标签:出现 class lam turn bsp als 技术 else com
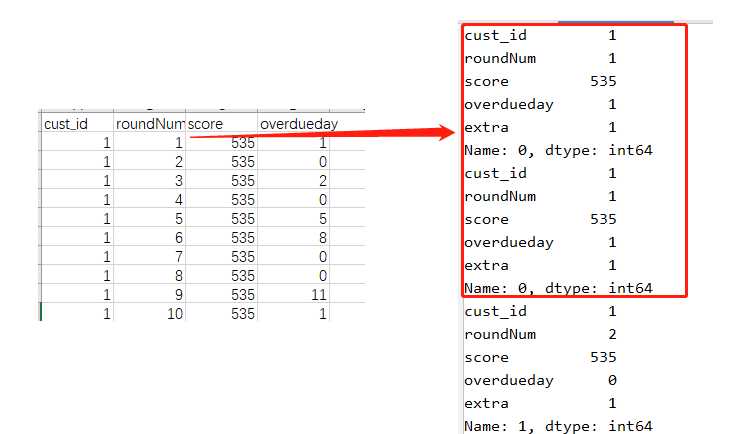
import pandas as pd data = pd.read_csv(r"test数据.csv", engine="python", encoding="utf-8") def pprint(row): row["extra"]=1 print(row) return row data = data.apply(lambda x: pprint(x), axis=1) print(data)
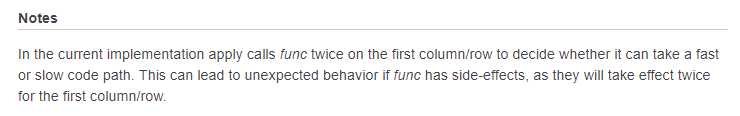
apply在第一列/行上调用func两次,以决定是否可以进行某些优化。
直接拿print使用,就不会出现 apply在第一列/行上调用func两次的情况。
data = data.apply(lambda x: print(x), axis=1)

我猜测先运行第一行式为了设置分配内存空间。
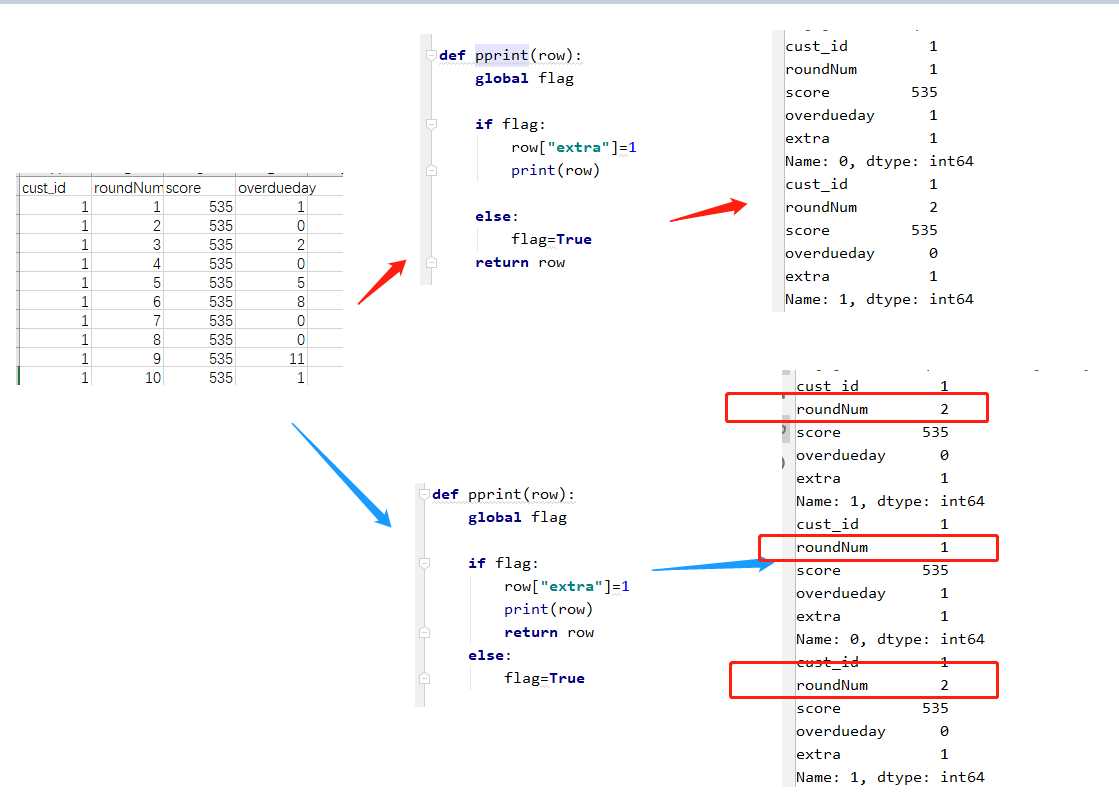
解决方案:
flag=False def pprint(row): global flag if flag: row["extra"]=1 print(row) else: flag=True
return row
data = data.apply(lambda x: pprint(x), axis=1) print(data)
pandas之dataframe踩坑指南(一)---apply(func)
标签:出现 class lam turn bsp als 技术 else com
原文地址:https://www.cnblogs.com/wqbin/p/11982099.html