标签:sqlite3 pre less normal div aggregate 对象 生成 模型
修改 settings.py 中的 DATABASES
注意:django框架不会自动帮我们生成mysql数据库,所以我们需要自己去创建。

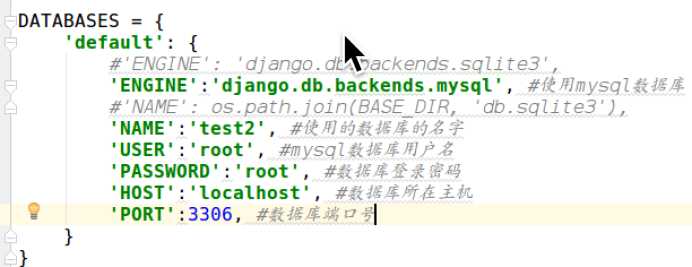
DATABASES = { ‘default‘: { # ‘ENGINE‘: ‘django.db.backends.sqlite3‘, # ‘NAME‘: os.path.join(BASE_DIR, ‘db.sqlite3‘), ‘ENGINE‘: ‘django.db.backends.mysql‘, ‘NAME‘ : ‘test2‘, ‘USER‘ : ‘root‘, ‘PASSWORD‘ : ‘123456‘, ‘HOST‘ : ‘localhost‘, ‘PORT‘ : 3306 } }
python3中安装好pymysql,需要在test2/__init__.py中加如下内容:
import pymysql
pymysql.install_as_MySQLdb()
启动服务的时候如出现错误
django.core.exceptions.ImproperlyConfigured: mysqlclient 1.3.13 or newer is required; you have 0.9.3.参照 https://www.cnblogs.com/ljd4you/p/8592765.html
__init__() missing 1 required positional argument: ‘on_delete‘ 参照https://www.cnblogs.com/phyger/p/8035253.html
1:打开文文件 (项目/应用/models.py)
2:创建model类 (1)必须继承 models.Model (2)类属性就是字段 示例如下
View Code 3:生成迁移文件:python manage.py makemigrations (项目/应用/migrations 目录下生成新文件)
4:执行迁移生成表:python manage.py migrate (默认数据库配置项在setting.py文件下 DATABASES 配置项)
5:模型类基本操作:参照 https://www.cnblogs.com/zhaoyang-1989/p/11970402.html
1)不能是python的保留关键字。
2)不允许使用连续的下划线,这是由django的查询方式决定的。
3)定义属性时需要指定字段类型,通过字段类型的参数指定选项,语法如下:属性名=models.字段类型(选项)
使用时需要引入django.db.models包,字段类型如下: 类型 描述 AutoField 自动增长的IntegerField,通常不用指定,不指定时Django会自动创建属性名为id的自动增长属性。 BooleanField 布尔字段,值为True或False。 NullBooleanField 支持Null、True、False三种值。 CharField(max_length=最大长度) 字符串。参数max_length表示最大字符个数。 TextField 大文本字段,一般超过4000个字符时使用。 IntegerField 整数 DecimalField(max_digits=None, decimal_places=None) 十进制浮点数。参数max_digits表示总位。参数decimal_places表示小数位数。 FloatField 浮点数。参数同上 DateField:([auto_now=False, auto_now_add=False]) 日期。 1)参数auto_now表示每次保存对象时,自动设置该字段为当前时间,用于"最后一次修改"的时间戳,它总是使用当前日期,默认为false。 2) 参数auto_now_add表示当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用当前日期,默认为false。 3)参数auto_now_add和auto_now是相互排斥的,组合将会发生错误。 TimeField 时间,参数同DateField。 DateTimeField 日期时间,参数同DateField。 FileField 上传文件字段。 ImageField 继承于FileField,对上传的内容进行校验,确保是有效的图片。
1)一对多关系 例:图书类-英雄类 models.ForeignKey() 定义在多的类中。 2)多对多关系 例:新闻类-新闻类型类 体育新闻 国际新闻 models.ManyToManyField() 定义在哪个类中都可以。 3)一对一关系 例:员工基本信息类-员工详细信息类. 员工工号 models.OneToOneField 定义在哪个类中都可以。
通过选项实现对字段的约束,选项如下:
选项名 描述
default 默认值。设置默认值。
primary_key 若为True,则该字段会成为模型的主键字段,默认值是False,一般作为AutoField的选项使用。
unique 如果为True, 这个字段在表中必须有唯一值,默认值是False。
db_index 若值为True, 则在表中会为此字段创建索引,默认值是False。
db_column 字段的名称,如果未指定,则使用属性的名称。
null 如果为True,表示允许为空,默认值是False。
blank 如果为True,则该字段允许为空白,默认值是False。
对比:null是数据库范畴的概念,blank是后台管理页面表单验证范畴的。
经验:
当修改模型类之后,如果添加的选项不影响表的结构,则不需要重新做迁移,商品的选项中default和blank不影响表结构。
通过模型类.objects属性可以调用如下函数,实现对模型类对应的数据表的查询。 函数名 功能 返回值 说明 get 返回表中满足条件的一条且只能有一条数据。 返回值是一个模型类对象。 参数中写查询条件。 1)如果查到多条数据,则抛异常MultipleObjectsReturned。 2)查询不到数据,则抛异常:DoesNotExist。 all 返回模型类对应表格中的所有数据。 返回值是QuerySet类型 查询集 filter 返回满足条件的数据。 返回值是QuerySet类型 参数写查询条件。 exclude 返回不满足条件的数据。 返回值是QuerySet类型 参数写查询条件。 order_by 对查询结果进行排序。 返回值是QuerySet类型 参数中写根据哪些字段进行排序。
mysql.log是mysql的日志文件,里面记录的对MySQL数据库的操作记录。默认情况下mysql的日志文件没有产生,需要修改mysql的配置文件,步骤如下: 1) 使用下面的命令打开mysql的配置文件,去除68,69行的注释,然后保存。sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf 2)重启mysql服务,就会产生mysql日志文件。sudo service mysql restart 3)打开MySQL的日志文件。/var/log/mysql/mysql.log 是mysql日志文件所在的位置。 使用下面的命令可以实时查看mysql的日志文件:sudo tail -f /var/log/mysql/mysql.log
例:查询图书id为3的图书信息。BookInfo.objects.find(id=1) 例:查询图书所有信息。all方法示例:BookInfo.objects.all() filter方法示例:BookInfo.objects.filter(id=1) 条件格式:模型类属性名__条件名=值 查询图书评论量为34的图书的信息: a)判等 条件名:exact。 例:查询编号为1的图书.BookInfo.objects.get(id=1) b)模糊查询例:查询书名包含‘传‘的图书。contains | BookInfo.objects.filter(btitle__contains=‘传‘) 例:查询书名以‘部‘结尾的图书 endswith 开头:startswith | BookInfo.objects.filter(btitle__endswith=‘部‘) c)空查询 isnull 例:查询书名不为空的图书。isnull | select * from booktest_bookinfo where btitle is not null; |BookInfo.objects.filter(btitle__isnull=False) d)范围查询 in 例:查询id为1或3或5的图书。 select * from booktest_bookinfo where id in (1,3,5); BookInfo.objects.filter(id__in = [1,3,5]) e)比较查询 gt(greate than) lt(less than) gte(equal) 大于等于lte 小于等于 例:查询id大于3的图书。 Select * from booktest_bookinfo where id>3; | BookInfo.objects.filter(id__gt=3) f)日期查询 例:查询1980年发表的图书。 BookInfo.objects.filter(bpub_date__year=1980) from datetime import date | exclude方法示例:例:查询id不为3的图书信息。 BookInfo.objects.exclude(id=3) order_by方法示例: 作用:进行查询结果进行排序。 例:查询所有图书的信息,按照id从小到大进行排序。 BookInfo.objects.all().order_by(‘id‘) 例:查询所有图书的信息,按照id从大到小进行排序。 BookInfo.objects.all().order_by(‘-id‘) 例:把id大于3的图书信息按阅读量从大到小排序显示。 BookInfo.objects.filter(id__gt=3).order_by(‘-bread‘)
作用:用于类属性之间的比较。 使用之前需要先导入: from django.db.models import F 例:查询图书阅读量大于评论量图书信息。BookInfo.objects.filter(bread__gt=F(‘bcomment‘)) 例:查询图书阅读量大于2倍评论量图书信息。BookInfo.objects.filter(bread__gt=F(‘bcomment‘)*2)
作用:用于查询时条件之间的逻辑关系。not and or,可以对Q对象进行&|~操作。 使用之前需要先导入: from django.db.models import Q 例:查询id大于3且阅读量大于30的图书的信息。 BookInfo.objects.filter(id__gt=3, bread__gt=30) 或者BookInfo.objects.filter(Q(id__gt=3)&Q(bread__gt=30)) 例:查询id大于3或者阅读量大于30的图书的信息。BookInfo.objects.filter(Q(id__gt=3)|Q(bread__gt=30)) 例:查询id不等于3图书的信息。BookInfo.objects.filter(~Q(id=3))
作用:对查询结果进行聚合操作。 sum count avg max min aggregate:调用这个函数来使用聚合。 返回值是一个字典 使用前需先导入聚合类: from django.db.models import Sum,Count,Max,Min,Avg 例:查询所有图书的数目。BookInfo.objects.all().aggregate(Count(‘id‘)) {‘id__count‘: 5} 例:查询所有图书阅读量的总和。BookInfo.objects.aggregate(Sum(‘bread‘)) {‘bread__sum‘: 126} count函数 返回值是一个数字 作用:统计满足条件数据的数目。
例:统计所有图书的数目。BookInfo.objects.all().count() 或者 BookInfo.objects.count() 例:统计id大于3的所有图书的数目。BookInfo.objects.filter(id__gt=3).count()
1 查询和对象关联的数据 在一对多关系中,一对应的类我们把它叫做一类,多对应的那个类我们把它叫做多类,我们把多类中定义的建立关联的类属性叫做关联属性。 例:查询id为1的图书关联的英雄的信息。 b=BookInfo.objects.get(id=1) b.heroinfo_set.all() 通过模型类查询: HeroInfo.objects.filter(hbook__id=1) 例:查询id为1的英雄关联的图书信息。 h = HeroInfo.objects.get(id=1) h.hbook 通过模型类查询: BookInfo.objects.filter(heroinfo__id=1) 由一类的对象查询多类的时候: 一类的对象.多类名小写_set.all() #查询所用数据 由多类的对象查询一类的时候: 多类的对象.关联属性 #查询多类的对象对应的一类的对象 由多类的对象查询一类对象的id时候: 多类的对象. 关联属性_id
例:查询图书信息,要求图书关联的英雄的描述包含‘八‘。BookInfo.objects.filter(heroinfo__hcomment__contains=‘八‘) 例:查询图书信息,要求图书中的英雄的id大于3.BookInfo.objects.filter(heroinfo__id__gt=3) 例:查询书名为“天龙八部”的所有英雄。HeroInfo.objects.filter(hbook__btitle=‘天龙八部‘) 通过多类的条件查询一类的数据: 一类名.objects.filter(多类名小写__多类属性名__条件名) 通过一类的条件查询多类的数据: 多类名.objects.filter(关联属性__一类属性名__条件名)
get示例:
例:查询图书id为3的图书信息。
all方法示例:
例:查询图书所有信息。
filter方法示例:
条件格式:
模型类属性名__条件名=值
查询图书评论量为34的图书的信息:
a)判等 条件名:exact。
例:查询编号为1的图书。
BookInfo.objects.get(id=1)
b)模糊查询
例:查询书名包含‘传‘的图书。contains
BookInfo.objects.filter(btitle__contains=‘传‘)
例:查询书名以‘部‘结尾的图书 endswith 开头:startswith
BookInfo.objects.filter(btitle__endswith=‘部‘)
c)空查询 isnull
例:查询书名不为空的图书。isnull
select * from booktest_bookinfo where btitle is not null;
BookInfo.objects.filter(btitle__isnull=False)
d)范围查询 in
例:查询id为1或3或5的图书。
select * from booktest_bookinfo where id in (1,3,5);
BookInfo.objects.filter(id__in = [1,3,5])
e)比较查询 gt(greate than) lt(less than) gte(equal) 大于等于
lte 小于等于
例:查询id大于3的图书。
Select * from booktest_bookinfo where id>3;
BookInfo.objects.filter(id__gt=3)
f)日期查询
例:查询1980年发表的图书。
BookInfo.objects.filter(bpub_date__year=1980)
例:查询1980年1月1日后发表的图书。
from datetime import date
BookInfo.objects.filter(bpub_date__gt=date(1980,1,1))
exclude方法示例:
例:查询id不为3的图书信息。
BookInfo.objects.exclude(id=3)
order_by方法示例:
作用:进行查询结果进行排序。
例:查询所有图书的信息,按照id从小到大进行排序。
BookInfo.objects.all().order_by(‘id‘)
例:查询所有图书的信息,按照id从大到小进行排序。
BookInfo.objects.all().order_by(‘-id‘)
例:把id大于3的图书信息按阅读量从大到小排序显示。
BookInfo.objects.filter(id__gt=3).order_by(‘-bread‘)
标签:sqlite3 pre less normal div aggregate 对象 生成 模型
原文地址:https://www.cnblogs.com/zhaoyang-1989/p/11987477.html
