int inputLen) /************************************************** @brief : 最后一次的512bit运算,要对字符串追加100...00比特流和64bit长度, 再继续运算即可求得MD5值 @param[out] : 无 @param[in] : const unsigned char* input 表示要填充进buffer[64]数组里的字符串 @param[in] : int inputLen 表示要填充进buffer[64]数组里的字符串的长度 **************************************************/ { int i,index, partLen; /* 用 index 保存未更新前的Count[0]里记录的字节数 */ index = (unsigned int)((Count[0] >> 3) & 0xFF); /* * 更新Count[0],因为要拼接上inputLen长度的字节 */ Count[0] += ((unsigned long)inputLen << 3); if (Count[0] < ((unsigned long)inputLen << 3)) { //如果小于,说明Count[0]溢出了,所以Count[1]需要加1 Count[1]++; } /* * Count[1]和Count[0]都是4字节32bit长的,把它们放在一起看,就是一个64bit的长度, * Count[1] 增1,表示字符串的bit长度要增加 1*2^32次方,inputLen是要在字符串后面 * 增加的字符串字节长度,inputLen先<<3,再>>32,就是Count[1]要增加的数目了 */ Count[1] += ((unsigned long)inputLen >> 29); // partLen表示还缺多少个字节,才够512bit(一组) partLen = 64 - index; /* Transform as many times as possible. */ if (inputLen >= partLen) //如果inputLen(要更新的字节数)大于等于缺的字节数,那也意味目前够512bit(一组)了 { //分阶段把数据填入buffer里。因为buffer只有512bit,所以要分批 memcpy(&buffer[index], input, partLen); Transform_64(buffer); for (i = partLen; i + 63 <= inputLen; i += 64) { Transform_64(&(input[i])); } index = 0; } else { i = 0; } /* * 上面的都是按照一整组一整组来处理的, * 有可能剩下的,不够一整组,需要对剩下的单独处理, */ if ((inputLen - i) != 0) { memcpy(&buffer[index], &input[i], inputLen - i); } } void Final(unsigned char digest[16]) /************************************************** @brief : 最后一次的512bit运算,要对字符串追加100...00比特流和64bit长度, 再继续运算即可求得MD5值 @param[out] : 无 @param[in] : unsigned char digest[16] 表示用来存放最终MD5值的字符数组 **************************************************/ { unsigned char ulong2uchar[8]; int char_len, padLen; /** 把unsigned long类型的Count数组里的值,转换成在小端模式下, ** 使其以usnigned char为单位,也能正常读取。 **/ Encode(ulong2uchar, Count, 8); /** 填充100000..000的比特流,使得字符串的bit长度 % 512 == 448 ** 也就是字节的长度 % 64 == 56 **/ //Count里存的是字符串的bit长度,>>3的结果是字节长度 char_len = (int)((Count[0] >> 3) & 0x3f); //padLen表示要填充的字节的长度,如果char_len<56,只需要补齐到56字节就行 //如果char_len ≥ 56,那么总共的组数就要再多一组(512bit)了, //要填充的字节数是(64-(char_len - 56)),也就是(120 - char_len) padLen = (char_len < 56) ? (56 - char_len) : (120 - char_len); /** ** 给字符串加上要填充的100..000的bit,只是按照字节的形式填充而已, ** padLen是 要填充的bit长度 除以 8,也就是要填充的字节长度 **/ Update(PADDING, padLen); /** ** 给字符串加上64bit(也就是8字节)的长度, ** 如果长度大于2^64,只取长度的低64位 **/ Update(ulong2uchar, 8); /* ** 把运算出来的最终的State数组,存放在digest里 ** 同时调成在小端模式下,以字节为单位,也能正确读取出来 */ Encode(digest, State, 16); } void Data(const unsigned char* data, int len, unsigned char digest[16]) /************************************************** @brief : 调度MD5核心算法 @param[out] : 无 @param[in] : const char* data 表示要进行MD5运算的字符串 @param[in] : int len 表示要进行MD5运算的字符串的长度 @param[in] : unsigned char digest[16] 表示用来存放最终MD5值的字符数组 **************************************************/ { Init_State(); //初始化State数组和Count数组 Update(data, len); //把要进行MD5运算的字符串,填写到buffer[64]数组里 Final(digest); //最后一次主轮函数,要对字符串追加100...00比特流和64bit长度, //再继续运算即可求得MD5值 } char* getMD5(const char* data, int len, char* buf) { /************************************************** @brief : 得到字符串的MD5值 @param[out] : char* 返回一个指向32个小写字符的字符指针,每个字符的范围是(0~f) @param[in] : const char* data 表示要进行MD5运算的字符串 @param[in] : int len 表示要进行MD5运算的字符串的长度 @param[in] : char* buf 表示用来存放最终MD5值的字符指针 **************************************************/ unsigned char digest[16]; Data((const unsigned char*)data, len, digest); char* p = buf; for (int i = 0; i < 16; i++) { *p = "0123456789abcdef"[digest[i] >> 4]; p++; *p = "0123456789abcdef"[digest[i] & 0x0f]; p++; } *p = 0; return buf; } int main() { char* out = new char[1000]; const char* str = "0123456789"; cout << getMD5(str, strlen(str), out) << endl; delete[] out; return 0; } // 运行程序: Ctrl + F5 或调试 >“开始执行(不调试)”菜单 // 调试程序: F5 或调试 >“开始调试”菜单 // 入门使用技巧: // 1. 使用解决方案资源管理器窗口添加/管理文件 // 2. 使用团队资源管理器窗口连接到源代码管理 // 3. 使用输出窗口查看生成输出和其他消息 // 4. 使用错误列表窗口查看错误 // 5. 转到“项目”>“添加新项”以创建新的代码文件,或转到“项目”>“添加现有项”以将现有代码文件添加到项目 // 6. 将来,若要再次打开此项目,请转到“文件”>“打开”>“项目”并选择 .sln 文件
代码里包含一次测试用例,测试的字符串为“0123456789”,运算结果为“781e5e245d69b566979b86e28d23f2c7”。
和在网上随便找的网站对同一字符串进行MD5消息摘要运算,结果一致。
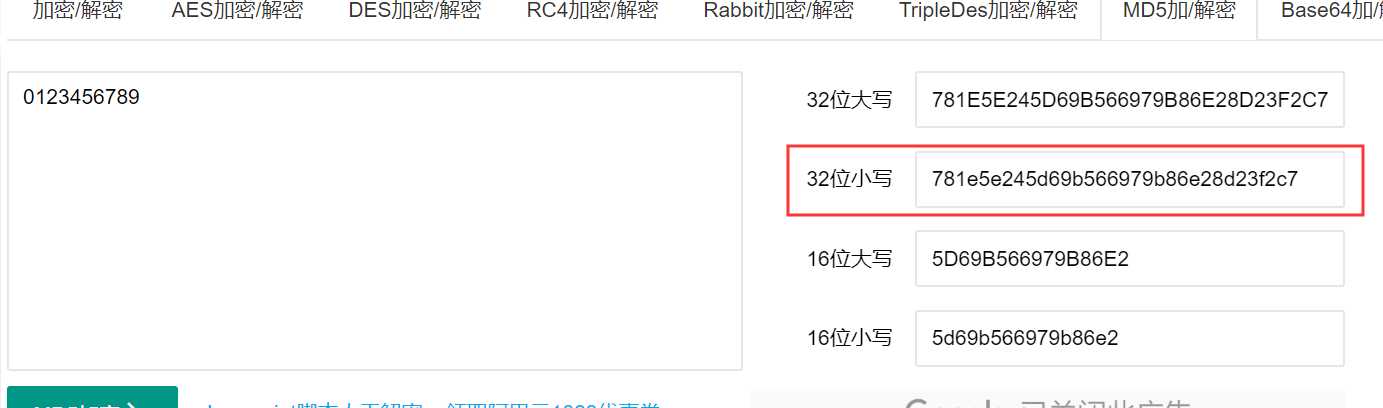
所以,代码本身逻辑本身大概率是没有问题。
有问题欢迎指出。
标签:code 列表 实现 int std sage bad 类型 bdc
原文地址:https://www.cnblogs.com/blockchainchain/p/11915125.html