标签:targe aop where HERE user 创建目录 hadoop2 limit 默认
首先准备工具环境:hadoop2.7+mysql5.7+sqoop1.4+hive3.1
准备一张数据库表:


接下来就可以操作了。。。
一、将MySQL数据导入到hdfs
首先我测试将zhaopin表中的前100条数据导出来,只要id、jobname、salarylevel三个字段。
再Hdfs上创建目录
hadoop fs -mkdir -p /data/base #用于存放数据
我们cd到sqoop目录下执行命令
# \ 用于换行
bin/sqoop import --connect jdbc:mysql://172.18.96.151:3306/zhilian \ #连接数据库 --username root \ #用户名 --password 123456 \ #密码 --query ‘select id, jobname, salarylevel from zhaopin where $CONDITIONS LIMIT 100‘ \ #选取表的字段信息 --target-dir /data/base \ #上传到Hdfs的目录 --delete-target-dir \ #如果指定文件目录存在则先删除掉 --num-mappers 1 \ #使用1个map并行任务 --compress \ #启动压缩 --compression-codec org.apache.hadoop.io.compress.SnappyCodec \ #指定hadoop的codec方式 默认为gzip --direct \ #使用直接导入方式,优化导入速度 --fields-terminated-by ‘\t‘ #字段之间通过空格分隔
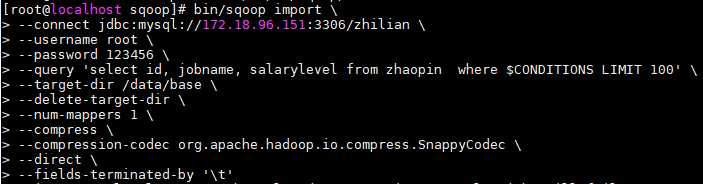
当你看到下面信息,就成了。。。
hadoop fs -ls -R /data/hbase #查看目录发现多了两个文件,我们就成功将数据导入到了hdfs
二、将hfds数据导入到Hive
首先我们先在hive中创建一个表,我们直接在默认的库中创建一个表。
drop table if exists default.hive_zhaopin_snappy ; #如果存在就先删除 create table default.hive_zhaopin_snappy( id int, jobname string, salarylevel string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t‘ ; #这个地方是标记分割字段的,\t为空格分隔,否则会在导入的hive表中都是NULL.
类似于这样
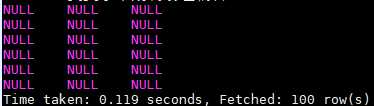
接下来就是导入环节了,在hive下执行命令:
load data inpath ‘/data/base/‘ into table default.hive_zhaopin_snappy ;

查看一下结果:
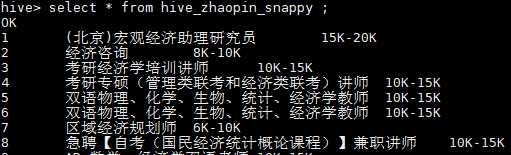
返回hdfs查看发现,base目录下原有的两个文件少了一个,它被移动到hive的hdfs存储中去了

三、用sqoop直接将mysql数据导入hive中
首先我们再创建一张表
create table default.hive_zhaopin_jingji( id int, jobname string, salarylevel string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t‘ ;
然后cd到sqoop目录下,执行命令
bin/sqoop import --connect jdbc:mysql://172.18.96.151:3306/zhilian \ #连接mysql必备 --username root --password 123456 --table zhaopin \ #要连接的表 --fields-terminated-by ‘\t‘ \ #字段通过空格分隔 --delete-target-dir \ #如果目录存在就删除 --num-mappers 1 \ #启动一个Map并行任务 --hive-import \ #执行导入Hive --hive-database default \ #导入到默认的default库 --hive-table hive_zhaopin_jingji #导入到hive_zhaopin_jingji表中

执行玩这些,表示没有报错。

查看了一下,数据都是对的。
倘若你的程序每次执行都会卡在job执行的时刻,那么应该是你的yarn-site.xml配置错误,仔细检查一下确保字母没有写错。
OVER。。。
标签:targe aop where HERE user 创建目录 hadoop2 limit 默认
原文地址:https://www.cnblogs.com/jake-jin/p/11966382.html