标签:虚拟 return pup osc 默认 对象 oda 开启 session

为获得良好的阅读体验,请访问原文: 传送门
前序文章
上一篇文章我们提到一个应用可以创建多个线程去执行不同的任务,如果这些任务之间有着某种关系,那么线程之间必须能够通信来协调完成工作。
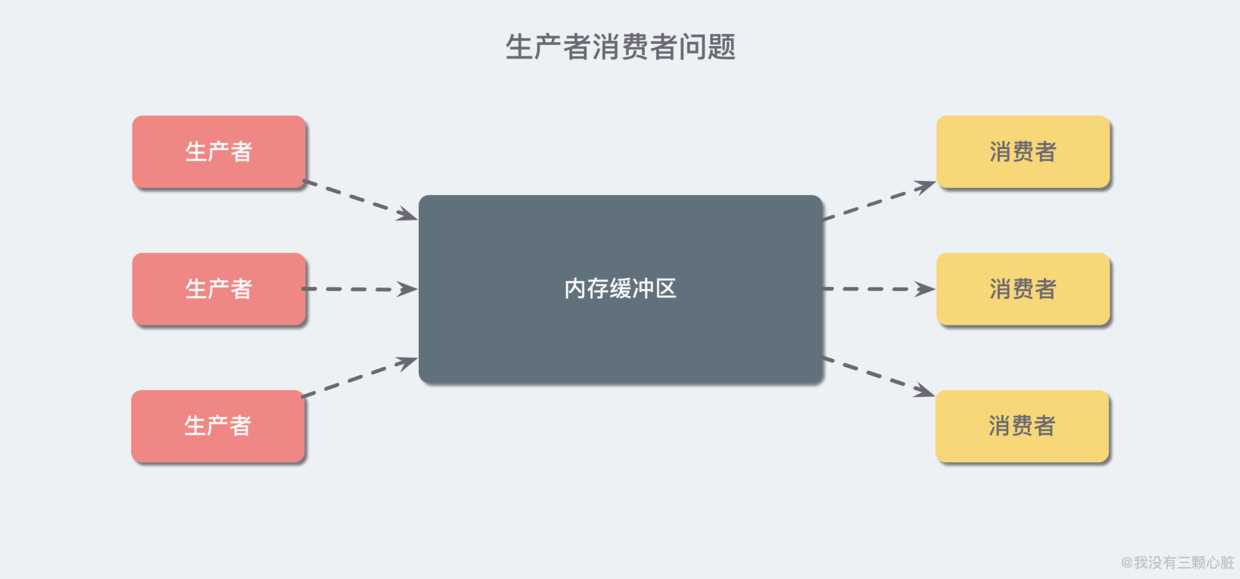
生产者消费者问题(英语:Producer-consumer problem)就是典型的多线程同步案例,它也被称为有限缓冲问题(英语:Bounded-buffer problem)。该问题描述了共享固定大小缓冲区的两个线程——即所谓的“生产者”和“消费者”——在实际运行时会发生的问题。生产者的主要作用是生成一定量的数据放到缓冲区中,然后重复此过程。与此同时,消费者也在缓冲区消耗这些数据。该问题的关键就是要保证生产者不会在缓冲区满时加入数据,消费者也不会在缓冲区中空时消耗数据。(摘自维基百科:生产者消费者问题)
我们来自己编写一个例子:一个生产者,一个消费者,并且让他们让他们使用同一个共享资源,并且我们期望的是生产者生产一条放到共享资源中,消费者就会对应地消费一条。
我们先来模拟一个简单的共享资源对象:
public class ShareResource {
private String name;
private String gender;
/**
* 模拟生产者向共享资源对象中存储数据
*
* @param name
* @param gender
*/
public void push(String name, String gender) {
this.name = name;
this.gender = gender;
}
/**
* 模拟消费者从共享资源中取出数据
*/
public void popup() {
System.out.println(this.name + "-" + this.gender);
}
}然后来编写我们的生产者,使用循环来交替地向共享资源中添加不同的数据:
public class Producer implements Runnable {
private ShareResource shareResource;
public Producer(ShareResource shareResource) {
this.shareResource = shareResource;
}
@Override
public void run() {
for (int i = 0; i < 50; i++) {
if (i % 2 == 0) {
shareResource.push("凤姐", "女");
} else {
shareResource.push("张三", "男");
}
}
}
}接着让我们的消费者不停地消费生产者产生的数据:
public class Consumer implements Runnable {
private ShareResource shareResource;
public Consumer(ShareResource shareResource) {
this.shareResource = shareResource;
}
@Override
public void run() {
for (int i = 0; i < 50; i++) {
shareResource.popup();
}
}
}然后我们写一段测试代码,来看看效果:
public static void main(String[] args) {
// 创建生产者和消费者的共享资源对象
ShareResource shareResource = new ShareResource();
// 启动生产者线程
new Thread(new Producer(shareResource)).start();
// 启动消费者线程
new Thread(new Consumer(shareResource)).start();
}我们运行发现出现了诡异的现象,所有的生产者都似乎消费到了同一条数据:
张三-男
张三-男
....以下全是张三-男....为什么会出现这样的情况呢?照理说,我的生产者在交替地向共享资源中生产数据,消费者也应该交替消费才对呀..我们大胆猜测一下,会不会是因为消费者是直接循环了 30 次打印共享资源中的数据,而此时生产者还没有来得及更新共享资源中的数据,消费者就已经连续打印了 30 次了,所以我们让消费者消费的时候以及生产者生产的时候都小睡个 10 ms 来缓解消费太快 or 生产太快带来的影响,也让现象更明显一些:
/**
* 模拟生产者向共享资源对象中存储数据
*
* @param name
* @param gender
*/
public void push(String name, String gender) {
try {
Thread.sleep(10);
} catch (InterruptedException ignored) {
}
this.name = name;
this.gender = gender;
}
/**
* 模拟消费者从共享资源中取出数据
*/
public void popup() {
try {
Thread.sleep(10);
} catch (InterruptedException ignored) {
}
System.out.println(this.name + "-" + this.gender);
}再次运行代码,发现了出现了以下的几种情况:
this.name = name),也就是还没有来得及给 gender 赋值就被消费者给取走消费了.. 造成这样情况的根本原因是没有保证生产者生产数据的原子性。我们先来解决性别紊乱,也就是原子性的问题吧,上一篇文章里我们也提到了,对于这样的原子性操作,解决方法也很简单:加锁。稍微改造一下就好了:
/**
* 模拟生产者向共享资源对象中存储数据
*
* @param name
* @param gender
*/
synchronized public void push(String name, String gender) {
this.name = name;
try {
Thread.sleep(10);
} catch (InterruptedException ignored) {
}
this.gender = gender;
}
/**
* 模拟消费者从共享资源中取出数据
*/
synchronized public void popup() {
try {
Thread.sleep(10);
} catch (InterruptedException ignored) {
}
System.out.println(this.name + "-" + this.gender);
}synchronized 关键字,来保证每一次读取和修改都只能是一个线程,这是因为当 synchronized 修饰在普通同步方法上时,它会自动锁住当前实例对象,也就是说这样改造之后读/ 写操作同时只能进行其一;push 方法小睡的代码改在了赋值 name 和 gender 的中间,以强化验证原子性操作是否成功,因为如果不是原子性的话,就很可能出现赋值 name 还没赋值给 gender 就被取走的情况,小睡一会儿是为了加强这种情况的出现概率(可以试着把 synchronized 去掉看看效果);运行代码后发现,并没有出现性别紊乱的现象了,但是重复消费仍然存在。
我们期望的是 张三-男 和 凤姐-女 交替出现,而不是有重复消费的情况,所以我们的生产者和消费者之间需要一点沟通,最容易想到的解决方法是,我们新增加一个标志位,然后在消费者中使用 while 循环判断,不满足条件则不消费,条件满足则退出 while 循环,从而完成消费者的工作。
while (value != desire) {
Thread.sleep(10);
}
doSomething();这样做的目的就是为了防止「过快的无效尝试」,这种方法看似能够实现所需的功能,但是却存在如下的问题:
以上两个问题吗,看似矛盾难以调和,但是 Java 通过内置的等待/ 通知机制能够很好地解决这个矛盾并实现所需的功能。
等待/ 通知机制,是指一个线程 A 调用了对象 O 的 wait() 方法进入等待状态,而另一个线程 B 调用了对象 O 的 notifyAll() 方法,线程 A 收到通知后从对象 O 的 wait() 方法返回,进而执行后续操作。上述两个线程都是通过对象 O 来完成交互的,而对象上的 wait 和 notify/ notifyAll 的关系就如同开关信号一样,用来完成等待方和通知方之间的交互工作。
这里有一个比较奇怪的点是,为什么看起来像是线程之间操作的
wait和notify/ notifyAll方法会是Object类中的方法,而不是Thread类中的方法呢?
- 简单来说:因为
synchronized中的这把锁可以是任意对象,因为要满足任意对象都能够调用,所以属于Object类;- 专业点说:因为这些方法在操作同步线程时,都必须要标识它们操作线程的锁,只有同一个锁上的被等待线程,可以被同一个锁上的
notify唤醒,不可以对不同锁中的线程进行唤醒。也就是说,等待和唤醒必须是同一个锁。而锁可以是任意对象,所以可以被任意对象调用的方法是定义在Object类中。
好,简单介绍完等待/ 通知机制,我们开始改造吧:
public class ShareResource {
private String name;
private String gender;
// 新增加一个标志位,表示共享资源是否为空,默认为 true
private boolean isEmpty = true;
/**
* 模拟生产者向共享资源对象中存储数据
*
* @param name
* @param gender
*/
synchronized public void push(String name, String gender) {
try {
while (!isEmpty) {
// 当前共享资源不为空的时,则等待消费者来消费
// 使用同步锁对象来调用,表示当前线程释放同步锁,进入等待池,只能被其他线程所唤醒
this.wait();
}
// 开始生产
this.name = name;
Thread.sleep(10);
this.gender = gender;
// 生产结束
isEmpty = false;
// 生产结束唤醒一个消费者来消费
this.notify();
} catch (Exception ignored) {
}
}
/**
* 模拟消费者从共享资源中取出数据
*/
synchronized public void popup() {
try {
while (isEmpty) {
// 为空则等着生产者进行生产
// 使用同步锁对象来调用,表示当前线程释放同步锁,进入等待池,只能被其他线程所唤醒
this.wait();
}
// 消费开始
Thread.sleep(10);
System.out.println(this.name + "-" + this.gender);
// 消费结束
isEmpty = true;
// 消费结束唤醒一个生产者去生产
this.notify();
} catch (InterruptedException ignored) {
}
}
}isEmpty),并且通知所有等待在对象上的线程;notify() 方法,这是因为例子中写死了只有一个消费者和生产者,在实际情况中建议还是使用 notifyAll() 方法,这样多个消费和生产者逻辑也能够保证(可以自己试一下);通过初始版本一步步地分析问题和解决问题,我们就差不多写出了我们经典生产者消费者的经典代码,但通常消费和生产的逻辑是写在各自的消费者和生产者代码里的,这里我为了方便阅读,把他们都抽离到了共享资源上,我们可以简单地再来回顾一下这个消费生产和等待通知的整个过程:
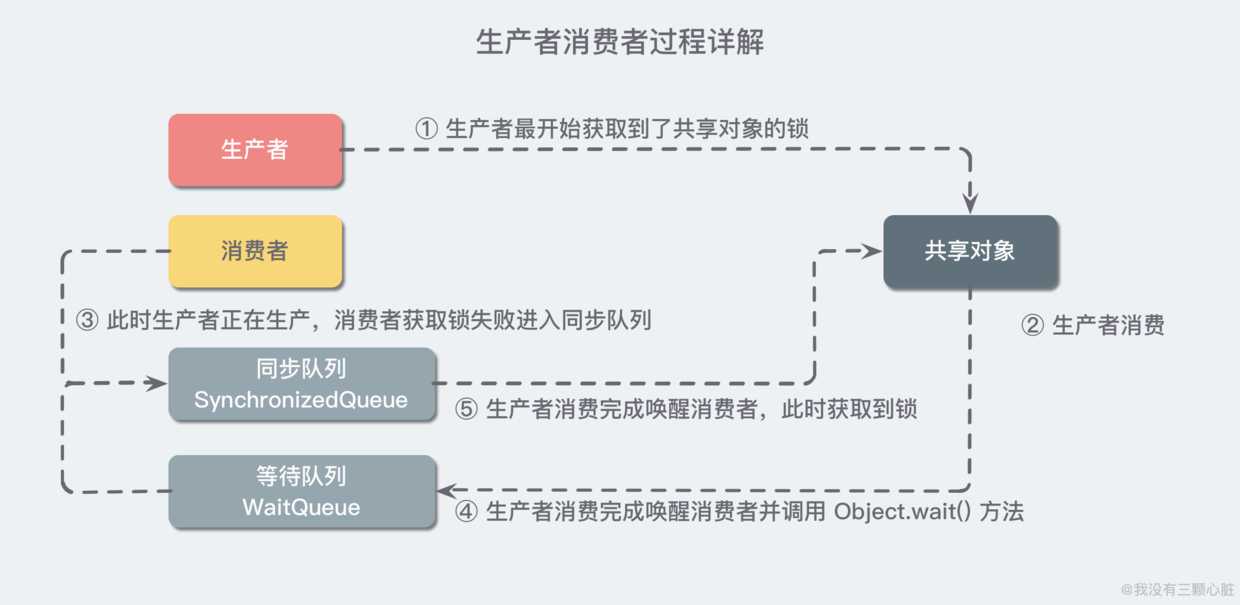
以上就是关于生产者生产一条数据,消费者消费一次的过程了,涉及的一些具体细节我们下面来说。
我们从上面的中看到了 wait() 和 notify() 方法,只能被同步监听锁对象来调用,否则就会报出 IllegalMonitorZStateException 的异常,那么现在问题来了,我们在上一篇提到的 Lock 机制根本就没有同步锁了,也就是没有自动获取锁和自动释放锁的概念,因为没有同步锁,也就意味着 Lock 机制不能调用 wait 和 notify 方法,我们怎么办呢?
好在 Java 5 中提供了 Lock 机制的同时也提供了用于 Lock 机制控制通信的 Condition 接口,如果大家理解了上面说到的 Object.wait() 和 Object.notify() 方法的话,那么就能很容易地理解 Condition 对象了。
它和 wait() 和 notify() 方法的作用是大致相同的,只不过后者是配合 synchronized 关键字使用的,而 Condition 是与重入锁相关联的。通过 Lock 接口(重入锁就实现了这一接口)的 newCondition() 方法可以生成一个与当前重入锁绑定的 Condition 实例。利用 Condition 对象,我们就可以让线程在合适的时间等待,或者在某一个特定的时刻得到通知,继续执行。
我们拿上面的生产者消费者来举例,修改成 Lock 和 Condition 代码如下:
public class ShareResource {
private String name;
private String gender;
// 新增加一个标志位,表示共享资源是否为空,默认为 true
private boolean isEmpty = true;
private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
/**
* 模拟生产者向共享资源对象中存储数据
*
* @param name
* @param gender
*/
public void push(String name, String gender) {
lock.lock();
try {
while (!isEmpty) {
// 当前共享资源不为空的时,则等待消费者来消费
condition.await();
}
// 开始生产
this.name = name;
Thread.sleep(10);
this.gender = gender;
// 生产结束
isEmpty = false;
// 生产结束唤醒消费者来消费
condition.signalAll();
} catch (Exception ignored) {
} finally {
lock.unlock();
}
}
/**
* 模拟消费者从共享资源中取出数据
*/
public void popup() {
lock.lock();
try {
while (isEmpty) {
// 为空则等着生产者进行生产
condition.await();
}
// 消费开始
Thread.sleep(10);
System.out.println(this.name + "-" + this.gender);
// 消费结束
isEmpty = true;
// 消费结束唤醒生产者去生产
condition.signalAll();
} catch (InterruptedException ignored) {
} finally {
lock.unlock();
}
}
}在 JDK 内部,重入锁和 Condition 对象被广泛地使用,以 ArrayBlockingQueue 为例,它的 put() 方法实现如下:
/** Main lock guarding all access */
final ReentrantLock lock;
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
// 构造函数,初始化锁以及对应的 Condition 对象
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
// 等待队列有足够的空间
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
items[putIndex] = x;
if (++putIndex == items.length)
putIndex = 0;
count++;
// 通知需要 take() 的线程,队列已有数据
notEmpty.signal();
}同理,对应的 take() 方法实现如下:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
// 如果队列为空,则消费者队列要等待一个非空的信号
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}以下内容摘录 or 改编自 《实战 Java 高并发程序设计》 3.1.3 节的内容
信号量为多线程协作提供了更为强大的控制方法。广义上说,信号量是对锁的扩展,无论是内部锁 synchronized 还是重入锁 ReentrantLock,一次都只允许一个线程访问一个资源,而信号量却可以指定多个线程,同时访问某一个资源。信号量主要提供了以下构造函数:
public Semaphore(int permits)
public Semaphore(int permits, boolean fair) // 第二个参数可以指定是否公平在构造信号量对象时,必须要指定信号量的准入数,即同时能申请多少个许可。当每个线程每次只申请一个许可时,这就相当于指定了同时有多少个线程可以访问某一个资源。信号量的主要逻辑如下:
public void acquire()
public void acquireUninterruptibly()
public boolean tryAcquire()
public boolean tryAcquire(long timeout, TimeUnit unit)
public void release()acquire() 方法尝试获得一个准入的许可。若无法获得,则线程会等待,直到有线程释放一个许可或者当前线程被中断。acquireUninterruptibly() 方法和 acquire() 方法类似,但是不响应中断。tryAcquire() 尝试获得一个许可,如果成功则返回 true,失败则返回 false,它不会进行等待,立即返回。release() 用于在线程访问资源结束后,释放一个许可,以使其他等待许可的线程可以进行资源访问。在 JDK 的官方 Javadoc 中,就有一个有关信号量使用的简单实例,有兴趣的读者可以自行去翻阅一下,这里给出一个更傻瓜化的例子:
public class SemapDemo implements Runnable {
final Semaphore semaphore = new Semaphore(5);
@Override
public void run() {
try {
semaphore.acquire();
// 模拟耗时操作
Thread.sleep(2000);
System.out.println(Thread.currentThread().getId() + ":done!");
semaphore.release();
} catch (InterruptedException ignore) {
}
}
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(20);
final SemapDemo demo = new SemapDemo();
for (int i = 0; i < 20; i++) {
executorService.submit(demo);
}
}
}执行程序,就会发现系统以 5 个线程为单位,依次输出带有线程 ID 的提示文本。
在实现上,Semaphore 借助了线程同步框架 AQS(AbstractQueuedSynchornizer),同样借助了 AQS 来实现的是 Java 中可重入锁的实现。AQS 的强大之处在于,你仅仅需要继承它,然后使用它提供的 api 就可以实现任意复杂的线程同步方案,AQS 为我们做了大部分的同步工作,所以这里不细说,之后再来详细探究一下...
如果一个线程 A 执行了 thread.join() 方法,其含义是:当前线程 A 等待 thread 线程终止之后才从 thread.join() 返回。线程 Thread 除了提供 join() 方法之外,还提供了 join(long millis) 和 join(long millis, int nanos) 两个具备超时特性的方法。这两个超时方法表示,如果线程 Thread 在给定的超时时间里没有终止,那么将会从该超时方法中返回。
在下面的代码中,我们创建了 10 个线程,编号 0 ~ 9,每个线程调用前一个线程的 join() 方法,也就是线程 0 结束了,线程 1 才能从 join() 方法中返回,而线程 0 需要等待 main 线程结束。
public class Join {
public static void main(String[] args) throws InterruptedException {
Thread previous = Thread.currentThread();
for (int i = 0; i < 10; i++) {
// 每个线程拥有前一个线程的引用,需要等待前一个线程终止,才能从等待中返回
Thread thread = new Thread(new Domino(previous), String.valueOf(i));
thread.start();
previous = thread;
}
TimeUnit.SECONDS.sleep(5);
System.out.println(Thread.currentThread().getName() + " terminate. ");
}
static class Domino implements Runnable {
private Thread thread;
public Domino(Thread thread) {
this.thread = thread;
}
@Override
public void run() {
try {
thread.join();
} catch (InterruptedException ignore) {
}
System.out.println(Thread.currentThread().getName() + " terminate. ");
}
}
}运行程序,可以看到下列输出:
main terminate.
0 terminate.
1 terminate.
2 terminate.
3 terminate.
4 terminate.
5 terminate.
6 terminate.
7 terminate.
8 terminate.
9 terminate. 说明每个线程终止的前提都是前驱线程的终止,每个线程等待前驱线程结束后,才从 join() 方法中返回,这里涉及了等待/ 通知机制,在 JDK 的源码中,我们可以看到 join() 的方法如下:
public final synchronized void join(long millis)
throws InterruptedException {
long base = System.currentTimeMillis();
long now = 0;
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (millis == 0) {
// 条件不满足则继续等待
while (isAlive()) {
wait(0);
}
// 条件符合则返回
} else {
while (isAlive()) {
long delay = millis - now;
if (delay <= 0) {
break;
}
wait(delay);
now = System.currentTimeMillis() - base;
}
}
}当线程终止时,会调用线程自身的 notifyAll() 方法,会通知所有等待在该线程对象上的线程。可以看到 join() 方法的逻辑结构跟我们上面写的生产者消费者类似,即加锁、循环和处理逻辑三个步骤。
我们先从一个有趣的例子入手:
private static boolean isOver = false;
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
while (!isOver) {
}
System.out.println("线程已感知到 isOver 置为 true,线程正常返回!");
});
thread.start();
Thread.sleep(500);
isOver = true;
System.out.println("isOver 已置为 true");
}我们开启了一个主线程和一个子线程,我们期望子线程能够感知到 isOver 变量的变化以结束掉死循环正常返回,但是运行程序却发现并不是像我们期望的那样发生,子线程一直处在了死循环的状态!
为什么会这样呢?
关于这一点,我们有几点需要说明,首先需要搞懂 Java 的内存模型:
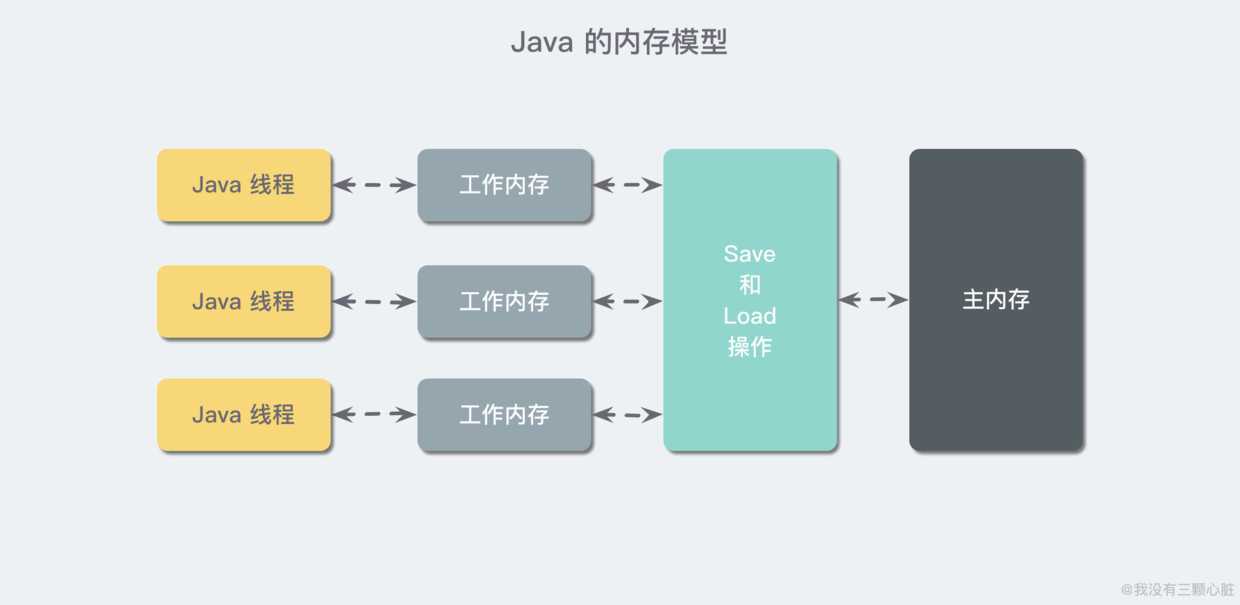
Java 虚拟机规范中试图定义一种 Java 内存模型(Java Memory Model, JMM)来屏蔽掉各层硬件和操作系统的内存访问差异,以实现让 Java 程序在各种平台下都能达到一致的内存访问效果。
Java 内存模型规定了所有的变量都存储在主内存(Main Memory)中。每条线程还有自己的工作内存(Working Memory),线程的工作内存中保存了被该线程使用到的变量的主内存副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在主内存中进行,而不能直接读写主内存中的变量。不同的线程之间也无法直接访问对方工作内存中的变量,线程间的变量值的传递均需要通过主内存来完成,线程、主内存、工作内存三者的关系如上图。
那么不同的线程之间是如何通信的呢?
在共享内存的并发模型里,线程之间共享程序的公共状态,线程之间通过写-读内存中的公共状态来隐式进行通信,典型的共享内存通信方式就是通过共享对象进行通信。
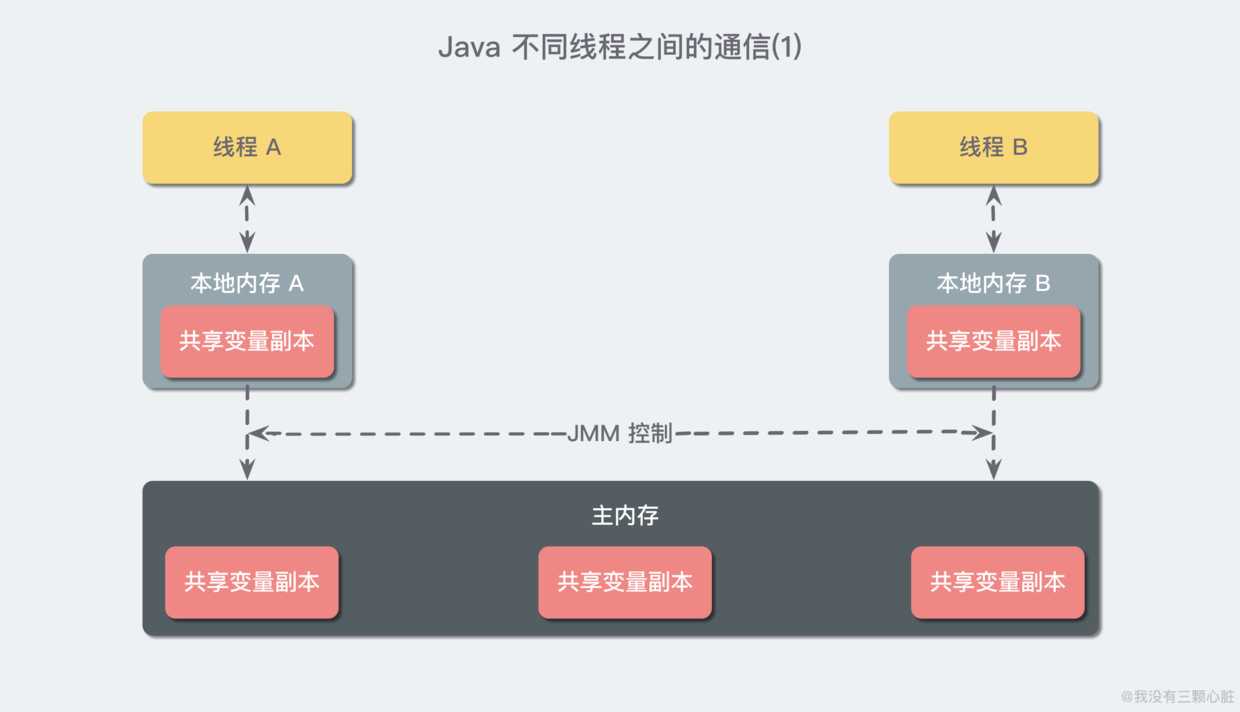
例如上图线程 A 与 线程 B 之间如果要通信的话,那么就必须经历下面两个步骤:
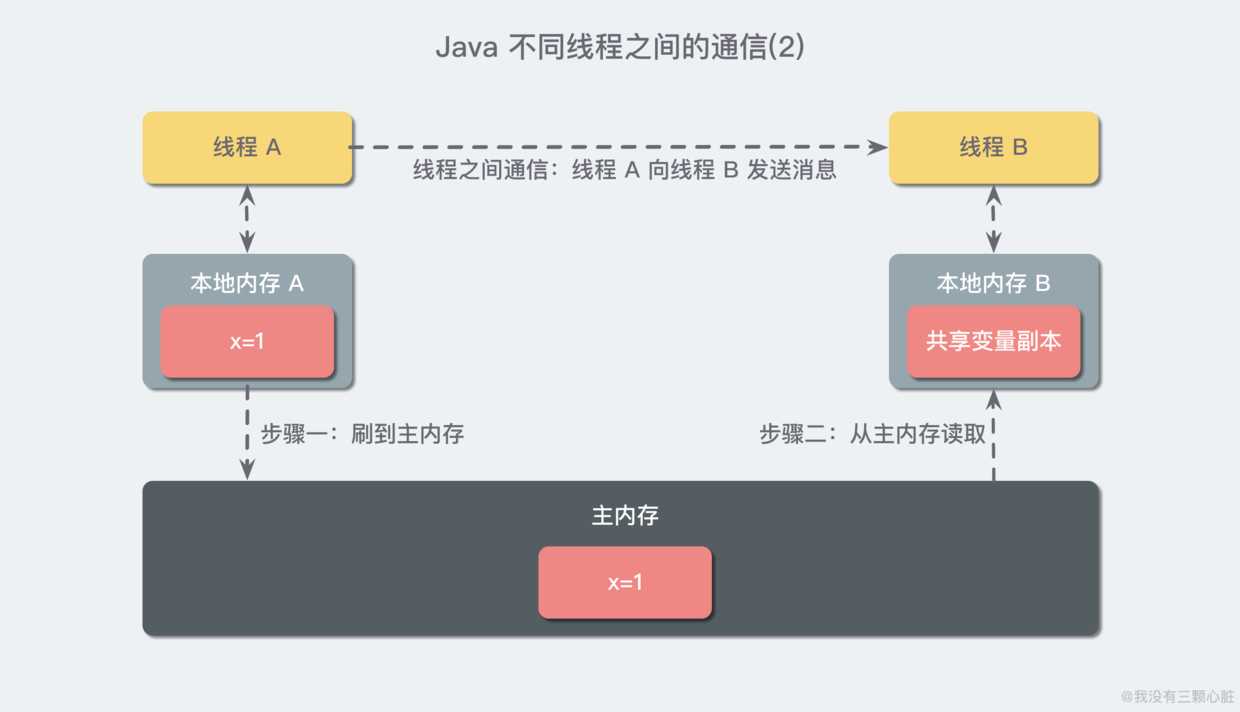
在消息传递的并发模型里,线程之间没有公共状态,线程之间必须通过明确的发送消息来显式进行通信,在 Java 中典型的消息传递方式就是 wait() 和 notify()。
说回刚才出现的问题,就很容易理解了:每个线程都有独占的内存区域,如操作栈、本地变量表等。线程本地保存了引用变量在堆内存中的副本,线程对变量的所有操作都在本地内存区域中进行,执行结束后再同步到堆内存中去。也就是说,我们在主线程中修改的 isOver 的值并没有被子线程读取到(没有被刷入主内存),也就造成了子线程对于 isOver 变量不可见。
解决方法也很简单,只需要在 isOver 变量前加入 volatile 关键字就可以了,这是因为加入了 volatile 修饰的变量允许直接与主内存交互,进行读写操作,保证可见性。
再从另一个有趣的例子中入手,这是在高并发场景下会存在的问题:
class LazyInitDemo {
private static TransationService service = null;
public static TransationService getTransationService(){
if (service == null) {
synchronized (this) {
if (service == null) {
service = new TransationService();
}
}
}
}
}这是一个典型的双重检查锁定思想,这段代码也是一个典型的双重检查锁定(Double-checked Locking)问题。在高并发的情况下,该对象引用在没有同步的情况下进行读写操作,导致用户可能会获取未构造完成的对象。
这是因为指令优化的结果。计算机不会根据代码顺序按部就班地执行相关指令,我们来举一个借书的例子:假如你要去还书并且想要借一个《高并发编程学习》系列丛书,而你的室友恰好也要还书,并且还想让你帮忙借一本《Java 从入门到放弃》。
这件事乍一看有两件事:你的事和你室友的事。先办完你的事,再开始处理你室友的事情是属于单线程的死板行为,此时你会潜意识地进行「优化」,例如你可以把你要还的书和你室友需要还的书一起还了,再一起把想要借的书借出来,这其实就相当于合并数据进行存取的操作过程了。
我们知道一条指令的执行是可以分成很多步骤的,简单地说,可以分为:
由于每一个步骤可能使用不同的硬件完成,因此,聪明的工程师就发明了流水线技术来执行指令,如下图所示:

可以看到,当第 2 条指令执行时,第 1 条执行其实并没有执行完,确切地说第一条指令还没有开始执行,只是刚刚完成了取值操作而已。这样的好处非常明显,假如这里每一个步骤都需要花费 1 毫秒,那么指令 2 等待指令 1 完全执行后再执行,则需要等待 5 毫秒,而使用流水线指令,指令 2 只需要等待 1 毫秒就可以执行了。如此大的性能提升,当然让人眼红。
回到最初的问题,我们分析一下:对于 Java 编译器来说,初始化 TransactionService 实例和将对象地址写到 service 字段并非原子操作,且这两个阶段的执行顺序是未定义的。加入某个线程执行 new TransactionService() 时,构造方法还未被调用,编译器仅仅为该对象分配了内存空间并设为默认值,此时若另一个线程调用 getTransactionService() 方法,由于 service != null,但是此时 service 对象还没有被赋予真正的有效值,从而无法取到正确的 service 单例对象。
对于此问题,一种较为简单的解决方案就是用 volatile 关键字修饰目标属性(适用于 JDK5 及以上版本),这样 service 就限制了编译器对它的相关读写操作,对它的读写操作进行指令重排,确定对象实例化之后才返回引用。
另外指令重排也有自己的规则,并非所有的指令都可以随意改变执行位置,下面列举一下基本的原则:
start() 方法先行发生于此线程的每个一个动作;interrupt() 方法的调用先行发生于被中断线程的代码检测到中断事件的发生;Thread.join() 方法结束、Thread.isAlive() 的返回值手段检测到线程已经终止执行;finalize() 方法的开始;volatile 解决的是多线程共享变量的可见性问题,类似于 synchronized,但不具备 synchronized 的互斥性。所以对 volatile 变量的操作并非都具有原子性,例如我们用下面的例子来说明:
public class VolatileNotAtomic {
private static volatile long count = 0L;
private static final int NUMBER = 10000;
public static void main(String[] args) {
Thread subtractThread = new SubstractThread();
subtractThread.start();
for (int i = 0; i < NUMBER; i++) {
count++;
}
// 等待减法线程结束
while (subtractThread.isAlive()) {
}
System.out.println("count 最后的值为: " + count);
}
private static class SubstractThread extends Thread {
@Override
public void run() {
for (int i = 0; i < NUMBER; i++) {
count--;
}
}
}
}多次执行后,发现结果基本都不为 0。只有在 count++ 和 count-- 两处都进行加锁时,才能正确的返回 0,了解 Java 的童鞋都应该知道这 count++ 和 count-- 都不是一个原子操作,这里就不作说明了。
在了解一点吧,注明的并发编程大师 Doug lea 在 JDK 7 的并发包里新增一个队列集合类 LinkedTransferQueue,它在使用 volatile 变量时,用一种追加字节的方式来优化对列出队和入队的性能,具体的可以看一下下列的链接,这里就不具体说明了。
Java 中任何一个对象都有一个唯一与之关联的锁,这样的锁作为该对象的一系列标志位存储在对象信息的头部。Java 对象头里的 Mark Word 里默认的存放的对象的 Hashcode/ 分代年龄和锁标记位。32 为JVM Mark Word 默认存储结构如下:

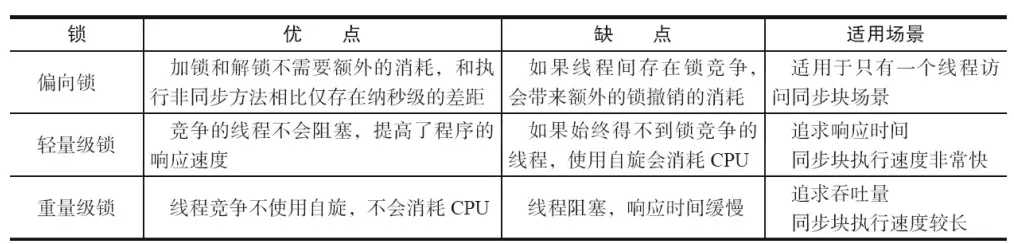
Java SE 1.6中,锁一共有 4 种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率。
HotSpot 的作者经过研究发现,大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。
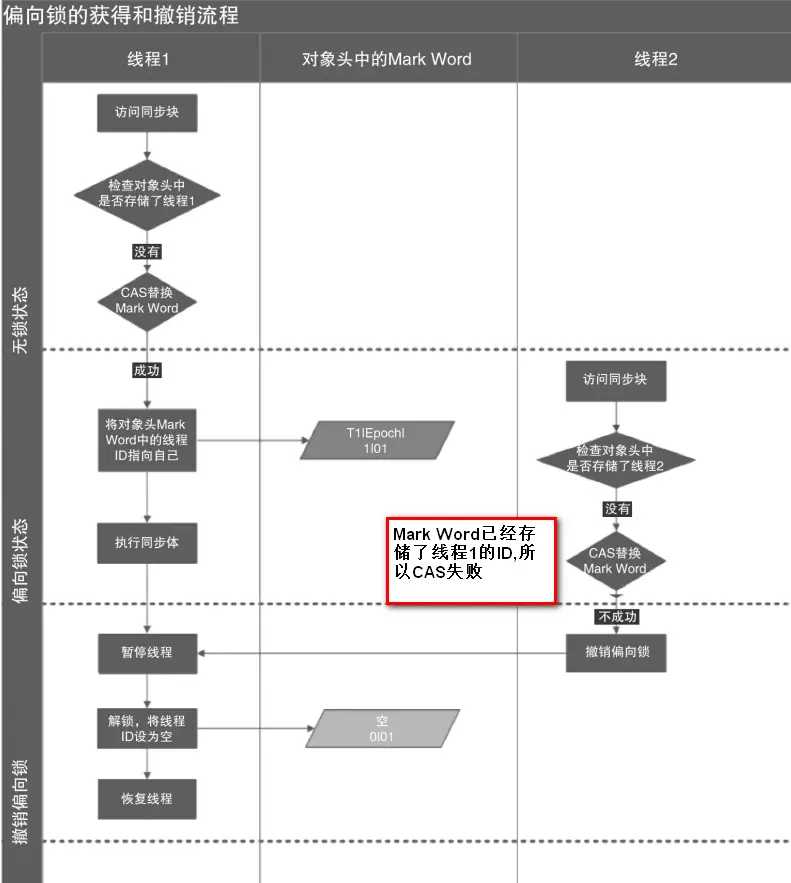
偏向锁的获取:当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程 ID,以后该线程在进入和退出同步块时不需要进行 CAS 操作来加锁和解锁,只需简单地测试一下对象头的 Mark Word 里是否存储着指向当前线程的偏向锁。如果测试成功,表示线程已经获得了锁。如果测试失败,则需要再测试一下 Mark Word 中偏向锁的标识是否设置成 1(表示当前是偏向锁),如果没有设置,则使用CAS竞争锁;如果设置了,则尝试使用CAS将对象头的偏向锁指向当前线程。
偏向锁的撤销:偏向锁使用了一种等到竞争出现才释放锁的机制,所以当其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁。
下图线程 1 展示了偏向锁获取的过程,线程 2 展示了偏向锁撤销的过程。
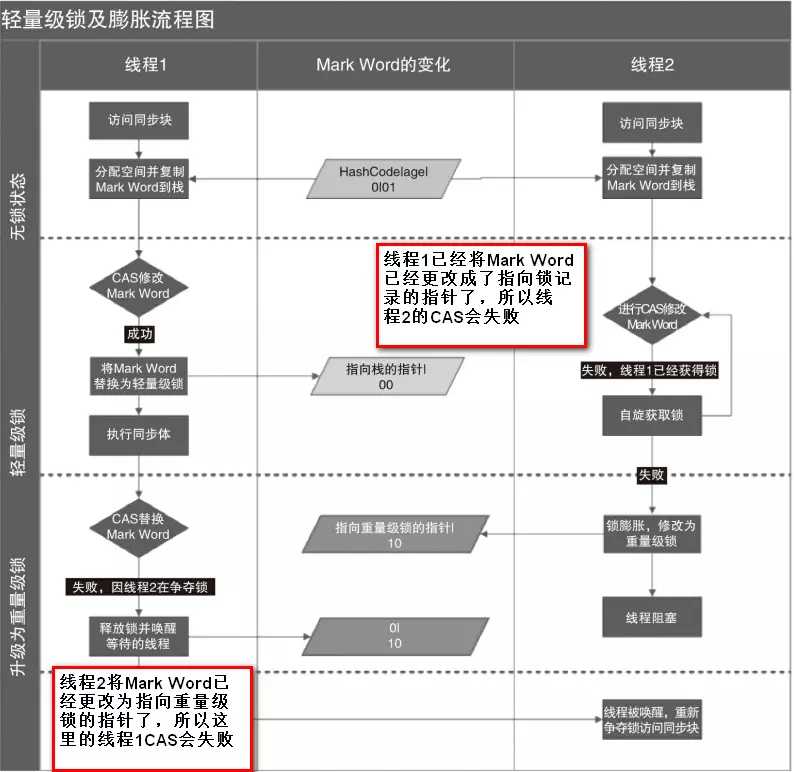
如果偏向锁失败,虚拟机并不会立即挂起线程。它还会使用一种称为轻量级锁的优化手段。
线程在执行同步块之前,JVM 会先在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的 Mark Word 复制到锁记录中,官方称为 Displaced Mark Word。然后线程尝试使用 CAS 将对象头中的 Mark Word 替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋(自己执行几个空循环再进行尝试)来获取锁。
轻量级解锁时,会使用原子的 CAS 操作将 Displaced Mark Word 替换回到对象头,如果成功,则表示没有竞争发生。如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。下图是两个线程同时争夺锁,导致锁膨胀的流程图。
下图就简单概括了一下几种锁的比较:
除了控制资源的访问外,我们还可以通过增加资源来保证所有对象的线程安全。比如,让 100 个人填写个人信息表,如果只有一支笔,那么大家就得挨个写,对于管理人员来说,必须保证大家不会去哄抢这仅存的一支笔,否则,谁也填不完。从另外一个角度出发,我们可以干脆就准备 100 支笔,那么所有人都可以各自为营,很快就能完成表格的填写工作。
如果说锁是使用第一种思路,那么 ThreadLocal 就是使用第二种思路了。
当使用 ThreadLocal 维护变量时,其为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立的改变自己的副本,而不会影响其他线程对应的副本。
ThreadLocal 内部实现机制:
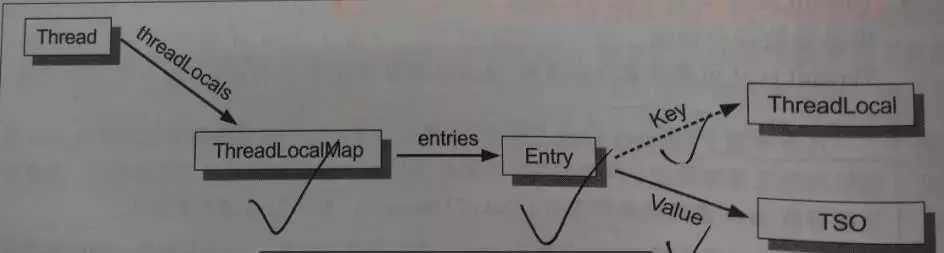
每个线程内部都会维护一个类似 HashMap 的对象,称为 ThreadLocalMap,里边会包含若干了 Entry(K-V 键值对),相应的线程被称为这些 Entry 的属主线程;
Entry 的 Key 是一个 ThreadLocal 实例,Value 是一个线程特有对象。Entry 的作用即是:为其属主线程建立起一个 ThreadLocal 实例与一个线程特有对象之间的对应关系;
Entry 对 Key 的引用是弱引用;Entry 对 Value 的引用是强引用。
为了让线程安全地共享某个变量,JDK 开出了 ThreadLocal 这副药方,但「是药三分毒」,ThreadLocal 也有一定的副作用。主要问题是「产生脏数据」和「内存泄漏」。这两个问题通常是在线程池中使用 ThreadLocal 引发的,因为线程池有 「线程复用」 和 「内存常驻」 两个特点。
线程复用会产生脏数据。由于线程池会重用 Thread 对象,那么与 Thread 绑定的类的静态属性 ThreadLocal 变量也会被重用。如果在实现的线程 run() 方法中不显式地 remove() 清理与线程相关的 ThreadLocal 信息,那么倘若下一个线程不调用 set() 设置初始值,就可能 get() 到重用的线程信息,包括 ThreadLocal 所关联的线程对象的 value 值。
为了方便理解,用一段简要代码来模拟,如下所示:
public class DirtyDataInThreadLocal {
public static ThreadLocal<String> threadLocal = new ThreadLocal<>();
public static void main(String[] args) {
// 使用固定大小为 1 的线程池,说明上一个的线程属性会被下一个线程属性复用
ExecutorService pool = Executors.newFixedThreadPool(1);
for (int i = 0; i < 2; i++) {
Mythread mythread = new Mythread();
pool.execute(mythread);
}
}
private static class Mythread extends Thread {
private static boolean flag = true;
@Override
public void run() {
if (flag) {
// 第 1 个线程 set 后,并没有进行 remove
// 而第二个线程由于某种原因没有进行 set 操作
threadLocal.set(this.getName() + ", session info.");
flag = false;
}
System.out.println(this.getName() + " 线程是 " + threadLocal.get());
}
}
}执行结果:
Thread-0 线程是 Thread-0, session info.
Thread-1 线程是 Thread-0, session info.在源码注释中提示使用 static 关键字来修饰 ThreadLocal。在此场景下,寄希望于 ThreadLocal 对象失去引用后,触发弱引用机制来回收 Entry 的 Value 就变得不现实了。在上面的例子中,如果不进行 remove() 操作,那么这个线程执行完成后,通过 ThreadLocal 对象持有的 String 对象是不会被释放的。
以上两个问题的解决办法很简单,就是在每次使用完 ThreadLocal 时,必须要及时调用 remove() 方法清理。
按照惯例黏一个尾巴:
欢迎转载,转载请注明出处!
独立域名博客:wmyskxz.com
简书 ID:@我没有三颗心脏
github:wmyskxz
欢迎关注公众微信号:wmyskxz
分享自己的学习 & 学习资料 & 生活
想要交流的朋友也可以加 qq 群:3382693
标签:虚拟 return pup osc 默认 对象 oda 开启 session
原文地址:https://www.cnblogs.com/wmyskxz/p/11944318.html