标签:根据 成功 传递 池化 训练 att 网络 通过 inline
最近看了些关于attention的文章。Attention是比较好理解的人类视觉机制,但怎么用在计算机问题上并不简单。
实际上15年之前就已经有人将attention用于视觉任务,但为什么17年最简单的SENet取得了空前的成功?其中一个原因是,前人的工作大多考虑空间上的(spatial)注意力,而SENet另辟蹊径,考虑了特征(通道)维度的注意力;第二个是实现方式,SENet本质上只是一个非常简单的结构,但赐予了神经网络更强大的学习能力,并且作者实现得也很好,所以最终性能才爆表(夺得了17年分类任务冠军)。
当然,attention在high-level任务中用得比较多,在low-level任务上主要是以saliency的形式呈现的。
至今没有 在图像分类任务上达到SOTA 且 将attention用于前向网络设计 的工作。因为大家都在关注网络的深度。【那么本文就通过高超的实现手法,做第一个吃螃蟹的人咯】【实际上,之前的SENet实现了突破。只不过SENet不算一个网络,而是一个即插即用的简单插件】
加入attention机制最核心的优势就是一点:可以让网络的鉴别式特征表示能力更强。【查了一下,生成网络+attention已经有很多工作了】
当然,本文因为独特的网络设计,带来了额外的attention优势。这在介绍网络时再说。我们先看看示意图和效果:

如图左,本文的注意力模块就是简单地根据输入特征,生成masks,然后与输入特征综合得到输出。
如图右,不同level的mask有不同的关注点。low-level的mask关注到了背景,比如天空和建筑;high-level的mask只关注气球的底部。
[23]证实:注意力机制对人类感知很重要。特别地,人类通过自上而下的信息传递,来指导自下而上的信息处理过程。【博主理解:根据上下文(context)决定attention属于自上而下,而看到字符产生语义理解属于自下而上】
Attention已经被RNN和LSTM广泛使用。在图像分类领域,这种自上而下的attention机制有三种表现形式:
序列化。将图像分类作为一个序列化的决策过程。
Region proposal。由于图像分类问题中的proposals一般没有ground truth,因此通常采用非监督学习。
控制门。如LSTM和Highway Network。
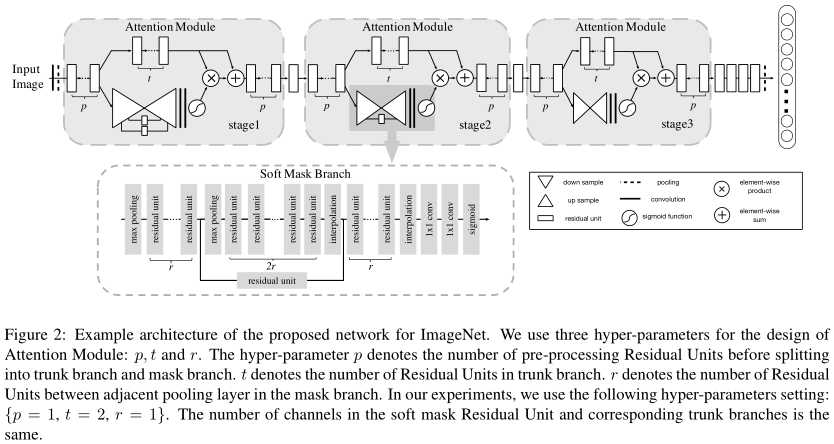
图像首先经过\(p=1\)个residual unit的处理,然后分别进入主干分支(上方)和mask分支。
主干分支有\(t=2\)个residual unit。
Mask分支是一个soft attention结构,如图下方所示。\(r=1\)就是两个最大池化层之间的residual unit数量。根据图例,这是一个先降采样、后升采样的网络结构。
Attention计算后,与主干的输出点乘,然后再与主干的输出求和。
以上流程在一个attention module中实现。作者令其重复3次。
作者认为,另设一个mask分支有两个好处:
特征的选择作用。【这一点是attention的好处,与该分支关系其实不大】
对梯度也有控制作用。比如抑制噪声区域的梯度。【作者没有证实这一点,而仅仅展示了对噪声的健壮性】
那么为什么要堆叠这么多attention module呢?一个mask分支[17]不就够了吗?这实际上已经通过Fig1解释了:不同level的注意力是有区别的,因此最好能够分开学习。
仅仅有attention是不行的【原因作者没有很好地解释。个人认为原因和ResNet的动机一样:这种mask分支破坏了梯度传播的通道,导致深度网络训练困难】。
为此,我们再把短连接加上呗~即mask与主干输出相乘后,再与主干输出相加。可以理解为:相乘的结果是对主干输出的微小调整,即作为残差。
设想一种极端情况:此时我们完全不需要对特征进行任何attention调整,则mask为0就行。Mask分支的学习完全没有难度。
最后这个概念来源于DBN[21],与本文的区别只在于应用场景。如图:
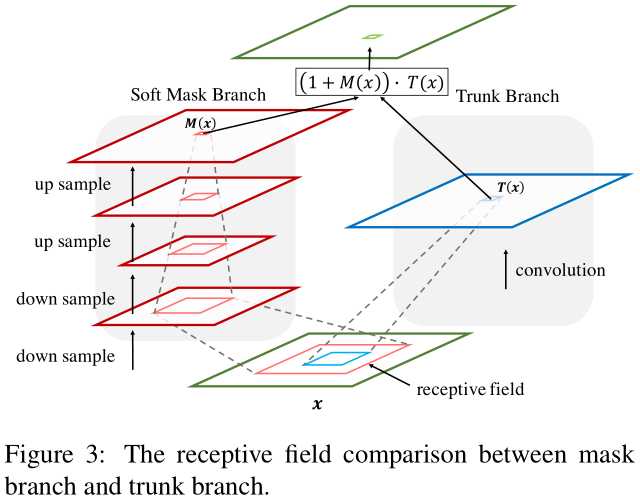
右侧就是自下而上的快速推导过程,左侧就是缓慢的自上而下的过程。什么是自上而下?由于mask分支在不断降采样(最大池化)以及卷积,因此其感受野越来越大。在最顶层,习得mask是一种相对高层的信息。Mask与右侧相乘,相当于用高层信息指导特征,因此称为自上而下的信息传递。
作者还考虑了一下对mask(attention)的正则化。要么是简单的sigmoid正则化,要么是根据所有通道在该点的均值和方差进行正则化然后再sigmoid,要么是除以该通道的均值。实验发现,最简单的(不约束)最好。
其余略。
Paper | Residual Attention Network for Image Classification
标签:根据 成功 传递 池化 训练 att 网络 通过 inline
原文地址:https://www.cnblogs.com/RyanXing/p/residual_attention_network.html