标签:四种 image 常用方法 mamicode 概率分布 等价 等于 包括 方法
文本自然语言处理的一个最最最基本的一个问题:如何用数学符号或公式表示一段文本?如何计算一段文本在某种语言下出现的概率?
语言模型(用概率论的专业术语表示):为长度为m的字符串确定其概率分布P(w1,w2,...wm),其中w1到wm依次表示文本中的各个词语。概率值计算公式如下,
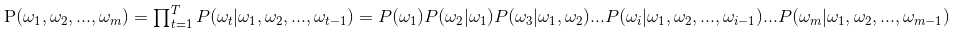
但是有个问题发现没有?加入一个文本超级长,会怎么样?从第三项开始计算难度就会很大。此时,有人提出了n元模型(n-gram model)。那么n元模型是什么呢?它就是在估算条件概率时,忽略距离大于等于n的上文词的影响。则此时
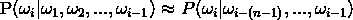
首先,把一段文字抽象成数学表示,用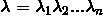 表示输入的句子,n为句子长度,
表示输入的句子,n为句子长度,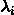 表示字。
表示字。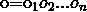 表示输出的标签(例如:"我/B爱/M你/E"最理想的标签输出:BME)。其中,o表示的就是B、M、E、S这四种标记,λ为诸如“我”“爱”“你”“中”“国”等句子的每个字,包括标点等非中文字符。
表示输出的标签(例如:"我/B爱/M你/E"最理想的标签输出:BME)。其中,o表示的就是B、M、E、S这四种标记,λ为诸如“我”“爱”“你”“中”“国”等句子的每个字,包括标点等非中文字符。
当n=0时,即观测独立性假设,就是0阶隐马尔可夫,每个词都是独立的,例如:我爱你->我/B爱/M你/E,此时,标签/M仅和爱有关系
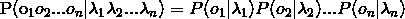
当n=1时,即齐次马尔可夫假设,就是1阶隐马尔可夫,每个词都仅与前一个词有关系,
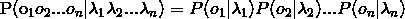
那么从上面的公式我们可以看到,我们渴望得到的解是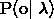 ,这是不是很熟悉了?条件概率,通过贝叶斯公式即可求解,
,这是不是很熟悉了?条件概率,通过贝叶斯公式即可求解,
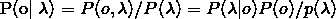
此处有一问题,我没明白,可能是太菜了,如果有会的,希望各位在评论区给指点一下,万分感谢!!!问题是:λ是给定的输入,因此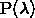 计算为常数,可以忽略,因此最大化
计算为常数,可以忽略,因此最大化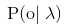 等价于最大化
等价于最大化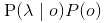 。我对这个为常熟可忽略不明白。
。我对这个为常熟可忽略不明白。
好,假如我明白了,那么,求可以先求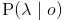 ,按照齐次隐马尔可夫假设,则
,按照齐次隐马尔可夫假设,则
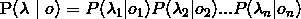
再求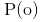
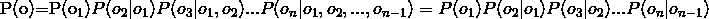
那么就可求了,即
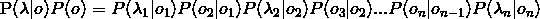
其中,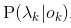 叫发射概率,
叫发射概率,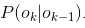 叫转移概率。通过设置转移概率为0(
叫转移概率。通过设置转移概率为0(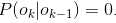 )
)
,可排除类似BBB、EM等不合理的组合。
注:在隐马尔可夫中求解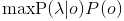 的常用方法是Veterbi算法,可参考博客 : https://blog.csdn.net/sailist/article/details/83064985
的常用方法是Veterbi算法,可参考博客 : https://blog.csdn.net/sailist/article/details/83064985
学过运筹学的同学更好理解一些
标签:四种 image 常用方法 mamicode 概率分布 等价 等于 包括 方法
原文地址:https://www.cnblogs.com/JadenFK3326/p/11964892.html