标签:基本实现 text 哪些 结果 cloud 导入 jieba分词 bs4 style


import requests from bs4 import BeautifulSoup #导入requests库 从bs4库中调用BeautifulSoup
#爬取爱奇艺电影频道目标的HTML页面 def getHTMLText(url): try: #用requests抓取网页信息,请求超时时间为60秒 r = requests.get(url,timeout=60) #如果状态码不是200,则引发异常 r.raise_for_status() #配置编码 r.encoding = r.apparent_encoding return r.text except: return "爬取失败" #获取电影名称 def getMovie(ulist,html): soup = BeautifulSoup(html,"html.parser") #用find_all方法从HTML页面中所有的p标签,从中获取到电影的名称 for p in soup.find_all("p","site-piclist_info_title"): ulist.append(p.a.string) return ulist #获取电影评分 def getPage1(ulist,html): soup = BeautifulSoup(html,"html.parser") #用find_all方法从HTML页面中所有的div标签,从中获取到电影的评分 for div in soup.find_all("div","site-title_score"): ulist.append(div.span.strong.string) return ulist def getPage2(ulist,html): soup = BeautifulSoup(html,"html.parser") u = [] for div in soup.find_all("div","site-title_score"): ulist.append(list(div.span)) return ulist #打印电影信息函数 def printUnivList(ulist1,ulist2,ulist3,num): print("{:^50}".format("电影名称及评分")) for i in range(num): print("{:^45}\t\t{}{}".format(ulist1[i],ulist2[i],ulist3[i])) #填入要请求的服务器地址URL Url = "https://www.iqiyi.com/dianying_new/i_list_paihangbang.html" #创建一个数组m用来存放爬取到的电影名称 m = [] #创建2个数组分别存储电影评分的个位部分的数值以及小数点后的数值 p1 = [] p2 = [] #创建一个数组P3将p1和p2的数据进行合并处理 p3 = [] #获取到HTML页面信息 html = getHTMLText(Url) #获取到电影名称 getMovie(m,html) #获取到电影评分 getPage1(p1,html) getPage2(p2,html) #将p1和p2的信息合并存储到p3 for i in range(len(p2)): p3.append(p2[i][1]) #打印所有爬取到的电影信息 printUnivList(m,p1,p3,len(m))
运行结果:
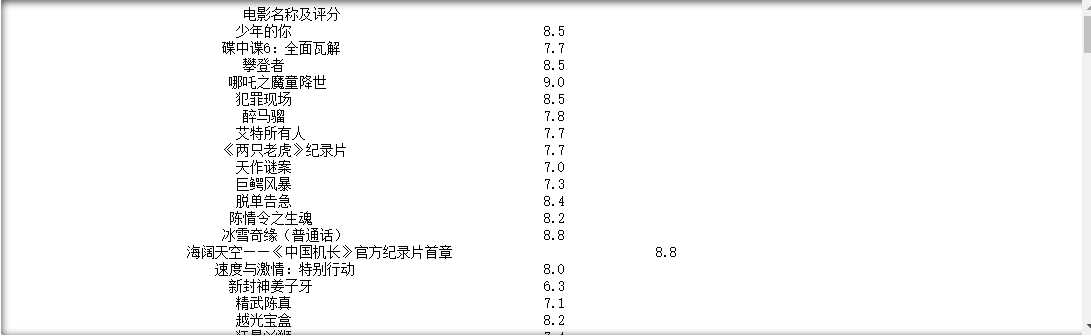
#爬取爱奇艺电影频道目标的HTML页面 def getHTMLText(url): try: #用requests抓取网页信息,请求超时时间为60秒 r = requests.get(url,timeout=60) #如果状态码不是200,则引发异常 r.raise_for_status() #配置编码 r.encoding = r.apparent_encoding return r.text except: return "爬取失败"
#获取电影名称 def getMovie(ulist,html): soup = BeautifulSoup(html,"html.parser") #用find_all方法从HTML页面中所有的p标签,从中获取到电影的名称 for p in soup.find_all("p","site-piclist_info_title"): ulist.append(p.a.string) return ulist #获取电影评分 def getPage1(ulist,html): soup = BeautifulSoup(html,"html.parser") #用find_all方法从HTML页面中所有的div标签,从中获取到电影的评分 for div in soup.find_all("div","site-title_score"): ulist.append(div.span.strong.string) return ulist def getPage2(ulist,html): soup = BeautifulSoup(html,"html.parser") u = [] for div in soup.find_all("div","site-title_score"): ulist.append(list(div.span)) return ulist #打印电影信息函数 def printUnivList(ulist1,ulist2,ulist3,num): print("{:^50}".format("电影名称及评分")) for i in range(num): print("{:^45}\t\t{}{}".format(ulist1[i],ulist2[i],ulist3[i])) #填入要请求的服务器地址URL Url = "https://www.iqiyi.com/dianying_new/i_list_paihangbang.html" #创建一个数组m用来存放爬取到的电影名称 m = [] #创建2个数组分别存储电影评分的个位部分的数值以及小数点后的数值 p1 = [] p2 = [] #创建一个数组P3将p1和p2的数据进行合并处理 p3 = [] #获取到HTML页面信息 html = getHTMLText(Url) #获取到电影名称 getMovie(m,html) #获取到电影评分 getPage1(p1,html) getPage2(p2,html) #将p1和p2的信息合并存储到p3 for i in range(len(p2)): p3.append(p2[i][1]) #打印所有爬取到的电影信息 printUnivList(m,p1,p3,len(m))
#encoding=utf-8 from wordcloud import WordCloud import matplotlib.pyplot as plt import jieba file_object = open(r‘C:\Users\lenovo\Desktop\琐屑\a‘) #不要把open放在try中,以防止打开失败,那么就不用关闭了 try: file_context = file_object.read() #file_context是一个string,读取完后,就失去了对test.txt的文件引用 finally: file_object.close() #print(file_context) seg_list = jieba.cut_for_search(file_context)# 搜索引擎模式 #print(list(seg_list)) #print(" ".join(seg_list)) # 设置词云 wc = WordCloud( # 设置背景颜色 background_color="black", # 设置最大显示的词云数 max_words=2000, # 这种字体都在电脑字体中,一般路径 font_path=‘C:\Windows\Fonts\simfang.ttf‘, height=1200, width=1600, # 设置字体最大值 max_font_size=100, # 设置有多少种随机生成状态,即有多少种配色方案 random_state=30, ) myword = wc.generate(" ".join(seg_list)) # 生成词云 # 展示词云图 plt.imshow(myword) plt.axis("off") plt.show() wc.to_file(‘C://Users//123//Desktop//p.png‘) # 把词云保存下
结果图:
标签:基本实现 text 哪些 结果 cloud 导入 jieba分词 bs4 style
原文地址:https://www.cnblogs.com/BoYCB/p/11962015.html