标签:iter 长度 搜索 监控 download vim led 显示 重复
文件内容: cat ,more,less
文件截取:head,tail
按列抽取:cut
排序和统计:sort,wc
-----------------------------------------------------
cat [OPTION]... [FILE]... //用于查看字符文件
-E:显示行结束符$
-n:对显示出的每一行进行编号
-A:显示所有控制符
-b:非空行编号
-s:压缩连续的空行成一行
------------------------------------------------------
分页查看
more:分页查看文件
more [OPTIONS...] FILE...
-d: 显示翻页及退出提示
less:一页一页地查看文件或STDIN输出
查看时有用的命令包括:
/文本 搜索 文本
n/N 跳到下一个 或 上一个匹配
less 命令是man命令使用的分页器
less
空格键 滚动一页
回车键 滚动一行
[pagedown]: 向下翻动一页
[pageup]: 向上翻动一页
还可以在冒号后面直接输入 /要搜索的关键字 进行 高亮显示,可以 用 n 向前查找或者 N 向后查找。
------------------------------------------------------------------------
head 查看文件的前几行
head failename 默认显示文件的前十行 head -n11 passwd ==head -11 passwd //指定了查看文件的前几行
tail 查看文件的后几行
tail failename 默认显示文件的后十行 tail -n11 passwd == tail -11 passwd //指定了查看文件的后几行
tail -f catalina.out 追踪文件新增加的内容,常用于日志监控
---------------------------------------------------------------------------------------------
cut 按列抽取文本
cut [OPTION]... [FILE]...
-d DELIMITER: 指明分隔符,默认tab
-f FILEDS:
#: 第#个字段
#,#[,#]:离散的多个字段,例如1,3,6
#-#:连续的多个字段, 例如1-6
混合使用:1-3,7
-c 按字符切割
实例:
cut -d: -f1,3 /etc/passwd //以:作为分隔符,取第1,3列
cat /etc/passwd | cut -d: -f1,3 显示结果是这种 root:0ifconfig ens33 |head -2|tail -1| tr -s " "|cut -d" " -f1-3
ifconfig ens33 |head -2|tail -1| tr -s " "|cut -d" " -f1,2,3
cut -c34-36 // 截取第34到36个字符
------------------------------------------------------------------------------------------------------
wc 统计数据
计数单词总数、行总数、字节总数和字符总数
wc story.txt
39 237 1901 story.txt
行数 字数 字节数
常用选项
--------------------------------------------------------------------------------------------------------------------
tr
tr ‘ ‘ + //把‘ ‘替换成+
tr -s ‘ ‘ //压缩空格
tr -d ‘0-9‘ //删除字符
tr -dc ‘[0-9\n]‘ //除此之外的其他字符删除
tr -s " " % 压缩并替换
-----------------------------------------------------------------------
文本排序sort 根据列来排序( 一个字符,一个字符比较)
常用选项
echo {1..10}|tr ‘ ‘ ‘\n‘|sort -rn //把 一行数字 转成一列数字,然后按照数字排序
----------------------------------------------------------------------------------------------
uniq
uniq命令:从输入中删除前后相接的重复的行
uniq [OPTION]... [FILE]...
常和sort 命令一起配合使用:
sort userlist.txt | uniq -c
--------------------------------------------------------------------------------
grep 过滤行
grep [OPTIONS] PATTERN [FILE...]
nmap -v -sP 172.16.128.0/24 |grep -B1 up //匹配含有up行的 前一行
|grep -e root -e bin 多个条件 或者包含 //包含root或者包含 bin
ls |grep -v [abc] //文件名中不包含a b c 三个字母的文件名
cat /etc/centos-release |grep -o "\<[0-9]\+\>"|head -1 //匹配 单个的数字
[root@centos7 ~]#grep -E "^([^:]+):.*\<\1$" /etc/passwd 分组 //扩展的正则表达式
---------------------------------------------------------------------------------------------
正则表达式
字符匹配:
匹配次数:用在要指定次数的字符后面,用于指定前面的字符要出现的次数
位置锚定:定位出现的位置
分组:\(\) 将一个或多个字符捆绑在一起,当作一个整体处理,如:\(root\)\+
或者:\|
示例:a\|b a或b C\|cat C或cat \(C\|c\)at Cat或cat
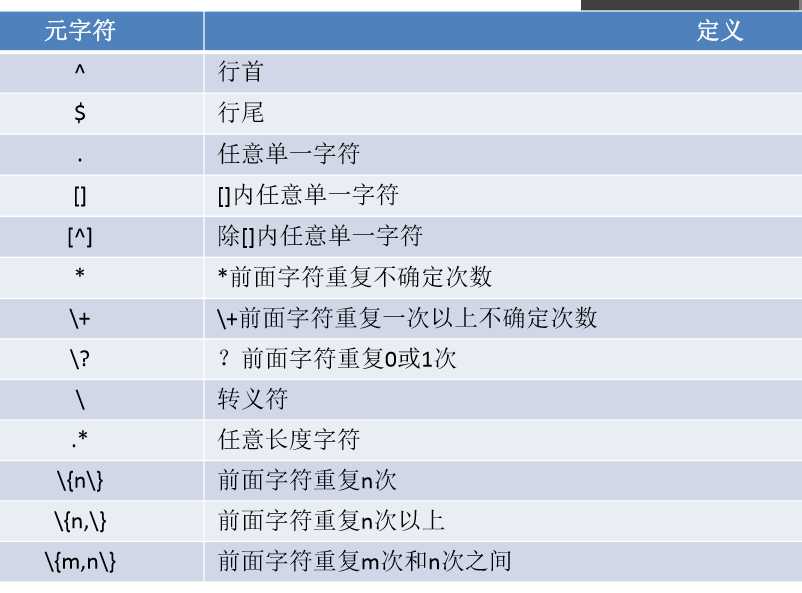
扩展正则表达式
egrep = grep -E
和基本正则表达式的区别就是,有一些地方不用加斜线(\),
基本正则表达式需要用到斜线的地方: \( \) \< \> \{\} \+ \?
扩展的正则表达式 : \< \>
ifconfig |grep -oE "(2[0-4][0-9]|25[0-5]|1[0-9][0-9]|[1-9]?[0-9])(\.(2[0-4][0-9]|25[0-5]|1[0-9][0-9]|[1-9]?[0-9])){3}" //扩展正则表达式匹配ip
ifconfig |grep -Po "((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)" //perl正则表达式匹配ip
vim %s#^\(/download.*\)/media/\(.*\)\..*$#\1/mp3/\2.mp3 // vim 搜索替代 分组
标签:iter 长度 搜索 监控 download vim led 显示 重复
原文地址:https://www.cnblogs.com/hxfcodelife/p/11951610.html