标签:例子 优化 日志文件 jni 建立 保存 赋值 不能 lcis
在了解了mongodb的基本使用之后,我们看一下mongodb的存储引擎。从更深层次了解mongodb的数据处理机制,也在mongodb出现数据丢失等情况时,便于对问题进行排查。
1、存储引擎wiredTiger
mongodb从3.0开始引入了可插拔存储引擎的概念。目前主要有MMAPV1、WiredTiger两种引擎可供选择。在3.2版本之前默认引擎为MMAPV1,采用linux操作系统内存映射技术,但一直饱受诟病;3.4以上版本默认存储引擎是wiredTiger,相对于MMAPV1有以下优势:
a、读写操作性能更好,wiredTiger能更好的发挥多核系统的处理能力;
b、MMAPV1引擎使用表级锁,当某个单表上有并发的操作,吞吐将受到限制。wiredTiger使用文档级锁,由此带来并发及吞吐量的提升;
c、相比MMAPV1,wiredTIger使用了前缀压缩,更节省对内存空间的消耗;
d、提供压缩算法,可大大降低对硬盘资源的消耗,节省60%以上的硬盘资源;
2、为什么会丢失数据?
wiredTiger写入模型:
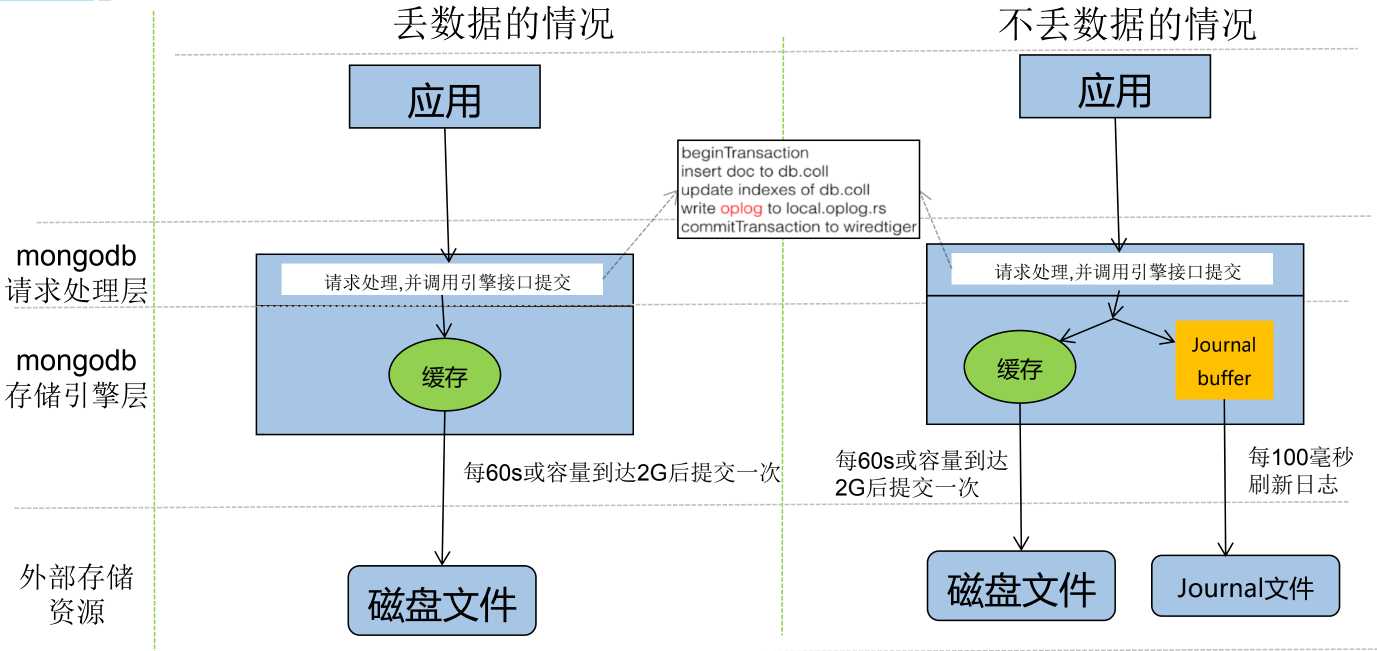
注意,请求处理层跟存储引擎是不在一起的,处理层可以认为是一个"外壳",主要负责对外部请求的响应。处理层只是吧数据放到了缓存,真实数据的处理是引擎来做的。
处理层的处理:接收到外部请求,开启一个事务;将数据插入或者更新到集合,更新索引,将操作写入操作日志;最后提交事务,返回外部请求。注意这里的事务只是相对于mongodb内部来说的,不是使用mongodb的程序的那个事务。
处理层提交了事务后,外部请求就返回了,不会等待引擎的处理。数据在处理层提交事务后会转交给引擎,引擎会每隔60秒或者容量达到2G的时候将数据写入磁盘一次(看哪一个先达到),如果在引擎还没有来得及刷新数据到磁盘的时候,服务器发生了异常,比如断电等,就会引起数据丢失。
如何应对这种情况呢?开启日志journaling。mongodb2.4之后是默认开启的。
Journaling类似于关系数据库中的事务日志。Journaling能够使MongoDB数据库由于意外故障后快速恢复。MongoDB2.4版本后默认开启了Journaling日志功能,mongod实例每次启动时都会检查journal日志文件看是否需要恢复。由于提交journal日志会产生写入阻塞,所以它对写入的操作有性能影响,但对于读没有影响。在生产环境中开启Journaling是很有必要的。
在开启journaling后请求处理层的基本逻辑并没有什么变化,只是在将数据提交给引擎的时候,会同时写到一个缓冲区,通常叫做journaling buffer;写到缓存的数据会继续60秒或者累计2G的策略进行出处,完成后会删除对应的journal文件内容;跟存储引擎不同,journalbuffer每100ms刷新一次,将数据刷入一个journal文件。mongodb实例每次启动时都会检查journal日志文件是否需要恢复。从这个逻辑上讲,mongodb最多只会丢失100ms的数据,有些时候,这是可以容忍的(金融等绝对不能容忍)。
3、写策略
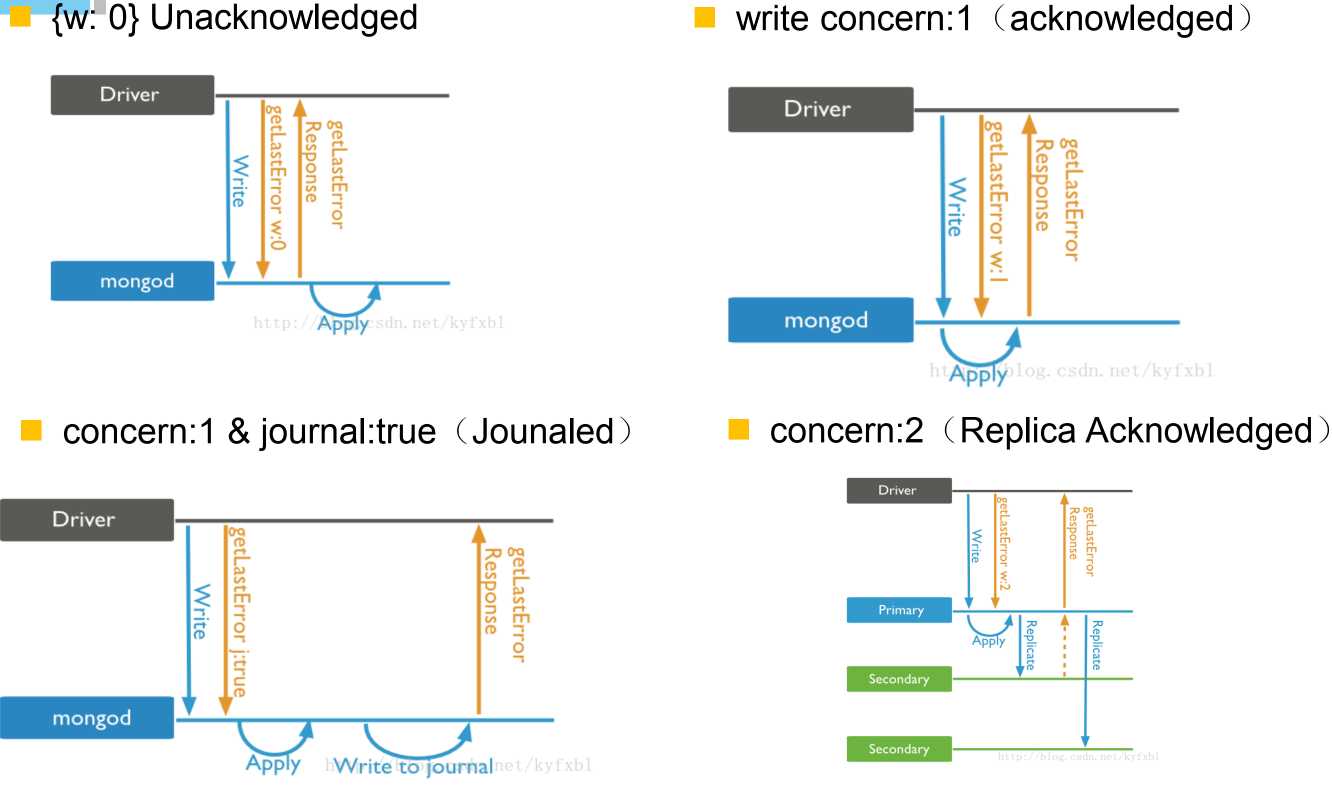
a、unacknowledged,不确认模式
请求到达mongodb后,直接返回,不会等待请求处理层是否将数据提交给引擎进行处理;
b、acknowledged,确认模式;确认写到了存储引擎的缓存;默认为确认模式;
c、concern:1 & journal:true 日志模式,确认写到了缓存跟journal文件;
d、concern:2 复制确认模式;
在多机主从配置的情况下,不但要确认当前机器将数据写入,还要从机也确认写入,才将请求返回。
写策略有很多,默认为单机确认模式;mongodb的写策略可以在WriteConcern.class(驱动里有)文件中查看到。集群环境下,可以配置为major,即为大部分服务器返回确认应答即返回;如果对性能要求高,可以配置w1,也就是写服务器的master确认了即可,不等从机确认。
说了这么多,journal如何进行配置?
配置都在mongodb.conf中即可,只要启动的时候指定使用这个配置文件即可;
storage:
journal:
enabled: true
dbPath: /data/zhou/mongo1/
##是否一个库一个文件夹
directoryPerDB: true
##数据引擎
engine: wiredTiger
##WT引擎配置
WiredTiger:
engineConfig:
##WT最大使用cache(根据服务器实际情况调节)
cacheSizeGB: 1
##是否将索引也按数据库名单独存储
directoryForIndexes: true
journalCompressor:none (默认snappy)
##表压缩配置
collectionConfig:
blockCompressor: zlib (默认snappy,还可选none、zlib)
##索引配置
indexConfig:
prefixCompression: true
以上配置跟当前使用版本不对应,暂时不去校对了,以后用到了再试~~
4、索引命令概要与类型
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。索引主要用于排序和检索
索引分类:单键索引、复合索引、多键索引跟哈希索引
单键索引:在某一特定属性上建立的索引;
复合索引:在多个特定属性上建立的索引。复合索引键的排序顺序,可以确定该索引是否可以支持排序操作;在索引字段上进行精确匹配、排序以及范围查找都会使用此索引,但与索引的顺序有关;为了性能考虑,应删除存在与第一个键相同的单键索引。
多键索引:在数组的属性上建立索引,例如:db.users. createIndex({favorites.city:1的查询都会定位到这个文档,既多个索引入口或者键值引用同一个。
哈希索引:跟哈希表原理类似。在索引字段上进行精确匹配,但不支持范围查询,不支持多键hash;Hash索引上的入口是均匀分布的,在分片集合中非常有用;
5、查询优化处理
a、开启内置的查询分析器,记录读写操作效率:
db.setProfilingLevel(n,{m}),n的取值可选0,1,2;
0是默认值表示不记录;
1表示记录慢速操作,如果值为1,m必须赋值单位为ms,用于定义慢速查询时间的阈值;
2表示记录所有的读写操作;
例如:db.setProfilingLevel(1,300)
b、查询监控结果
监控结果保存在一个特殊的盖子集合system.profile里,这个集合分配了128kb的空间,要确保监控分析数据不会消耗太多的系统性资源;盖子集合维护了自然的插入顺序,可以使用$natural操作符进行排序,如:db.system.profile.find().sort({‘$natural‘:-1}).limit(5)
盖子集合 Tips:
1. 大小或者数量固定;(设定存储条数或者容量(比如1M))
2. 不能做update和delete操作;
3. 容量满了以后,按照时间顺序,新文档会覆盖旧文档;
例子:使用explain分析慢速查询
例如:db.orders.find({‘price‘:{‘$lt‘:2000}}).explain(‘executionStats‘)
explain的入参可选值为:
"queryPlanner" 是默认值,表示仅仅展示执行计划信息;
"executionStats" 表示展示执行计划信息同时展示被选中的执行计划的执行情况信息;
"allPlansExecution" 表示展示执行计划信息,并展示被选中的执行计划的执行情况信息,还展示备选的执行计划的执行情况信息;
解读explain结果
queryPlanner(执行计划描述)
winningPlan(被选中的执行计划)
stage(可选项:COLLSCAN 没有走索引;IXSCAN使用了索引)
rejectedPlans(候选的执行计划)
executionStats(执行情况描述)
nReturned (返回的文档个数)
executionTimeMillis(执行时间ms)
totalKeysExamined (检查的索引键值个数)
totalDocsExamined (检查的文档个数)
优化目标 :
1. 根据需求建立索引
2. 每个查询都要使用索引以提高查询效率, winningPlan. stage 必须为IXSCAN ;
3. 追求totalDocsExamined = nReturned;
5、关于索引的建议
1. 索引很有用,但是它也是有成本的——它占内存,让写入变慢;
2. mongoDB通常在一次查询里使用一个索引,所以多个字段的查询或者排序需要复合索引才能更加高效;
3. 复合索引的顺序非常重要
4. 在生成环境构建索引往往开销很大,时间也不可以接受,在数据量庞大之前尽量进行查询优化和构建索引;
5. 避免昂贵的查询,使用查询分析器记录那些开销很大的查询便于问题排查;
6. 通过减少扫描文档数量来优化查询,使用explai对开销大的查询进行分析并优化;
7. 索引是用来查询小范围数据的,不适合使用索引的情况:
a、每次查询都需要返回大部分数据的文档,避免使用索引
b、写比读多
mongodb存储引擎
标签:例子 优化 日志文件 jni 建立 保存 赋值 不能 lcis
原文地址:https://www.cnblogs.com/nevermorewang/p/11922813.html