标签:方便 论文 根据 数据 学习 http net image bsp
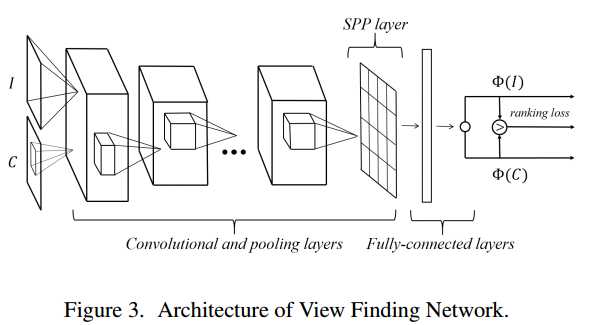
这篇论文的思路基于一个简单的假设:专业摄影师拍出来的图片一般具备比较好的构图,而如果从他们的图片中随机抠出一块,那抠出的图片大概率就毁了。也就是说,原图在构图方面的分数应该高于抠出来的图片。而这种比较的方式,可以很方便地用 Siamese Network 和 hinge loss 实现。另外,这篇论文另一个讨人喜欢的地方在于,它几乎不需要标注数据,只需要在网上爬取很多专业图片,再随机抠图就可以快速构造大量训练样本,因此成本近乎为零,即使精度不高也可以接受。
当然,这篇论文的训练方式只能让网络知道哪种图片的构图好,而无法自动从原图中抠出构图好的图块,因此,在抠图方面,采用的是滑动窗口的策略,并根据网络输出的分数决定哪个窗口最好。
dataset.pkl是数据集信息,它是一个长度为294644的列表,包含了21046张原图的14个裁剪图,其中scale为0.5、0.6的border crops各4个,scale为0.7、0.8的square crops各3个,作者公开的代码里,目的就是从这14个裁剪图中,选出裁剪效果最好的一个
论文学习——《Learning to Compose with Professional Photographs on the Web》 (ACM MM 2017)
标签:方便 论文 根据 数据 学习 http net image bsp
原文地址:https://www.cnblogs.com/yuehouse/p/11941842.html