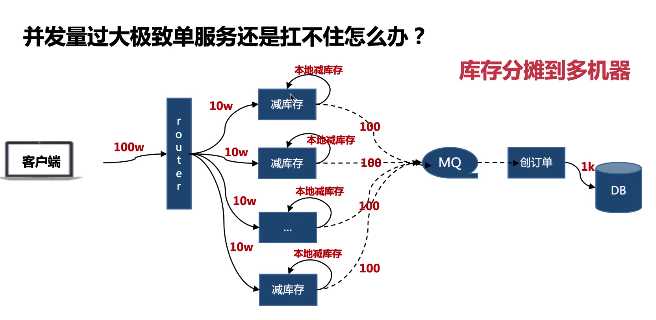
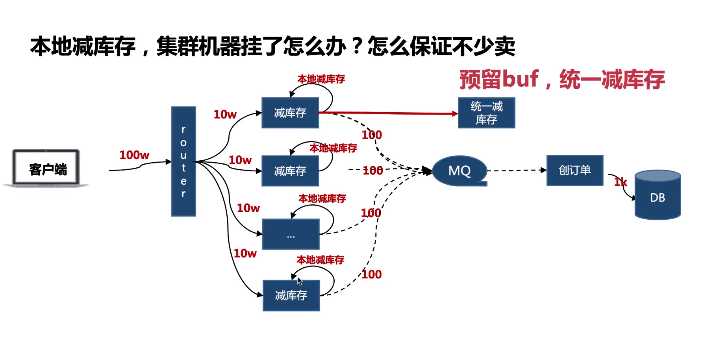
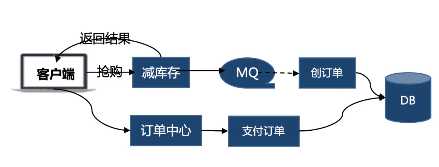
标签:theme 次数 商城 xtend tput bsp 概率 err 提示
1 <?php 2 class Base{ 3 static $redisObj; 4 /*通过单例方式初始化一个redis连接*/ 5 static function conRedis($config = array()){ 6 if(self::$redisObj) return self::$redisObj; 7 self::$redisObj = new \Redis(); 8 self::$redisObj->connect(‘127.0.0.1‘, 6379); 9 return self::$redisObj; 10 } 11 /*接口输出格式化*/ 12 static function output($data = array(), $errNo = 0, $errMsg = ‘ok‘){ 13 $res[‘errno‘] = $errNo; 14 $res[‘errmsg‘] = $errMsg; 15 $res[‘data‘] = $data; 16 echo json_encode($res); 17 exit(); 18 } 19 }
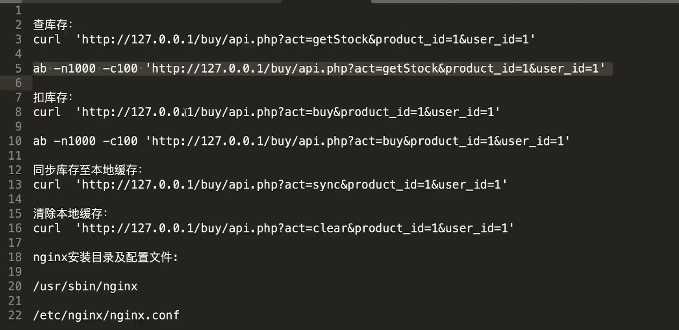
1 <?php 2 include(‘base.php‘); 3 class Api extends Base 4 { 5 //共享信息,存储在redis中,以hash表的形式存储,%s变量代表的是商品id 6 static $userId; 7 static $productId; 8 static $REDIS_REMOTE_HT_KEY = "product_%s"; //共享信息key 9 static $REDIS_REMOTE_TOTAL_COUNT = "total_count"; //商品总库存 10 static $REDIS_REMOTE_USE_COUNT = "used_count"; //已售库存 11 static $REDIS_REMOTE_QUEUE = "c_order_queue"; //创建订单队列 12 static $APCU_LOCAL_STOCK = "apcu_stock_%s"; //总共剩余库存 13 static $APCU_LOCAL_USE = "apcu_stock_use_%s"; //本地已售多少 14 static $APCU_LOCAL_COUNT = "apcu_total_count_%s"; //本地分库存分摊总数 15 public function __construct($productId, $userId) 16 { 17 self::$REDIS_REMOTE_HT_KEY = sprintf(self::$REDIS_REMOTE_HT_KEY, $productId); 18 self::$APCU_LOCAL_STOCK = sprintf(self::$APCU_LOCAL_STOCK, $productId); 19 self::$APCU_LOCAL_USE = sprintf(self::$APCU_LOCAL_USE, $productId); 20 self::$APCU_LOCAL_COUNT = sprintf(self::$APCU_LOCAL_COUNT, $productId); 21 self::$APCU_LOCAL_COUNT = sprintf(self::$APCU_LOCAL_COUNT, $productId); 22 self::$userId = $userId; 23 self::$productId = $productId; 24 } 25 static function clear(){ 26 apcu_delete(self::$APCU_LOCAL_STOCK); 27 apcu_delete(self::$APCU_LOCAL_USE); 28 apcu_delete(self::$APCU_LOCAL_COUNT); 29 30 } 31 /*查剩余库存*/ 32 static function getStock() 33 { 34 $stockNum = apcu_fetch(self::$APCU_LOCAL_STOCK); 35 if ($stockNum === false) { 36 $stockNum = self::initStock(); 37 } 38 self::output([‘stock_num‘ => $stockNum]); 39 } 40 /*抢购-减库存*/ 41 static function buy() 42 { 43 $localStockNum = apcu_fetch(self::$APCU_LOCAL_COUNT); 44 if ($localStockNum === false) { 45 $localStockNum = self::init(); 46 } 47 $localUse = apcu_inc(self::$APCU_LOCAL_USE);//本已卖 + 1 48 if ($localUse > $localStockNum) {//抢购失败 大部分流量在此被拦截 49 echo 1; 50 self::output([], -1, ‘该商品已售完‘); 51 } 52 //同步已售库存 + 1; 53 if (!self::incUseCount()) {//改失败,返回商品已售完 54 self::output([], -1, ‘该商品已售完‘); 55 } 56 //写入创建订单队列 57 self::conRedis()->lPush(self::$REDIS_REMOTE_QUEUE, json_encode([‘user_id‘ => self::$userId, ‘product_id‘ => self::$productId])); 58 //返回抢购成功 59 self::output([], 0, ‘抢购成功,请从订单中心查看订单‘); 60 } 61 /*创建订单*/ 62 /*查询订单*/ 63 /*总剩余库存同步本地,定时执行就可以*/ 64 static function sync() 65 { 66 $data = self::conRedis()->hMGet(self::$REDIS_REMOTE_HT_KEY, [self::$REDIS_REMOTE_TOTAL_COUNT, self::$REDIS_REMOTE_USE_COUNT]); 67 $num = $data[‘total_count‘] - $data["used_count"]; 68 apcu_add(self::$APCU_LOCAL_STOCK, $num); 69 self::output([], 0, ‘同步库存成功‘); 70 } 71 /*私有方法*/ 72 //库存同步 73 private static function incUseCount() 74 { 75 //需要查远端的总库存和已经售卖的计数 76 //同步远端库存时,需要经过lua脚本,保证不会出现超卖现象 77 //因为redis是单进程模型,可有效的避免两个用户同时进行查库存和扣库存 78 $script = <<<eof 79 local key = KEYS[1] 80 local field1 = KEYS[2] 81 local field2 = KEYS[3] 82 local field1_val = redis.call(‘hget‘, key, field1)//总库存 83 local field2_val = redis.call(‘hget‘, key, field2)//已经售卖的计数 84 if(field1_val>field2_val) then 85 return redis.call(‘HINCRBY‘, key, field2,1) 86 end 87 return 0 88 eof; 89 //eval()执行lua脚本的方法 90 return self::conRedis()->eval($script,[self::$REDIS_REMOTE_HT_KEY, self::$REDIS_REMOTE_TOTAL_COUNT, self::$REDIS_REMOTE_USE_COUNT] , 3); 91 } 92 /*初始化本地数据*/ 93 private static function init() 94 { 95 apcu_add(self::$APCU_LOCAL_COUNT, 150); 96 apcu_add(self::$APCU_LOCAL_USE, 0); 97 } 98 static function initStock(){ 99 $data = self::conRedis()->hMGet(self::$REDIS_REMOTE_HT_KEY, [self::$REDIS_REMOTE_TOTAL_COUNT, self::$REDIS_REMOTE_USE_COUNT]); 100 $num = $data[‘total_count‘]- $data["used_count"]; 101 apcu_add(self::$APCU_LOCAL_STOCK, $num); 102 return $num; 103 } 104 } 105 try{ 106 $act = $_GET[‘act‘]; 107 $product_id = $_GET[‘product_id‘]; 108 $user_id = $_GET[‘user_id‘]; 109 $obj = new Api($product_id, $user_id); 110 if (method_exists($obj, $act)) { 111 $obj::$act(); 112 die; 113 } 114 echo ‘method_error!‘; 115 } catch (\Exception $e) { 116 echo ‘exception_error!‘; 117 var_dump($e); 118 }

标签:theme 次数 商城 xtend tput bsp 概率 err 提示
原文地址:https://www.cnblogs.com/qiusanqi/p/11988445.html