标签:src config 权限 网络 获得 compress end eve 区别
python模块
一、什么是模块
1、模块:其实就是一个py文件;
(1)、模块的分类:
a、python官方库;
b、第三方模块;
c、自定义模块;
(2)、模块的调用(调用多个模块的时候使用逗号隔开)
a、调用方法
import 模块名;
from 模块名 import 变量名
b、路径
导入模块的时候解释器只认知当前执行文件的路径,在导入模块的时候尽量使用from 模块名 import 变量的方式;
import sys print(sys.path) ###解释器查找的路径;
c、导入模块的所做的动作:
先查找到文件名;
执行导入的文件;
备注:
a、文件书写规范:if __name__ == "__main__":
在执行文件里面的值为:__main__;
在调用文件里面的值为:被调用文件的路径;该书写规范主要用于被调用文件的测试,用于执行文件不想被别人调用
b、pycharm中文件夹与package的区别:init.py文件;
二、时间模块
1、时间戳
import time print(time.time()) ###1575013743.0178382返回的是以秒为单位
2、结构化时间
import time #print(time.time()) print(time.localtime()) ##time.struct_time(tm_year=2019, tm_mon=11, tm_mday=29, tm_hour=15, tm_min=52, tm_sec=21, tm_wday=4, tm_yday=333, tm_isdst=0) print(time.gmtime()) ###time.struct_time(tm_year=2019, tm_mon=11, tm_mday=29, tm_hour=7, tm_min=52, tm_sec=51, tm_wday=4, tm_yday=333, tm_isdst=0)
3、将结构化时间转换为时间戳
print(time.mktime(time.localtime())) ###1575251849.0
4、将结构化时间转换成字符串时间
print(time.strftime("%Y-%m-%d %X",time.localtime())) ##2019-12-02 10:01:27
5、将字符串时间转换成结构时间
print(time.strptime("2019-11-02 09:30:03","%Y-%m-%d %X")) ###结构化时间成功
6、asctime、ctime
##转换为特定格式 print(time.asctime()) ##默认参数为time.localtime(),参数为结构化时间 print(time.ctime(1565253090.0)) ##默认参数为time.time(),参数为时间戳
备注:集中时间格式之间的转换关系
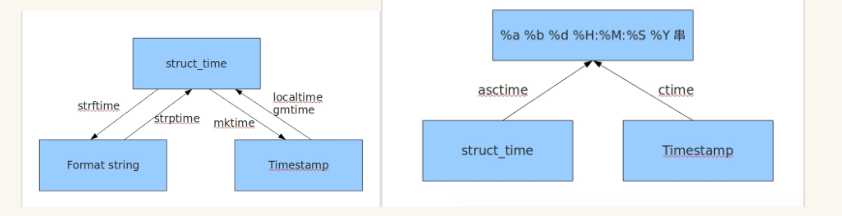
三、sys模块
time、sys模块都是内置在python解释器中的,都是有c语言实现的,属于同一级别;
###命令行参数list,第一个元素就是程序本身路径 print(sys.argv) #[‘D:/python project/python_learning/learning/day22/sys.test.py‘] ###获取python解释器程序的版本信息 print(sys.version) ##3.8.0 (tags/v3.8.0:fa919fd, Oct 14 2019, 19:37:50) [MSC v.1916 64 bit (AMD64)] ###返回模块的搜索路劲,初始化时环境变量的值 print(sys.path) ## ###返回操作系统平台名称: print(sys.platform) ###win32
备注:修改环境变量的两种方式:
1、临时添加:
sys.path.append("D:\python project\python_learning") ##临时添加
2、永久添加:
修改电脑的环境变量
3、获取文件上的上级目录BASE_DIR
###os.path.abspath(__file__)获取文件的绝对路径 BASE_DIR = os.path.dirname(os.path.abspath(__file__)) print(BASE_DIR) ###__file__只是一个文件名,在pycharm中打印的时候pycharm将文件的路径给补齐了。 print(os.path.abspath(__file__)) ###D:\python project\python_learning\learning\day22 print(__file__)###D:\python project\python_learning\learning\day22
四、os模块
os模块是与当前操作系统进行交互的一个接口
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: (‘.‘)
os.pardir 获取当前目录的父目录字符串名:(‘..‘)
os.makedirs(‘dirname1/dirname2‘) 可生成多层递归目录
os.removedirs(‘dirname1‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir(‘dirname‘) 生成单级目录;相当于shell中mkdir dirname
os.rmdir(‘dirname‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir(‘dirname‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat(‘path/filename‘) 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
备注:路径拼接使用join尽量不要使用“+”,因为有不用操作系统:在window上可以,在linux系统中就会出现问题;
五、json pickle模块
1、序列化
我们把对象从内存中变成可存储或可传输的过程称之为序列化,在python中称为pickling;
序列化之后,就可以把序列化后的内容写入磁盘或者通过网络传输到别的机器上;
反过来,把变量内容从序列化的对象重新读取到内存中称之为反序列化,即upickling。
2、JSON
我们要想在不同的编程语言之间传递对象,就必须把对象序列化为标准格式:xml和JSON。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对象关系如下:
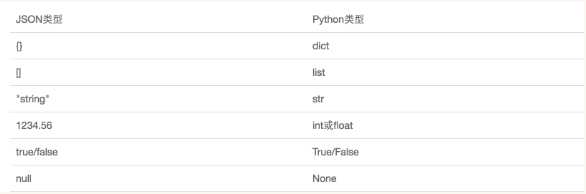
json的功能组:dumps/loads dump/load,主要以dumps/loads为主
无论数据是怎样创建的,只要满足json格式,就可以使用json.loads读取出来,不一定非要dumps的数据才能loads。
import json
dic={‘name‘:‘alvin‘,‘age‘:23,‘sex‘:‘male‘}
j=json.dumps(dic)
print(type(j))#<class ‘str‘>
f=open(‘序列化对象‘,‘w‘)
f.write(j) #-------------------等价于json.dump(dic,f)
f.close()
#-----------------------------反序列化<br>
import json
f=open(‘序列化对象‘)
data=json.loads(f.read())# 等价于data=json.load(f)
3、pickle:pickle与json的作用是一样的,只是json后的数据类型为json字符串,而pickle则是字节,是不可读的;json可以用于不同编程语言之间,pickle只能用于python。
六、XML模块
XML可扩展标记语言,分为自合标签和非自合标签,可以通过for循环去去遍历子节点和属性;
标签:tag;
属性:attrib;
标签实际包裹的内容:text;
1、XML模块的相关功能
import xml.etree.ElementTree as et
tree = et.parse("xml.text")
root = tree.getroot()
print(root.tag)
##1、遍历xml文档
###tag:标签;attrib:属性;text:标签实际包裹的内容
for i in root:
print(i.tag,i.attrib)
for j in i:
print(j.tag,j.attrib,j.text)
##2、只遍历year节点
for i in root.iter("year"):
print(i.tag,i.text)
##3、修改
for i in root.iter("year"):
new_year = int(i.text)+1
i.text = str(new_year)
i.set("updated","yes")
tree.write("xml_test") ##重新写入文件
###删除
for i in root.findall("country"):
rank = int(i.find("rank").text)
if rank >50:
root.remove(i)
tree.write("xml_test")
七、configparser模块
用于编辑配置文件的模块
import configparser
config = configparser.ConfigParser()
config["Default"]= {"ServerAliveInterval":"45",
"compression":"yes",
"compressionlevel":9}
config["bitbucket.org"] ={}
config["bitbucket.org"]["user"] = "heaton"
with open("config.ini","w") as configfile:
config.write(configfile)
八、hashlib模块
主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib
m = hashlib.md5() #m=hashlib.sha256()
m.update("heatonhello".encode("utf-8"))
print(m.hexdigest()) ##aef8d3fd8b44bd96aa0b2826f6362c82
##对加密算法中添加自定义key来做加密
hash = hashlib.sha256("heaton".encode("utf-8"))
hash.update("hello".encode("utf-8"))
print(hash.hexdigest()) ##2cf44f7e1e7173e80bae87536ff4bb8adf270dce2afb52ce36f46c3430c19258
九、re模块
正则表达式其实就是一种小型的、高度专业化的编程语言,它内嵌在python中,并通过re模块实现。正则表达式模式被编译成一系列的字节码,然后由用c编写的匹配引擎执行。
1、普通字符精确匹配
import re
res = re.findall("heaton","ludouw28heatonoowuoehwk")
print(res)
2、元字符匹配
元字符:.^$*+?{}[]|()\
(1)、元字符:. ^ $ * + ? { }
import re
# res = re.findall("heaton","ludouw28heatonoowuoehwk")
# print(res)
def print_fun(*args):
print(*args)
###(1)、通配符.
res = re.findall("h....n","oeowuowuheatonouowoow") ##[‘heaton‘]
print_fun(res)
###(2)、首行匹配^
res = re.findall("^h....n","oeowuowuheatonouowoow")
res1 = re.findall("^h....n","heoyunowueowo") ##[] [‘heoyun‘]
print_fun(res,res1)
###(3)、末尾匹配$
res = re.findall("h....n$","oeowuowuheatonouowoow")
res1 = re.findall("h....n$","dwoieowhwheiiun") ###[] [‘heiiun‘]
print_fun(res,res1)
###(4)、0到+∞:*
res = re.findall("abc*","abccccoiowiab")##[‘abcccc‘, ‘ab‘]
res1 = re.findall("abc*?","abccccoiowiab") ###[‘ab‘, ‘ab‘]
print_fun(res,res1)
###(5)、1到+∞:+
res = re.findall("abc+","abccccoiowiab")###[‘abcccc‘]
re1 = re.findall("abc+?","abccccoiowiab") ###[‘ab‘, ‘ab‘]
print_fun(res,res1)
###(6)、0到1:?
res = re.findall("abc?","abccccoiowiab")###[‘abc‘, ‘ab‘]
res1= re.findall("abc??","abccccoiowiab") ###[‘ab‘, ‘ab‘]
print_fun(res,res1)
###(7)、大括号可以设置匹配次数{}
res=re.findall(‘abc{1,4}‘,‘abcccccccoiowiab‘)
print_fun(res)
###备注:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
2、元字符:字符集:[]
起“或”的作用,在元字符集里面没有特殊字符,除了一下几个字符有特殊意义
备注:有特殊意义的:
"-":a-z,表示所有小写字母;
"^":尖角号,表示非
"\":转义符,把有意义的元字符变为普通字符,把普通字符转为有意义的字符;
import re
res = re.findall("x[yz]","xuyuwoeuosxzyuox*y")
res1 = re.findall("x[y*z]","xuyuwoeuosxzyuox*y")
print(res,res1,res2)
3、元字符:转义符:“\”
(1)、将普通字符转义为有意义的字符:反斜杠后边跟普通字符实现特殊功能:比如\d
import re
###1、"\d"匹配任何十进制,相当于[0-9]
ret = "zhangsan18 lisi23 wangwu5yuliu23"
res = re.findall("\d",ret)
res1 = re.findall("[0-9]",ret)
print(res,res1)
###2、"\D" 匹配任何非数字字符,相当于类[^0-9]
res = re.findall("\D",ret)
res1 = re.findall("[^0-9]",ret)
print(res,res1)
###3、"\s"匹配任何空白字符,相当于类[\n\n\f\v]
###"\S"匹配任何非空白字符,相当于类[^\n\n\f\v]
res = re.findall("\s",ret)
res1 = re.findall("\S",ret)
print(res,res1)
###4、"\w":匹配任何数字字母字符,相当于[A-Za-z0-9]
###"\W":匹配任何非数字字母字符,相当于[^A-Za-z0-9]
res = re.findall("\w",ret)
res1 = re.findall("\W",ret)
print(res,res1)
###5、\b匹配一个特殊字符边界,比如空格,&,#等
res = re.findall("I\b","hello I am LIST")
res1 = re.findall(r"I\b","hello I am LIST")
res2 = re.findall("I\\b","hello I am LIST")
print(res,res1,res2)
(2)、将有意义的元字符变成普通字符
import re
res = re.findall("www.baidu","wwwobaidu")
res1 = re.findall("www\.baidu","www.baidu") ###[‘wwwobaidu‘] [‘www.baidu‘]
print(res,res1)
(3)、转义字符特殊用法
import re
res = re.findall("www.baidu","wwwobaidu")
res1 = re.findall("www\.baidu","www.baidu") ###[‘wwwobaidu‘] [‘www.baidu‘]
print(res,res1)
res2 = re.findall("c\\f","adc\fuouk")
res3 = re.findall("c\\\\l","adc\louwe") ##[‘c\x0c‘] [‘c\\l‘]
print(res2,res3)
4、元字符:分组:()
import re
res = re.findall("www.baidu","wwwobaidu")
res1 = re.findall("www\.baidu","www.baidu") ###[‘wwwobaidu‘] [‘www.baidu‘]
print(res,res1)
res2 = re.findall("c\\f","adc\fuouk")
res3 = re.findall("c\\\\l","adc\louwe") ##[‘c\x0c‘] [‘c\\l‘]
print(res2,res3)
m = re.findall(r"(ad)+","add") ##[‘ad‘]
print(m)
m1 = re.search("(?P<host>\w+)\.(?P<houzui>[a-zA-Z]{3})","baidu.com")
ret=re.search(‘(?P<id>\d{2})\.(?P<name>\w{3})‘,‘23.com‘)
print(ret,m1)
print(ret.group(),m1.group())
print(ret.group("id"),m1.group("host"))
5、元字符:管道符:“|”
import re
ret = re.findall(r"ka|b","adka|oou")
ret1 = re.findall("ka|bc","soka|bcouwj")
print(ret,ret1)
6、re模块常用函数
import re
###1、findall返回所有满足匹配条件的结果,放在列表里
ret = re.findall(r"ka|b","adka|oou")
ret1 = re.findall("ka|bc","soka|bcouwj")
print(ret,ret1)
###2、search函数会在字符串内查找模式匹配,直到找到第一个匹配然后返回一个匹配信息的对象
###该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None
ret = re.search("a..x","alvxn yuanabcx").group()
print(ret)
###3、通search,只在字符串开始处进行匹配
ret = re.match("abc","abccc").group()
print(ret)
###4、split先按照“a”分割得到‘‘和‘bcd’,在对‘‘和‘bcd‘分别按‘‘分割
ret = re.split(‘[ab]‘,‘abcd‘)
print(ret)
###5、sub方法:替换函数
ret = re.sub(‘\d‘,‘abc‘,‘alvin6heaton7‘,1)
ret1 = re.sub(‘\d‘,‘abc‘,‘alvin6heaton7‘,2) ##alvinabcheaton7 alvinabcheatonabc
ret2 = re.subn(‘\d‘,‘abc‘,‘alvin6heaton7‘) ##(‘alvinabcheatonabc‘, 2)
print(ret,ret1,ret2)
###6、complile编译:编译规则
com = re.compile("\d+")
ret = com.findall("zhangsan212lisi234")
print(ret) ###[‘212‘, ‘234‘]
###finditer:查找结果为一个迭代对象
ret = re.finditer("\d+","zhangsan212lisi234")
print(ret)
res = ret.__next__()
print(res.group())
###备注: findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret = re.findall("www.(baidu|oldboy).com","www.oldboy.com")
print(ret) ##[‘oldboy‘]
ret1 = re.findall("www.(?:baidu|oldboy).com","www.oldboy.com")
print(ret1) ##[‘www.oldboy.com‘]
十、logging模块
1、logging日志模块基本格式:
import logging
logging.debug("debug message")
logging.info("info message")
logging.warning("warning message")
logging.error("error message")
logging.critical("critical message")
###输出:
"""
WARNING:root:warning message
ERROR:root:error message
CRITICAL:root:critical message
"""
备注:默认情况下logging模块将日志打印到标准输出中,且只是显示了大于等于warning基本的日志(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET);
2、配置日志输出格式
import logging
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s %(filename)s [line:%(lineno)d] $(linename)s %(message)s",
datefmt="%Y-%m-%d %X",
filename="D:\python project\python_learning\learning\day21/test.log",
filemode="w"
)
logging.debug("debug message")
logging.info("info message")
logging.warning("warning message")
logging.error("error message")
logging.critical("critical message")
###输出文件格式为:
"""
2019-12-04 11:27:27 logging_test.py [line:11] $(linename)s info message
2019-12-04 11:27:27 logging_test.py [line:12] $(linename)s warning message
2019-12-04 11:27:27 logging_test.py [line:13] $(linename)s error message
2019-12-04 11:27:27 logging_test.py [line:14] $(linename)s critical message
"""
###logging.basicConfig()函数的常用的可用参数说明
"""
filename:用指定的文件名称创建FiledHandler,这样日志会被存储在指定的文件夹
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”,还可指定为"w"
format:指定handler使用的日志显示格式
datefmt:指定日期格式
levle:设置rootlogger的日志显示级别
"""
3、logger对象
import logging
###常规格式的logger对象格式
logger = logging.getLogger()
##1、创建一个handler用于写入日志文件
fh = logging.FileHandler("D:\python project\python_learning\learning\day21\logger_test.log")
##2、创建一个handler用于输出到控制台
ch = logging.StreamHandler()
##3、日志格式
formatter = logging.Formatter("%(asctime)s-%(name)s-%(levelname)s-%(message)s")
##4、设置日志输出格式
fh.setFormatter(formatter)
ch.setFormatter(formatter)
##5、logger对象添加功能
logger.addHandler(fh)
logger.addHandler(ch)
logger.debug("logger debug message")
logger.info("logger info message")
logger.warning("logger warning message")
logger.error("logger error message")
logger.critical("logger critical message")
logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。
Logger是一个树形层级结构,输出信息之前都要获得一个Logger(如果没有显示的获取则自动创建并使用root Logger)。
logger = logging.getLogger()返回一个默认的Logger也即root Logger,并应用默认的日志级别、Handler和Formatter设置。
当然也可以通过Logger.setLevel(lel)指定最低的日志级别,可用的日志级别有logging.DEBUG、logging.INFO、logging.WARNING、logging.ERROR、logging.CRITICAL。
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical()输出不同级别的日志,只有日志等级大于或等于设置的日志级别的日志才会被输出
标签:src config 权限 网络 获得 compress end eve 区别
原文地址:https://www.cnblogs.com/tengjiang/p/11958107.html