标签:字符编码 oschina 情况 元素 统一 拆分 梦想 rar 字符替换
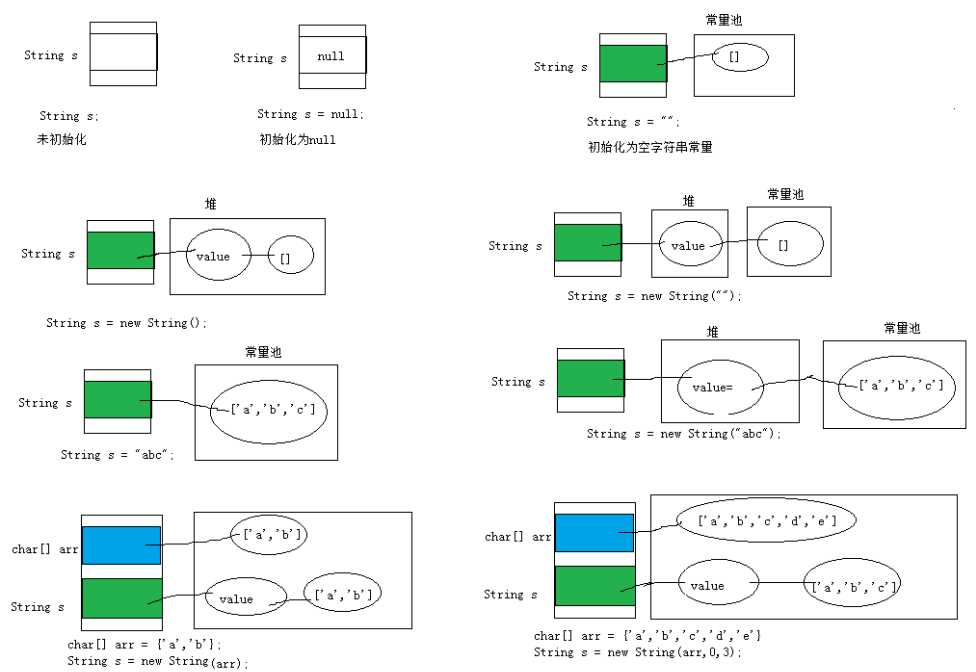
1、字符串String类型本身是final声明的,意味着我们不能继承String。
2、字符串的对象也是不可变对象,意味着一旦进行修改,就会产生新对象
我们修改了字符串后,如果想要获得新的内容,必须重新接受。
3、String对象内部是用字符数组进行保存的
JDK1.9之前有一个char[] value数组,JDK1.9之后byte[]数组
4、String类中这个char[] values数组也是final修饰的,意味着这个数组不可变,然后它是private修饰,外部不能直接操作它,String类型提供的所有的方法都是用新对象来表示修
改后内容的,所以保证了String对象的不可变。
5、就因为字符串对象设计为不可变,那么所以字符串有常量池来保存很多常量对象,可以共享
如果涉及到大量的字符串修改操作,建议使用StringBuffer或StringBuilder
1、字面常量值
String str = "hello";
2、使用构造器
String(String original): 初始化一个新创建的 String 对象,使其表示一个与参数相同的字符序列;换句话说,新创建的字符串是该参数字符串的副本。
public String(char[] value) :通过当前参数中的字符数组来构造新的String。
public String(char[] value,int offset, int count) :通过字符数组的一部分来构造新的String。
public String(byte[] bytes) :通过使用平台的默认字符集解码当前参数中的字节数组来构造新的String。
public String(byte[] bytes,String charsetName) :通过使用指定的字符集解码当前参数中的字节数组来构造新的String。
3、静态方法
static String copyValueOf(char[] data, int offset, int count):返回指定数组中表示该字符序列的 String
static String valueOf(char[] data) : 返回指定数组中表示该字符序列的 String
static String valueOf(char[] data, int offset, int count) : 返回指定数组中表示该字符序列的 String
static String valueOf(xx value):xx支持各种数据类型,返回各种数据类型的value参数的字符串表示形式。
4、xx.toString()
StringBuffer s = new StringBuffer(xx);
String str = s.toString(); :返回字符串对象
5、和字符串的拼接+
任意数据类型与"字符串"进行拼接,结果都是字符串
String str = "hello"; //1个
String str = new String("atguigu"); //2个
String s1 = "hello";//1个
String s2 = "world";//1个
String s3 = s1 + s2 + "java"; //"java"1个,s1 + s2拼接结果1个,最后结果1个
1、+
(1)常量+常量:结果是常量池
(3)拼接后调用intern方法:结果在常量池
2、concat:拼接的结果都是新的字符串,哪怕是两个常量对象拼接,都在堆中
String s1 = "hello";
String s2 = "world";
String s3 = s1 + "world"; //s3字符串内容也是helloworld,s1是变量,"world"常量,变量 + 常量的结果在堆中
String s4 = s1 + s2; //s4字符串内容也是helloworld,s1和s2都是变量,变量 + 变量的结果在堆中
1、==:比较地址
2、equals(xx):比较字符串内容,严格区分大小写。因为String类型重写equals
3、equalsIgnoreCase(xx):比较字符串内容,不区分大小写
4、compareTo(xx):比较字符串的大小,按照字符编码值比较,严格区分大小写。String类型重写了Comparable接口的抽象方法,自然排序
5、compareToIgnoreCase(xx):比较字符串的大小,按照字符编码值比较,不区分大小写
String str1 = "";
String str2 = new String();
String str3 = new String("");
判断某个字符串是否是空字符串
if("".equals(str)) //推荐
if(str!=null && str.isEmpty())
if(str!=null && str.equals(""))
if(str!=null && str.length()==0)
| 方法签名 | 方法功能简介 | |
|---|---|---|
| 1 | String() | 创建空字符串 |
| 2 | String(String original) | 根据original创建一个新字符串 |
| 3 | static String valueOf(xx value) | 根据value内容创建一个字符串 |
| 4 | String intern() | 将字符串的内容存入常量池 |
| 5 | String concat() | 字符串拼接 |
| 6 | boolean equals(Object obj) | 判断当前字符串与指定字符串内容是否已在,严格区分大小写 |
| 7 | boolean equalsIgnoreCase(String obj) | 判断当前字符串与指定字符串内容是否已在,不区分大小写 |
| 8 | int compareTo(String str) | 比较当前字符串与指定字符串的大小,严格区分大小写 |
| 9 | int compareToIgnoreCase(String str) | 比较当前字符串与指定字符串的大小,不区分大小写 |
| 10 | boolean isEmpty() | 判断当前字符串是否为空 |
| 11 | int length() | 返回当前字符串的长度 |
| 12 | String toLowerCase() | 将当前字符串转为小写 |
| 13 | String toUpperCase() | 将当前字符串转为大写 |
| 14 | String trim() | 去掉当前字符串前后空白符 |
| 15 | boolean contains(xx) | 判断当前字符串中是否包含xx |
| 16 | int indexOf(xx) | 在当前字符串中查找xx第一次出现的下标 |
| 17 | int lastIndexOf(xx) | 在当前字符串中查找xx最后一次出现的下标 |
| 18 | String substring(int beginIndex) | 从当前字符串的[beginIndex, 最后]截取一个子串 |
| 19 | String substring(int beginIndex, int endIndex) | 从当前字符串的[beginIndex, endIndex)截取一个子串 |
| 20 | char charAt(index) | 返回当前字符串[index]位置字符 |
| 21 | char[] toCharArray() | 将当前字符串的内容用一个字符数组返回 |
| 22 | String(char[] value) | 用value字符数组的元素构建一个新字符串 |
| 23 | String(char[] value,int offset, int count) | 用value字符数组的[offset]开始的count个字符构建一个新字符串 |
| 24 | static String copyValueOf(char[] data) | 用data字符数组的元素构建一个新字符串 |
| 25 | static String copyValueOf(char[] data, int offset, int count) | 用data字符数组的[offset]开始的count个字符构建一个新字符串 |
| 26 | static String valueOf(char[] data) | 用data字符数组的元素构建一个新字符串 |
| 27 | static String valueOf(char[] data, int offset, int count) | 用data字符数组的[offset]开始的count个字符构建一个新字符串 |
| 28 | byte[] getBytes() | 将当前字符串按照平台默认字符编码方式编码为字节序列 |
| 29 | byte[] getBytes(字符编码方式) | 将当前字符串按照指定字符编码方式编码为字节序列 |
| 30 | String(byte[] bytes) | 将bytes字节序列按照平台默认字符编码方式解码为字符串 |
| 31 | String(byte[] bytes,String charsetName) | 将bytes字节序列按照指定字符编码方式解码为字符串 |
| 32 | boolean startsWith(xx) | 判断当前字符串是否以xx开头 |
| 33 | boolean endsWith(xx) | 判断当前字符串是否以xx结尾 |
| 34 | boolean matchs(xx) | 判断当前字符串是否满足xx正则 |
| 35 | String replace(xx,yy) | 将当前字符串中所有xx替换为yy |
| 36 | String replaceFirst(xx,value) | 将当前字符串中第一个满足xx正则的字符替换为value |
| 37 | String repalceAll(xx, value) | 将当前字符串中所有满足xx正则的字符替换为value |
| 38 | String[] split(xx) | 将当前字符串按照xx正则拆分为多个字符串 |
| 39 | void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin) | 将当前字符串的[srtBegin,srcEnd)部分字符复制到dst字符数组中,dst数组从[dstBegin]开始存储 |
String类的对象是不可变字符序列,StringBuffer和StringBuilder的对象是可变字符序列。
StringBuilder:JDK1.5之后引入的,线程不安全,单线程情况下推荐使用。
常用的API,StringBuilder、StringBuffer的API是完全一致的
| 方法签名 | 方法区功能简介 | |
|---|---|---|
| 1 | StringBuffer() | 创建一个空的可变字符序列,默认长度16 |
| 2 | StringBuffer(String str) | 用字符串str内容创建一个可变字符序列 |
| 3 | StringBuffer append(数据类型 b) | 在当前字符序列后面追加b |
| 4 | StringBufferinsert(int index, 数据类型 s) | 在当前字符序列[index]插入s |
| 5 | StringBuffer delete(int start, int end) | 删除当前字符序列[start,end)部分字符 |
| 6 | StringBuffer deleteCharAt(int index) | 删除当前字符序列[index]位置字符 |
| 7 | void setLength(int newLength) | 修改当前字符序列的长度为newLength |
| 8 | void setCharAt(int index, char ch) | 替换当前字符序列[index]位置字符为ch |
| 9 | StringBuffer reverse() | 将当前字符序列内容反转 |
| 10 | StringBuffer replace(int start, int end, String str) | 替换当前字符序列[start,end)部分字符为str |
| 11 | int indexOf(String str) | 在当前字符序列中开始查找str第一次出现的下标 |
| 12 | int indexOf(String str, int fromIndex) | 在当前字符序列[fromIndex]开始查找str第一次出现的下标 |
| 13 | int lastIndexOf(String str) | 在当前字符序列中开始查找str最后一次出现的下标 |
| 14 | int lastIndexOf(String str, int fromIndex) | 在当前字符序列[fromIndex]开始查找str最后一次出现的下标 |
| 15 | String substring(int start) | 截取当前字符序列[start,最后]部分构成一个字符串 |
| 16 | String substring(int start, int end) | 截取当前字符序列[start,end)部分构成一个字符串 |
| 17 | String toString() | 将当前可变字符序列的内容用String字符串形式表示 |
| 18 | void trimToSize() | 如果缓冲区大于保存当前字符序列所需的存储空间,则将重新调整其大小,以便更好地利用存储空间。 |
| 19 | int length() | 返回当前字符序列的长度 |
| 20 | char charAt(int index) | 返回当前字符序列[index]位置字符 |
| 21 | void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin) | 将当前字符串的[srtBegin,srcEnd)部分字符复制到dst字符数组中,dst数组从[dstBegin]开始存储 |
32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
为解决一个问题:如果一份文档中含有不同国家的不同语言的字符,那么无法在一份文档中显示所有字符。Unicode字符集涵盖了目前人类使用的所有字符,并为每个字符进行统一编号,分配唯一的字符码(Code Point)
Unicode只是定义了一个庞大的、全球通用的字符集,并为每个字符规定了唯一确定的编号,具体存储成什么样的字节流,取决于字符编码方案。推荐的Unicode编码是UTF-16
和UTF-8。
标签:字符编码 oschina 情况 元素 统一 拆分 梦想 rar 字符替换
原文地址:https://www.cnblogs.com/Open-ing/p/11965514.html