标签:tab false 语句 文件 rest 替换 标准 data book
1)事实上的标准
MySQL、Oacle、DB2、SQL Server都是用的SQL操作,DBA、运维人员使用SQL门槛比较低
2)易学易用
SQL对于不懂的人学习较容易
3)受众面广
无论做Java、.Net、Php都需要与数据库交互,都需要编写SQL
Hive:
类似于SQL的Hive QL语言,sql语句转换为MapReduce作业提交到集群运行
优点:
易用、好上手、门槛低
缺点:
底层基于MapReduce框架,效率比较低,导致Hive效率也比较高
改进:
hive on tez、hive on spark、hive on mapreduce
shark(hive on spark)
hive跑在spark之上
优点
基于Spark框架,基于内存的,所以处理的比较快
采用内存的列式存储
与hive能够兼容
缺点
hive ql的解析、逻辑执行计划的生成、执行计划的优化都是依赖于hive的
仅仅是把物理执行计划从mr作业替换成spark作业,对hive的依赖性比较大,对于新添加功能很不方便
后来shark终止
Spark终止后产生了2个分支
1)hive on spark
Hive社区,源码在Hive中
2)Spark SQL
Spark社区,源码在Spark中
支持多种数据源,多种优化技术,扩展性好很多
1)Hive
facebook开源
将SQL转换为MapReduce作业
matastore:元数据,如果使用相同的一套元数据,Hive创建的表在Spark SQL、Impla都能访问
sql提供的功能和关系型数据库类似,有database、table、view
2)Impala
cloudera公司
cdh(建议在生产上使用的Hadoop系列版本,解决了很多版本依赖关系)
cm 提供了一个web页面,安装Hadoop、Hive、Hbase等可以通过图形化界面搭建
sql:自己的守护进程的,基于内存,非MapReduce
matastore:元数据
3)presto
facebook开源
基于sql
4)drill
基于sql
可以访问:hdfs、rdbms、json、hbase、mongodb、s3、hive
5)Spark SQL
基于sql
基于DataFrame/Dataset的API进行编程
matastore:元数据
可以访问:hdfs、rdbms、json、hbase、mongodb、s3、hive 外部数据源
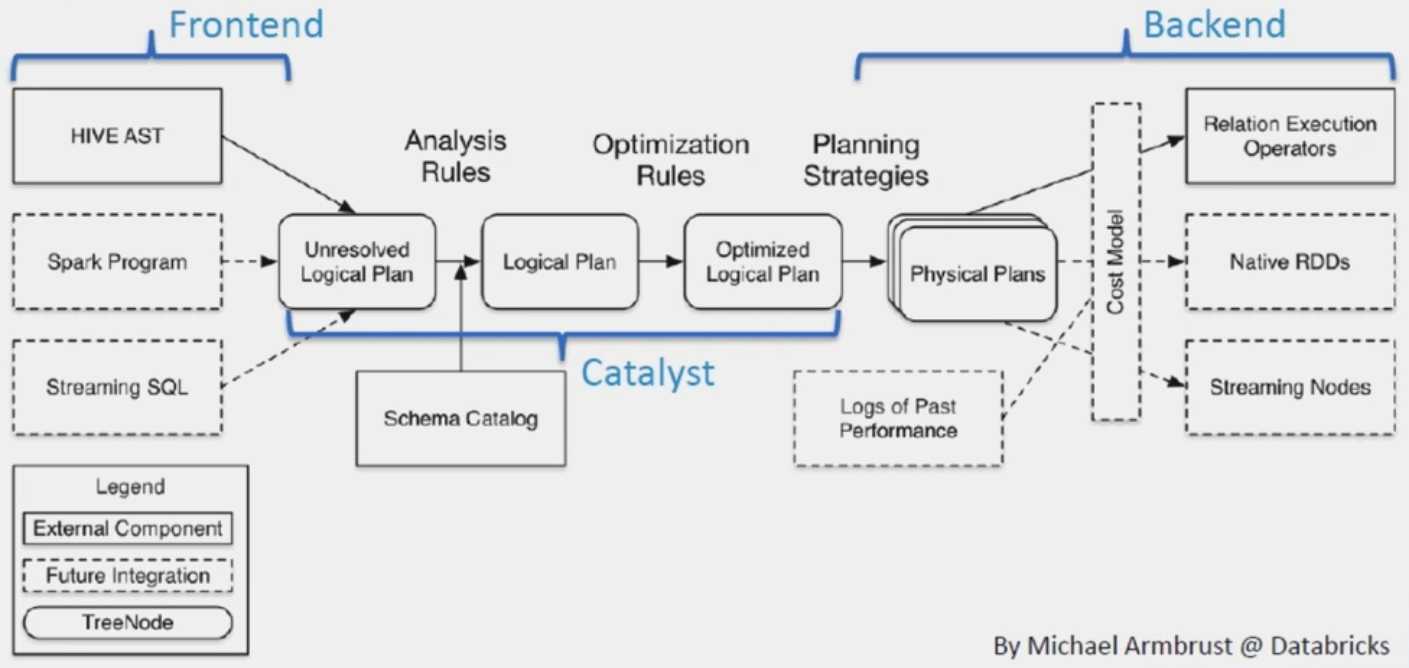
Spark SQL是Spark 1.0之后发布的核心分布式组件
Spark SQL可以运行SQL/Hive QL,包括UDFs、UDAFs和SerDes
可以通过JDBC连接已经存在的BI工具到Spark上
支持Python、Scala、Java和R语言
Spark SQL是Apache Spark的一个为了处理结构化的数据的模块
Spark SQL他不仅有访问或者操作SQL的功能,还提供了其他非常丰富的操作:外部数据源、优化
可以访问hdfs、rdbms、json、hbase、mongodb、s3、hive等文件的数据
Spark SQL提供了SQL的API、DataFrame/Dataset的API
写更少的代码
读更少的数据
把一些优化的工作交由底层优化器运行
标签:tab false 语句 文件 rest 替换 标准 data book
原文地址:https://www.cnblogs.com/yanceyy/p/11978306.html