标签:征文 out 解压 nbsp utf-8 filename style 压缩 后缀
常说的python-docx库并不好。我使用的时候碰到了部分文字未读取的情况。其实完全可以不用这个包。
doc文档本身是一个压缩包,改后缀为zip后,可解压看其中的内容:
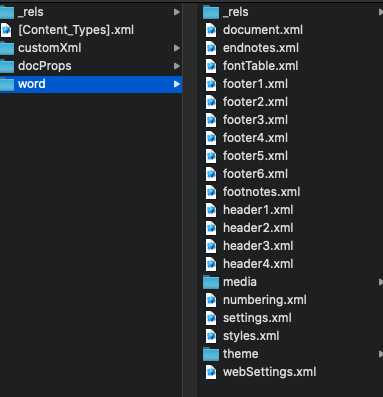
xml格式我不了解,基本上征文所有的文字都在document.xml文档中,页眉页脚在header和footer中,写一个文档改变其中的值就行了。
这其中可以用库来快速操作:zipfile。可以免去解压什么的繁琐步骤。
def docx_replace(old_file,new_file,rep): zin = zipfile.ZipFile (old_file, ‘r‘) zout = zipfile.ZipFile (new_file, ‘w‘) for item in zin.infolist(): buffer = zin.read(item.filename) if (item.filename == ‘word/document.xml‘ or ‘header‘ in item.filename): res = buffer.decode("utf-8") for r in rep: res = res.replace(r,rep[r]) buffer = res.encode("utf-8") zout.writestr(item, buffer) zout.close() zin.close()
做替换,rep是替换前后内容的dict。
so easy
标签:征文 out 解压 nbsp utf-8 filename style 压缩 后缀
原文地址:https://www.cnblogs.com/waldenlake/p/11937567.html