标签:最大 代码 思路分析 void data 第一个 循环 删除 遇到
本文将阐述堆和堆排序的基本原理,通过本文将了解到以下内容:
1.堆的简介
堆是计算机科学中的一种特别的树状数据结构。
若是满足以下特性,即可称为堆:给定堆中任意节点P和C,若P是C的母节点,那么P的值会小于等于C的值。若母节点的值恒小于等于子节点的值,此堆称为最小堆;反之称为最大堆。
堆始于J. W. J. Williams在1964年发表的堆排序,当时他提出了二叉堆树作为此算法的数据结构,堆在戴克斯特拉算法和带优先级队列中亦为重要的关键。
数据结构中的堆区别于内存分配的堆,我们说的用于排序的堆是一种表示元素集合的结构,堆是一种二叉树。
堆有两个决定性特性:元素顺序和树的形状

堆这种二叉树最多在两层具有叶子结点,并且最底层的叶子结点靠左分布,该树种不存在空闲位置,也就是堆是个完全二叉树。上述的两种性质可以保证快捷找到最值,并且在插入和删除新元素时可以实现重新组织再次满足堆的性质。
2.堆的数组表示
堆中没有空闲位置并且数组是连续的,但是数组的下标是从0开始,为了统一,我们统一从1开始,也就是root结点的数组index=1,那么可以通过数组的index可以通过父结点找到左右子结点,也可以通过子结点找到父结点。数组的元素遍历就是堆的层次遍历的结果,因此数组存储的堆具备以下性质:
//数组下标范围 i<=n && i>=1 //根结点下标为1 root_index = 1 //层次遍历第i个结点的值等于数组第i个元素 value(i) = array[i] //堆中第i个元素的左孩子下标i*2 left_child_index(i) = i*2 //堆中第i个元素的右孩子下标i*2+1 right_child_index(i) = i*2+1 //堆中第i个元素的父结点下标i/2 parent(i) = i/2
堆和数组的对应关系如图:

3.堆的调整函数
堆调整的过程非常像数学归纳法的递推过程,看一下就知道。
敲黑板!以下两个函数对于掌握堆非常重要。
以小根堆为例,之前a[1...n-1]满足堆的特性,在数组a[n]插入新元素之后,就产生了两种情况:
A. 如果a[n]大于父结点那么a[1...n]仍然满足堆的特性,不需要调整;
B. 如果a[n]比它的父结点要小无法保证堆的特性,就需要进行调整;
循环过程:自底向上的调整过程就是新加入元素不断向上比较置换的过程,直到新结点的值大于其父结点,或者新结点成为根结点为止。
停止条件:siftup是一个不断向上循环比较置换的过程,理解循环的关键是循环停止的条件,从伪码中可以清晰地看到,siftup的伪码:
//siftup运行的前置条件 heap(1,n-1) == True void siftup(n) i = n loop: // 循环停止条件一 // 已经是根结点 if i == 1: break; p = i/2 // 循环停止条件二 // 调整结点大于等于在此位置的父结点 if a[p] <= a[i] break; swap(a[p],a[i]) // 继续向上循环 i = p
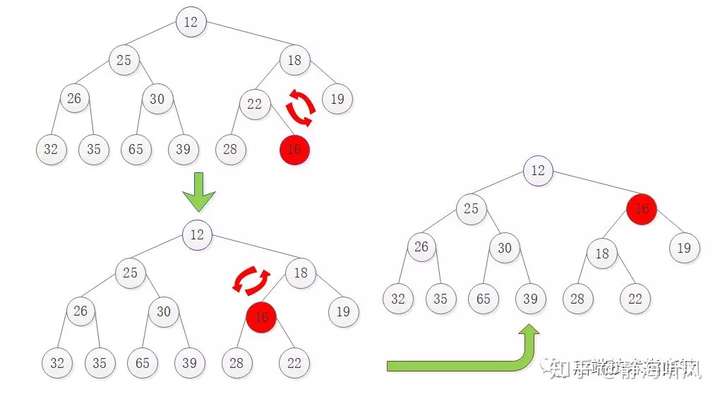
siftup调整过程演示
在尾部插入元素16的调整过程如图:
以小根堆为例,之前a[1...n]满足堆的特性,在数组a[1]更新元素之后,就产生了两种情况:
A. 如果a[1]小于等于子结点仍然满足堆的特性,不需要调整;
B. 如果a[1]大于子结点无法保证堆的特性,就需要进行调整;
循环过程:自顶向下的调整过程就是新加入元素不断向下比较置换的过程,直到新结点的值小于等于其子结点,或者新结点成为叶结点为止。
停止条件:siftdn是一个不断向下循环比较置换的过程,理解循环的关键是循环停止的条件,从伪码中可以清晰地看到siftdn的伪码:
heap(2,n) == True void siftdn(n) i = 1 loop: // 获取理论上的左孩子下标 c = 2*i // 如果左孩子下标已经越界 // 说明当前已经是叶子结点 if c > n: break; //如果存在右孩子 // 则获取左右孩子中更小的一个 // 和父结点比较 if c+1 <= n: if a[c] > a[c+1] c++ // 父结点小于等于左右孩子结点则停止 if a[i] <= a[c] break; // 父结点比左右孩子结点大 // 则与其中较小的孩子结点交换 // 也就是让原来的孩子结点成为父结点 swap(a[i],a[c]) // 继续向下循环 i = c
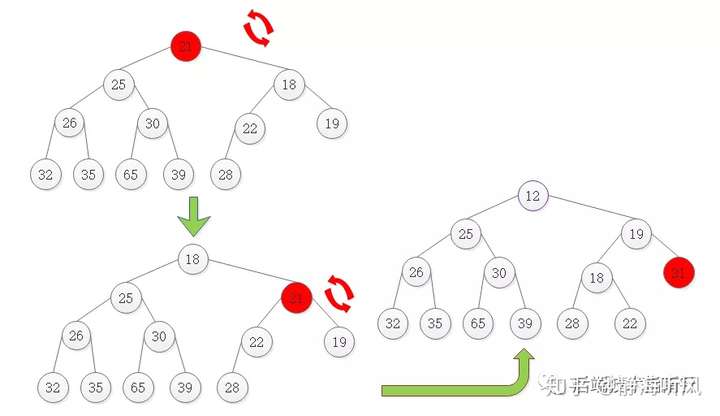
siftdn调整过程演示
在头部元素更新为21的调整过程如图:
4.堆排序
堆排序的场景:
假如有200w数据,要找最大的前10个数,那么就需要先建立大小为10个元素的小顶堆,然后再逐渐把其他所有元素依次渗透进来比较或入堆淘汰老数据或跳过,直至所有数据渗透完成,最后小根堆的10个元素就是最大的10个数了。
最大TopN使用小根堆的原因:选择最大的TopN个数据使用小根堆,因为堆顶就是最小的数据,每次进来的新数据只需要和堆顶比较即可,如果小于堆顶则跳过,如果大于堆顶则替换掉堆顶进行siftdn调整,来找到新进元素的正确位置,以及产生新的堆顶。
建堆过程:可以自顶向下自底向上均可,以下采用自底向上思路分析。可以将数组的叶子节点,是单个结点满足二叉堆的定义,于是从底层叶子结点的父结点从左到右,逐个向上构建二叉堆,直到第一个节点时整个数组就是一个二叉堆,这个过程是siftup和siftdn的混合,宏观上来看是自底向上,微观上每个父结点是自顶向下。
渗透排序过程:完成堆化之后,开处理N之后的元素,从N+1~200w,遇到比当前堆顶大的则与堆顶元素交换,进入堆触发siftdn调整,直至生产新的小根堆。
实例代码(验证AC):
题目:leetCode 第215题 数组中的第K个最大元素,这道题可以用堆排序来完成,建立小根堆取堆顶元素即可。
//leetcode 215th the Kth Num //Source Code:C++ class Solution { public: //调整以当前节点为根的子树为小顶堆 int heapadjust(vector<int> &nums,int curindex,int len){ int curvalue = nums[curindex]; int child = curindex*2+1; while(child<len){ //左右孩子中较小的那个 if(child+1<len && nums[child] > nums[child+1]){ child++; } //当前父节点比左右孩子其中一个大 if(curvalue > nums[child]){ nums[curindex]=nums[child]; curindex = child; child = curindex*2+1; }else{ break; } } nums[curindex]=curvalue; return 0; } int findKthLargest(vector<int>& nums, int k) { //边界条件 if(nums.size()<k) return -1; //建立元素只有K个的小顶堆 //截取数组的前k个元素 vector<int> subnums(nums.begin(),nums.begin()+k); int len = nums.size(); int sublen = subnums.size(); //将数组的前k个元素建立小顶堆 for(int i=sublen/2-1;i>=0;i--){ heapadjust(subnums,i,sublen); } //建立好小顶堆之后 开始逐渐吸收剩余的数组元素 //动态与堆顶元素比较 替换 for(int j=k;j<len;j++){ if(nums[j]<=subnums[0]) continue; subnums[0] = nums[j]; heapadjust(subnums,0,sublen); } return subnums[0]; } };
5.总结
网上有很多堆排序过程的图解,本文因此并没有过多重复这个过程,从实践来看,重点是初始化堆和调整堆两个过程,然而这两个过程都离不开siftup和siftdn两个函数,因此掌握这两个函数,基本上就掌握了堆。
由于堆是二叉树,因此在实际使用中需要结合树的遍历和循环来实现堆调整。掌握堆调整过程和二叉树遍历过程,拿下堆,指日可待。
6.参考资料
标签:最大 代码 思路分析 void data 第一个 循环 删除 遇到
原文地址:https://www.cnblogs.com/backnullptr/p/11956120.html