标签:组合 进程 角色权限 poi 环境 pass 方法 ide ase
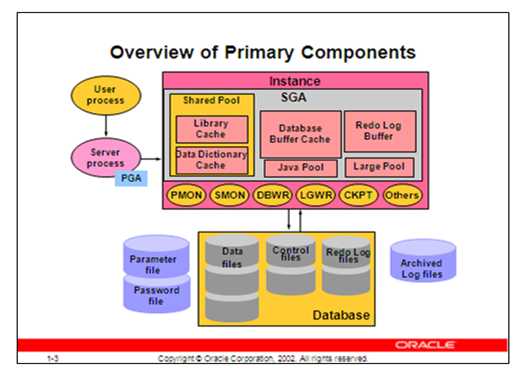
基本组成:
Oracle server:一般情况下是一个instance和一个database组成
一般:1个instance只能对应一个数据库。
特殊:1个数据库可以有多个instance(RAC)
一台服务器上同时可装多套版本的数据库软件,每个数据库软件可建多个数据库,但是每个数据库只对应一个instance,也可以理解成每个数据库只有一个SID 。
利用DBCA建出的每个库都是相对独立的,在同一服务器上如果创建多库必须将环境变量的参数文件做区分,并且在对实例切换时需如下操作:
connect 用户名/密码@实例的服务名
由内存区和后台进程组成
①内存区:数据库高速缓存、重做日志缓存、共享池、流池以及其它可选内存区(如Java池),这些池也称为数据库的内存结构
②后台进程:包括系统监控进程(SMON)、进程监控(PMON)、数据库写进程(DBWR)、日志写进程(LGWR)、检验点进程(CKPT)、其它进程(SMON,如归档进程、RECO进程等)
③注:要访问数据库必须先启动实例,实例启动时先分配内存区,然后再启动后台进程,后台进程执行库数据的输入、输出以及监控其它Oracle进程。在数据库启动过程中有五个进程是必须启动的,它们是系统监控进程(SMON)、进程监控(PMON)、数据库写进程(DBWR)、日志写进程(LGWR)、检验点进程(CKPT),否则实例无法创建。
Oracle服务器由数据库实例和数据文件组成,也就是我们常说的数据库管理系统。数据库服务器除了维护实例和数据库文件之外,还在用户建立与服务器的连接时启动服务器进程并分配PGA
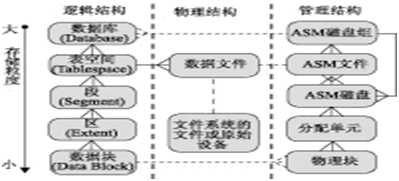
表空间:据库的基本逻辑结构,是一系列数据文件的集合;
段:不同类型数据在数据库中占用的空间,有许多区组合而成;
区:由连续的块组成,目的是为数据一次性预留一个较大的空间,oracle为存储空间进行分配回收都是以区为单位的;
块:最小的存储单位,在创建数据库时指定,不能修改。大小是操作系统块得整数倍。
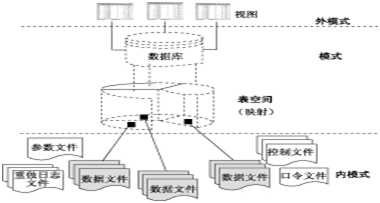
数据库中的实际数据
查看数据文件:
首先格式化一下:col file_name for a58;
select file_name,tablespace_name from dba_data_files;
维护数据库和验证数据库完整性
查看数据文件:
首先格式化一下:col name format a60;
select name from v$controlfile;
数据库发生变化的记录,用于数据恢复
查看数据文件:
select member from v$logfile;
参数文件定义了数据库实例的特性。在参数文件中包含为SGA中内存结构分配空间的参数
如分配数据库高速缓冲区的大小等,参数文件是正文文件,可以使用操作系统文本编辑器查看,如在Windows 操作系统中使用记事本工具。
查看参数文件:
首先格式化:
col name for a30;
col value for a30;
select name,value,ismodified from v$parameter;
密码文件授予用户启动和关闭数据库实例,在刚安装数据库时,Oracle 的默认用户名和密码就存储在密码文件中,Oracle 可以借此判断用户的操作权限。
归档日志文件是日志文件的脱机备份,在发生故障后进行数据恢复时可能使用该文件
用户进程与数据库服务器之间通信,一个连接可以有多个对话。三种连接:
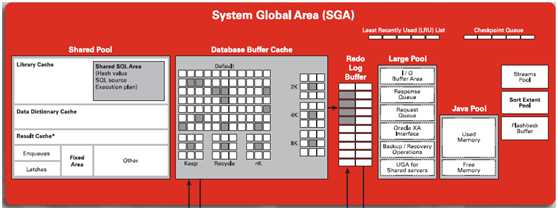
Oracle的内存结构由两部分组成:SGA与PGA
①PGA 称为程序全局区,程序全局区不是实例的一部分,当服务器进程启动时,才分配PGA。②SGA 称为系统全局区,它是数据库实例的一部分,当数据库实例启动时,会首先分配系统全局区。
在系统全局区中包含:数据库高速缓存(Database buffer cache)、重做日志缓存(Redo log buffer cache)、共享池(Shared pool)、大池(Large pool)和Java 池(Java pool)
Oracle 引入共享池的目的就是共享SQL 或PL/ SQL 代码,即把解析得到的SQL 代码的结果在这里缓存
共享池由两部分组成,即库高速缓存(Libray cache)和数据字典高速缓存(Data dict cache),①库高速缓存库高速缓存存储了最近使用过的SQL 和PL/ SQL 语句。
②数据字典高速缓存是与数据字典相关的一段缓冲区。在数据字典高速缓冲区中存储了数据文件、表、索引、列、用户、权限信息和其它一些数据库对象的定义。
SQL> alter system set shared_ pool_ size = 16M;
SQL> show parameter shared_ pool_ size;
存储了最近从数据文件读入的数据块信息或用户更改后需要写回数据库的数据信息,此时这些没有提交给数据库的更改后的数据称为脏数据。
当用户执行查询语句如select* from dept 时,如果用户查询的数据块在数据库高速缓存中,Oracle 就不必从磁盘读取,而是直接从数据库高速缓存中读取
SQL> show parameter db_ block_ size;
SQL> show parameter db_ cache_ size;
因为在Oracle 11g 中,SGA 为数据库服务器自动管理,所以该参数值为0
SQL> show sga;
SQL> alter system set db_ cache_ size = 200M;
SQL> show parameter db_ cache_ advice;
SQL> col id for 99 SQL> SELECT id, name, block_ size, size_ for_ estimate, buffers_ for_ estimate 2 from v$ db_ cache_ advice;
当用户执行了如INSERT、UPDATE、DELETE、CREATE、ALTER 或DROP 操作后,数据发生了变化,这些变化了的数据在写入数据库高速缓存之前会先写入重做日志缓冲区,同时变化之前的数据也放入重做日志高速缓存,这样在数据恢复时Oracle 就知道哪些需要前滚哪些需要后滚了。
SQL> show parameter log_ buffer;
重做日志缓存区参数log_ buffer 是静态参数,不能动态修改
大池是SGA 的一段可选内存区,只在共享服务器环境中配置大池。
在共享服务器环境下,Oracle 在共享池中分配额外的空间用于存储用户进程和服务器进程之间的会话信息,但是用户进程区域UGA(可理解为PGA 在共享服务器中的另一个称呼)的大部分将在大池中分配,这样就减轻了共享池的负担
SQL> show parameter large_ pool_ size
SQL> alter system set large_ pool_ size = 48M
Java 池也是可选的一段内存区,但是在安装完Java 或者使用Java 程序时则必须设置Java 池,它用于编译Java 语言编写的指令。
SQL> show parameter java_ pool_ size;
值为0 说明在Oracle 11g 中,Java 池大小由数据库服务器在SGA 中自动分配,当然用户也可以使用alter system 指令修改该参数的值
SQL> alter system set java_ pool_ size = 48M
流池也称为流内存,它是Oracle 流专用的内存池,流(stream)是Oracle 数据库中的一个数据共享,其大小可以通过参数stream_ pool_ size 动态调整。
PGA(进程全局区)
PGA 中存储了服务器进程或单独的后台进程的数据信息和控制信息。它随着服务器进程的创建而被分配内存,随着进程的终止而释放内存。PGA 与SGA 不同,它不是一个共享区域,而是服务器进程专有的区域。在专有服务器(与共享服务器相对的概念)配置中包括如下的组件:排序区、会话信息、游标状态、堆栈区
UGA(用户全局区)
在共享服务器模式下有一个重要的概念即UGA,它是用户的会话状态,这部分内存会话总可以访问,UGA 存储在每个共享服务器都可以访问的SGA 中,这样任何服务器都可以使用用户会话的数据和其它信息。而在专有服务器模式下,用户会话状态不需要共享,用户进程与服务器进程是一一对应的关系,所以UGA 总是在PGA 中进行分配。
从Oracle 9i 开始,Oracle 提高了两种办法管理PGA,即手动PGA 管理和自动PGA 管理。采用手动管理时,必须告诉Oracle 一个特定的进程需要的排序区,允许使用多少内存,而在自动PGA 管理中,则要求高速Oracle 在系统范围内可以为PGA 中的特定功能如排序区分配多少内存。
①查询PGA 中排序区的大小
SQL> show parameter sort_ area_ size;
服务器进程和用户进程,是用户使用数据库连接工具同数据库服务器建立连接时,涉及的两个概念。
服务器进程犹如一个中介,完成用户的各种数据服务请求,而把数据库服务器返回的数据和结果发给用户端。
在专有连接中,一个服务器进程对应一个用户进程,二者是一一对应的关系。
在共享连接中,一个服务器进程对应几个用户进程,此时服务器进程通过OPI(Oracle Program Interface)与数据库服务器通信。
当用户使用数据库工具如SQL* Plus
与数据库服务器建立连接时,就启动了一个用户进程,即SQL* Plus 软件进程
使用SCOTT 用户连接数据库:SQL> conn scott/tiger
用户和数据库服务器建立了连接,数据库服务器产生一个服务器进程,负责与数据库服务器的直接交互
后台进程是在实例启动时,在数据库服务器端启动的管理程序,它使数据库的内存结构和数据库物理结构之间协调工作。它们是DBWR、LGWR、PMON、SMON 和CKPT
系统监控进程的主要作用就是数据库实例恢复。当数据库发生故障时,如操作系统重启,此时实例SGA 中的所有没有写到磁盘的信息都将丢失。当数据库重新启动后,系统监控进程自动恢复实例。
进程监控负责服务器进程的管理和维护工作,在进程失败或连接异常发生时该进程负责一些清理工作。
在介绍高速缓冲区时,提到了脏数据的概念,脏数据就是用户更改了的但没有提交的数据库中的数据,因为在数据库的数据文件与数据库高速缓存中的数据不一致,故称为脏数据,这种脏数据必须在特定的条件下写到数据文件中,这就是数据库写进程的作用。
数据库写进程负责把数据库高速缓冲区中的脏数据写到数据文件中。或许读者会问,为什么不立即提交脏数据呢,这样就不需要复杂的数据库写进程来管理。其实,Oracle 这样设计的思路很简单,就是减少I/ O 次数,但脏数据量达到一定程度或者某种其它条件满足时,就提交一次脏数据。因为磁盘的输入、输出会花费系统时间,使得Oracle 系统的效率不高。4.3.4重做日志写进程(LGWR)
重做日志写进程负责将重做日志缓冲区中的数据写到重做日志文件。此时重做日志缓冲区中的内容是恢复事务所需要的信息,比如用户使用UPDATE 语句更新了某行数据,恢复事务所需的信息就是更新前的数据和更新后的数据,这些信息用于该事务的恢复
归档日志进程是可选进程,该进程并不在实例启动时自动启动。它的作用是把写满的重做日志文件的数据写到一个归档日志中,这个归档日志用作介质故障时的数据库恢复
查看系统的归档模式
SQL> con system/ oracle@ orcl as sysdba;
SQL> archive log list;
设置数据库为归档模式的过程
SQL> shutdown immediate
SQL> conn /as sysdba;
SQL> startup mount;
SQL> alter database archivelog;
SQL> alter database open;
查询当前数据库的归档模式
SQL> archive log list;
查看数据库恢复目录的位置
SQL> show parameter db_ recovery
首先介绍检验点,检验点是一个事件,当数据库写进程把SGA 中所有被修改了的数据库高速缓冲中的数据写到数据文件上时产生,这些被修改的数据包括提交的和未提交的数据。由于引入了校验点,使得所有的校验点的所有变化了的数据都写到数据文件中,在实例恢复时,就不必恢复校验点之前的重做日志中的数据,加快了系统恢复的效率。校验点进程并不是用于建立校验点,只是在校验点发生时,会触发这个进程进行一系列工作
强制执行校验点SQL> alter system checkpoint;
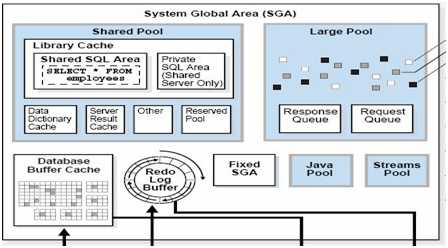
①SGA 为数据库实例的一部分,在数据库启动时会首先分配这块内存,包括数据库高速缓存、共享池、大池、流池、Java 池以及Redo Buffer。
②PGA 也可以成为私有全局区,是某个用户进程所独有的。在专有连接模式下,每个用户会话都会分配一个PGA,用户保存会话信息。当然在PGA 与SGA 之间是服务器进程,最终是服务器进程访问SGA 来满足用户的数据访问。
③数据库实例启动时,Oracle 数据库会分配内存区并启动后台进程。
内存区存储了如下的信息:
程序代码。
建立过连接的会话信息。(即使该会话当前不是活跃的inactive。)
程序执行期间所需信息,如SQL 查询的当前状态。
在进程间共享并且进行通信的信息如锁数据。
缓存数据,如数据库块、重做块。(缓存这些在磁盘上的数据。)
④Oracle 数据库基本的内存结构包括
SGA系统全局区:SGA 是一组共享的内存结构。这些组件包含数据库实例所需的数据和控制信息。它是一个共享的内存结构,所有服务器进程和后台进程共享。
PGA 程序全局区:是非共享的内存区域,包含Oracle 进程所独自使用的数据和控制信息。PGA 与服务器进程和后台进程共存,即PGA 是为服务器进程和后台进程服务的内存区,为这些进程独有,不是所有进程共享的内存区,所以这部分不会出现争用。数据库初始化参数设置实例PGA 的大小,这个大小为整个实例所拥有。
UGA 用户全局区:该内存区域和一个用户会话相关联。
软件代码区:该内存区用于存储正在运行的程序代码。
PGA 内存是专为某个操作系统进程或者线程服务的,不能被其他进程或者线程共享使用。正因为PGA 是进程专有的内存区域,所以从来不会在SGA 中分配。PGA 是一个内存堆,存储了专有或者共享服务器进程所需的会话相关变量。服务器进程负责在PGA 中分配它所需要的内存结构
①SGA 是可读写的内存区。SGA 和后台进程组成了Oracle 数据库实例,代替用户工作的服务器进程可以读SGA 中的数据。服务器和后台进程并不驻留在SGA 中,而是存在于独立的内存空间中。每一个数据库都有自己的SGA。Oracle 数据库在实例启动时自动分配SGA,在实例关闭时自动关闭SGA。
②SGA 由几个内存组件组成,称为内存池。这些内存池的空间分配以Granules 为单位,即粒度为单位,粒度是一个连续的内存空间,粒度大小与操作系统平台有关,由整个SGA 的大小决定。下面是最重要的几个SGA 组件。
Database Buffer Cache:数据库高速缓存
Redo Log Buffer:重做日志缓存
Shared Pool:共享池
Large Pool:大池
Java Pool:Java 池
Streams Pool:流池
③Fixed SGA:固有区域数据库高速缓存,是一个共享的内存结构,这意味着发生内存争用的事件都发生共享的内存结构中。数据库高速缓存用来存储从数据文件读取的数据块,临时存储当前或者最近读取的数据块。提高Oracle 数据库读写数据的效率。
UGA 是会话内存,为某个用户会话服务,给会话分配内存存储会话变量,这些变量包括登录信息以及会话所需的其他信息。本质来讲UGA 存储了用户的会话状态。图8- 4 是UGA 组成图。
在共享服务器模式下,UGA 在SGA 中分配,这样任何的共享服务器进程都可以访问它。如果在PGA 中分配,由于PGA 只为单个进程服务,不能共享。当使用专有服务器模式时,UGA 在PGA 中分配。
MEMORY_ TARGET 设置后,SGA 和PGA 实现自动调整,根据负载状况协调内存的使用,这个参数是动态参数,所以不需要重启数据库就可以设置,如下所示。
SQL> alter system set memory_ target= 1000M SCOPE= BOTH;
MEMORY_ MAX_ TARGET 设置MEMORY_ TARGET 的上限,毕竟操作系统的内存不仅仅为Oracle 服务,这样就防止设置了MEMORY_ TARGET 过大的值,而使得操作系统的内存资源短缺。如果使用DBCA 建库,此时数据库默认启动自动内存管理。
如果没有启动自动内存管理,比如使用DBCA 建库时设置了SGA 和PGA 相关参数值,或者使用CREATE DATABASE 手工建库时没有设置MEMORY_ TARGET 参数,此时就需要启动自动内存管理特性。
使用AS SYSDBA 角色登录数据库,设置MEMORY_ TARGET 的值,这个值通过SGA_ TAGET+ PGA_ AGGREGATE_ TARGET 计算。
memory_ target = sga_ target + max( pga_ aggregate_ target, maximum PGA allocated)
其中sga_ target 和pga_ aggregate_ target 可以通过SHOW PARAMETER TARGET 获得,而maximum PGA Allocated 通过select value from v$ pgastat where name=‘ maximum PGA allocated‘;查询获得。一般比这个计算值还要大些,如果物理内存够的话。
MEMORY_ MAX_ TARGET 考虑SGA 和PGA 的将来预期,默认该参数与MEMORY_ TARGET 相同。它是一个静态参数,需要如下修改。
ALTER SYSTEM SET MEMORY_ MAX_ TARGET = nM SCOPE = SPFILE;
如果使用PFILE 启动数据库,也可以在初始化参数文件中写入这些参数的值。
memory max target = nM memory_ target = mM
通过动态性能视图$ memory_ target_ advice 查看对于MEMORY_ SIZE 的大小设置建议。其中内存尺寸因子MEMORY_ SIZE_ FACTOR 为1 的MEMORY_ SIZE 为当前的内存大小,也就是参数memory_ target 的大小。
查看对于MEMORY_ SIZE 的大小设置建议:
SQL> select * from v$ memory target advice order by memory size;
查询MEMORY_ TARGET 的大小
SQL> show parameter memory target;
查询PGA 和SGA 的大小
SQL> show parameter sga;
SQL> show parameter pga
从输出知道,PGA 和SGA 的值为0,说明这两个内存组件是自动调整的。在EM 企业管理器中,可以使用图像化的内存顾问查看对于MEMORY_ SIZE 设置尺寸的建议。
在使用DBCA 建库时,选择Custom 即可实现共享内存自动管理,需要配置PGA 和SGA 的大小,SGA 的内存组件是自动调整,同样PGA 的内存组件也是自动调整
对于SGA,只要设置TARGET 值和MAXIMUM 值即可实现SGA 内相关内存自动调整,当然SGA 的其他自动调整的内存参数也可以通过手工设置。
SGA 包括共享池、大池、Java 池、数据库调整缓存、流池。
内存组件与相应参数:
共享池 SHARED_ POOL_ SIZE
大池LARGE_ POOL_ SIZE
Java 池JAVA_ POOL_ SIZE
数据库高速缓存 DB_ CACHE_ SIZE
流池 STREAMS_ POOL_ SIZE
在自动PGA 内存调整状态下PGA 相关组件的大小信息。
查询PGA 相关组件的大小
SQL> show parameter area_ size;
从这个输出知道参数bitmap_ merge_ area_ size、create_ bitmap_ area_ size、hash_ area_ size 以及sort_ area_ size 是自动调整的参数。
workarea_ size_ policy,这个参数是决定自动调整PGA 还是手工调整PGA,如果手工调整PGA 则必须设置参数workarea_ size_ policy 为manual
Smart flash cache 是Oracle 在11g 版本中提供的新功能,是一个新的内存组件,默认这个内存组件没有配置。也就是没有启用。它的核心作用是缓存更多的数据,提高读数据的效率,减少CPU 的负担以及减小数据库高速缓存的压力。
启用smart flash cache 功能后,从数据库高速缓存移动到flash cache 中的数据块而言,将有部分数据块的元数据存储在数据库高速缓存中。对于单实例数据库而言,每个数据块的元数据占据大约100B 的空间。而对于RAC 环境则大约是200B,所以在设置smart flash cache 时需要考虑数据库高速缓存的额外空间需求。
如果是手工调整内存方式,则需要增加数据库高速缓存的大小,其值为进入smart flash cache 的数据块数量乘以100。如果采用自动内存调整则需要调整MEMORY_ TARGET,大小参考手工调整内存的大小。如果使用自动共享内存调整,即SGA 组件自动调整,此时需要增加SGA_ TARGET 的值。
设置smart flash cache 时需要设置两个参数,其中一个参数需要指定存储smart flash cache 数据块的磁盘目录以及名称,要求必须在Flash 盘上存储smart cache 数据,否则会影响性能。涉及的两个参数是db_ flash_ cache_ file 和db_ flash_ cache_ size,
查询SmartFlash Cache 涉及的两个参数
SQL> show parameter flash_ cache;
修改这两个参数以启动smart flash cache 功能。
设置db_ flash_ cache_ file 和db_ flash_ cache_ size 参数
SQL> alter system set db_ flash_ cache_ file=‘/ u01/ flash_ cache‘ scope= spfile;
SQL> alter system set db_ flash_ cache_ size= 1g scope= spfile;
这两个参数都不是动态参数,修改后需要重启数据库才能生效。我们重启数据库后验证修改结果。
重启数据库使参数修改生效
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup
ORA- 00439: feature not enabled:
Server Flash Cache
我们看到此时的提示为该特性没有启动。其实,这个也在预想之中,因为我们的操作系统不是启动该特性要求的系统,显然不会得到支持。如果在Solaris 或者Oracle Enterprise Linux 系统上将得到支持,但是设置方法是一样的。
要创建数据库必须使用DBA 权限的用户,使用SYS 用户登录数据库
sys/ Oracle1234 as sysdba
创建数据库用户
SQL> create user jane identified by american default tablespace users temporary tablespace temp quota 10m on users password expire;
创建了用户JANE:
create user jane:创建用户JANE,其中create user 为创建用户指令。
identified by american:设置用户密码为american,其中identified by 为创建用户指令。
default tablespace users:设置默认表空间为USERS 表空间,该表空间存储用户数据。● temporary tablespace temp:创建临时表空间TEMP,该表空间用户诸如排序等操作的数据空间。
quota 10m on users:设置该用户对于表空间USERS 的配额为10M。
password expire:说明用户JANE 登录数据库时,密码立即失效,Oracle 会提示重新输入密码,如下所示。
SQL> connect jane/ american
为用户JANE 赋予CREATE SESSION 权限
SQL> connect sys/ Oracle1234 as sysdba
SQL> grant create session ,resource to jane;
然后就可以用新密码登录数据库了,如下所示。
SQL> connect jane/ oracle
在成功创建了数据库后使用数据字典DBA_ USERS 查看用户JANE 的信息
SQL> col username for a10
SQL> col default_ tablespace for a10
SQL> col temporary_ tablespace for a15
SQL> col password for a20
SQL> select username, password, expiry_date, default_tablespace, temporary_tablespace, created from dba_ users where username = ‘JANE‘
从输出可以看出用户的默认表空间为USERS,而临时表空间为TEMP,该用户的创建时间为01- JAN- 13。而密码是加密的,这也是Oracle 认为安全第一的缘故,即使具有DBA 权限的用户也无法看到该用户的密码,虽然DBA 用户可以创建或删除用户
查看用户JANE 的表空间配额信息
SQL> select tablespace_name, username, max_bytes from dba_ts_quotas where username =‘JANE‘;
创建用户的语法格式
CREATE USER user IDENTIFIED {BY password | EXTERNALLY} [DEFAULT TABLESPACE tablespace] [TEMPORARY TABLESPACE tablespace] [QUOTA {integer [K | M]| UNLIMITED} ON tablespace [QUOTA {integer [K | M]| UNLIMITED} ON tablespace ]……] [PASSWORD EXPIRE] [ACCOUNT { LOCK | UNLOCK }] [PROFILE { profile | DEFAULT }]
下面介绍其中的几个参数:
CREATE USER user:创建用户user。
IDENTIFIED{ BY password | EXTERNALLY}:设置用户密码,EXTERNALLY 说明该用户由操作系统授权。该参数在创建用户时是不能省略的。
DEFAULT TABLESPACE tablespace:设置用户的默认表空间。
TEMPORARY TABLESPACE tablespace:设置用户的临时表空间。
QUOTA {integer[ K| M]| UNLIMITED} ON tablespace:设置该用户对于表空间的配额,即表空间的多大空间给该用户使用,参数UNLIMITED 说明没有限制,K| M 是配额单位。● PASSWORD EXPIRE:设置用户密码在用户第一次使用时作废,需要重新设置该用户密码。
ACCOUNT{ LOCK | UNLOCK}:选择是否锁定该用户,LOCK 锁定用户,而UNLOCK 不锁定用户,该参数的默认值是UNLOCK。
PROFILE {profile | DEFAULT}:使用指定的概要文件,profile 为概要文件名。如果不指定概要文件,则使用DEFAULT 的默认概要文件,默认的概要文件对所有限制的初始值都没有限制。
从以上创建用户的语法可以看出,在创建新用户前,必须做些准备工作,整个准备工作和创建过程如下所示。
确认存储用户对象的表空间。
确定在每个表空间上的空间配额。
分配一个默认表空间和一个临时表空间。
开始创建用户。
向用户授权和角色。如使得用户具有建立会话的权利,辅以用户DBA 角色权限等。
在成功创建用户后,如果对用户参数如默认表空间等不满意,可以改变用户参数
修改用户JANE 的默认表空间配额
SQL> connect system/oracle
SQL> alter user jane quota 20m on users;
在修改成功后,我们使用数据字典DBA_ TS_ QUOTAS 来验证修改结果。
验证用户JANE 的表空间修改结果
SQL> select tablespace_name, username, max_bytes from dba_ts_quotas where username =‘ JANE‘;
从输出结果可以看出用户JANE 在表空间USERS 上的配额被修改为20M。说明修改成功。
修改用户JANE 的默认表空间
SQL> alter user jane default tablespace newtbs quota unlimited on system;
我们增加了用户JANE 的一个默认表空间为NEWTBS,在该表空间的配额为UNLIMITED(没有限制)。我们再通过数据字典DBA_TS_QUOTAS 来查看修改结果。
查看用户JANE 的默认表空间修改信息
SQL> select username, tablespace_name, max_bytes from dba_ts_quotas where username =‘ JANE‘;
输出可以看出用户JANE 在表空间NEWTBS 上的配额为- 1,说明没有限制,而此时用户在表空间USERS 上的配额依然存在。而如果不希望用户使用表空间USERS 的空间,即回收用户在USERS 表空间的使用权,又如何处理呢
回收用户JANE 在表空间USERS 的使用权
SQL> alter user jane quota 0 on users;
此时,我们使用设置用户在表空间USERS 上的配额为0 来回收对其使用权。然后我们再通过数据字典DBA_ TS_ QUOTAS 来查看该用户的表空间配额信息
验证是否回收用户JANE 的表空间USERS 的使用权
SQL> select username, tablespace_ name, max_ bytes from dba_ ts_ quotas where username =‘ JANE‘;
从输出可以看出用户JANE 没有使用表空间USERS,只有表空间NEWTBS,而且该表空间的使用空间不受限制,如果在回收USERS 表空间的使用权之前,已经在该表空间上使用了5M 空间,则不能再给用户JANE 分配使用空间了。
SQL> drop user jane;
验证是否成功删除用户JANE
SQL> select username, created, default_tablespace from dba_users where username =‘ JANE‘;
输出结果是“未选定行”,说明用户JANE 不存在,
在删除用户时,如果该用户已经连接到数据库服务器,则无法删除。可以断开该用户的连接在删除用户。我们也可以使用数据字典DBA_ USERS 来查看当前系统上的用户名
查看当前系统上的所有用户信息
SQL> select username, account_status, created from dba_users;
在以上输出中ACCOUNT_ STATUS 说明用户的状态,其中值OPEN 说明该用户可用,而EXPIRED 说明该用户过期,LOCKED 说明该用户锁定。那么如何解锁这些锁定的用户呢,
解锁用户
SQL> ALTER USER outln IDENTIFIED BY outln ACCOUNT UNLOCK;
解锁过程中,我们需要先使用IDENTIFIED BY 修改用户的密码
使用解锁的用户登录数据库
SQL> connect outln/outln
SQL> show user USER 为" OUTLN"
在创建了用户后,需要赋予该用户权限使得它可以创建数据库对象如表、索引、触发器等,而此时会涉及模式的概念。
模式与用户对应,当一个用户创建成功时,也对应地创建了一个模式。而且二者是一对一的关系,名字相同。模式是命名的数据库对象的集合,这些数据库对象包括表、视图、索引等。
用户拥有数据库的模式,而且用户名和模式经常互换使用。
模式对象:表、触发器、约束、索引、视图、序列号、存储过程、同义词、用户定义的数据类型、函数、软件包。
我们可以使用SCOTT 用户登录数据库,然后使用数据字典USER_ OBJECTS 来查看当前用户所拥有的数据库模式对象
查看用户SCOTT 所拥有的模式对象
SQL> select distinct (object_ type) from user_ objects;
从输出可以看出SCOTT 用户或称SCOTT 模式拥有2 个模式对象,分别是表(TABLE)和索引(INDEX)。
在创建用户后就需要给该用户各种系统资源,如CPU、并行会话数、空闲时间限制等资源限制,同时需要对口令做出更详细的管理方案,如尝试登录指定的次数后账户被锁定、口令过期之后的处理等,如果对每个用户都进行资源限制或口令管理,要输入大量的指令,比如每个用户输入10 条资源限制或口令限制指令,对10 个用户就输入100 条指令,显然这样的效率很低,尤其是对用户的资源限制和口令限制都相同时,只是重复的输入指令,Oralce 提供了概要文件来管理用户,可以避免上述问题。
概要文件就是一组指令的集合,这些指令限制了用户资源的使用或口令的管理,在创建用户时,有一个PROFILE 参数就是用来指定概要文件的,一旦概要文件创建就可以将概要文件通过ALTER USER 指令赋予用户或者在CREATE USER 时指定概要文件。通过将概要文件赋予用户可以极大较少DBA 的工作量。如果没有指定概要文件,则会自动使用一个默认概要文件。
使用概要文件可以实现用户的资源管理和口令管理。使用步骤如下所示。
● 使用CREATE PROFILE 指令创建一个概要文件。
● 使用ALTER USER(已有用户)或CREATE USER(新用户)将概要文件赋予用户。
● 对于资源管理而言,启动资源限制,修改动态参数RESOURCE_ LIMIT 为TRUE,此时既可以通过修改参数文件也可以使用ALTER SYSTEM 来修改。
当用户连接到数据库时,就与数据库服务器建立了会话连接,此时用户会消耗数据库服务器的资源,所以我们创建一个会话级的数据库资源限制的概要文件来限制用户对资源的使用。
我们先给出创建资源管理的概要文件的语法格式,如下所示。
CREATE PROFILE profile_ name LIMIT [SESSIONS_ PER_ USER n] [CPU_ PER_ SESSION n] [CPU_ PER_ CALL n] [CONNECT_ TIME n] [IDLE_ TIME n] [LOGICAL_ READS_ PER_ SESSION n] [LOGICAL_ READS_ PER_ CALL n]
其中n 为最大值。
SESSIONS_ PER_ USER n:表示每个用户的最大会话数。
CPU_ PER_ SESSION n:每个会话占用的CPU 时间,单位是0. 01 秒。
CPU_ PER_ CALL n:每个调用占用的CPU 时间,单位是0. 01 秒。
CONNECT_ TIME n:每个连接支持连接的时间。
IDLE_ TIME n:每个会话的空闲时间。
LOGICAL_ READS_ PER_ SESSION n:每个会话的物理和逻辑读数据块数。
创建资源限制概要文件
SQL> create profile scott_ prof limit sessions_ per_ user 10 cpu_ per_ session 10000 idle_ time 40 connect_ time 120;
创建了一个名为SCOTT_ PROF 的概要文件,加在该文件上的限制是sessions_ per_ user 每个用户的并行会话数为10,cpu_ per_ session 每个会话的CPU 时间为1000 秒。idle_ time 连接空闲时间为40 分,connect_ time 保持连接时间为120 分。
通过数据字典DBA_ PROFILES查看概要文件SCOTT_ PROF
SQL> col profile for a20
SQL> col resource_ name for a25
SQL> col limit for a20
SQL> select * from dba_ profiles where profile =‘ SCOTT_ PROF‘ order by limit;
从输出可以看出概要文件SCOTT_ PROF 的所有资源参数,其中资源参数SESSION_ PER_ USER、CPU_ PER_ SESSION、CONNECT_ TIME、IDLE_ TIME 为创建概要文件时指定的值,而其他资源参数都采用默认值。其中RESOURCE 列的值中KERNEL 行表示一个资源参数,而PASSWORD 表示一个安全限制,接下来我们介绍如何创建口令管理的概要文件。
创建口令管理的概要文件与创建资源限制的概要文件一样,都是使用CREATE USER 或者ALTER USER 指令将概要文件赋予用户,口令文件一旦赋予用户立即生效,不需要开启设置。
下面介绍完成口令管理的参数以及含义。首先,查看概要文件SCOTT_ PROF 中的口令参数,使用数据字典DBA_ PROFILES 查看概要文件SCOTT_ PROF的口令管理参数
SQL> col resource_ name for a30
SQL> select * from dba_ profiles where profile=‘ SCOTT_ PROF‘ * and resource_ type=‘ PASSWORD‘
从输出发现有7 个参数实现用户的口令管理,如下所示。
FAILED_ LOGIN_ ATTEMPTS:尝试失败登录的次数,如果用户登录数据库时登录失败次数超过该参数的值则锁定该用户。
PASSWORD_ LIFE_ TIME:口令有效的时限,超过该参数指定的天数则口令失效。
PASSWORD_ REUSE_ TIME:口令在能够重用之前的天数。
PASSWORD_ REUSE_ MAX:口令能够重用之前的最大变化数。
PASSWORD_ VERIFY_ FUNCTION:在为一个新用户赋予口令之前要验证口令的复杂性是否满足要求的一个函数,该函数使用PL/ SQL 语言编写,名字为verify_ function。
PASSWORD_ LOCK_ TIME:当用户登录失败后,用户被锁定的天数。
PASSWORD_ GRACE_ TIME:口令过期之后还可以继续使用的天数。
口令的最小长度要求4 个字符。
口令不能与用户名相同。
口令应至少包含一个字符、一个数字和一个特殊字符
新口令至少有3 个字母与旧口令不同。
要使用Oracle 提供的口令验证函数,需要先运行一个名为utlpwdmg. sql 的脚本文件,执行脚本文件创建口令复杂性验证函数时,需要使用SYS 用户登录数据库且作为DBA 用户,该文件在$ ORACLE_ HOME\ RDBMS\ ADMIN 目录下(根据安装的磁盘略有不同)。
执行创建口令复杂性验证函数的过程
SQL> connect system/ oracle as sysdba
SQL> @ F:\ app\ oracle\ product\ 11. 2. 0\ dbhome_ 1\ RDBMS\ ADMIN\ utlpwdmg. Sql
从输出可以看出,函数已经创建,且配置文件已经更改,这里创建了函数VERIFY_ FUNCTION。
验证口令验证函数VERIFY_ FUNCTION 是否创建
SQL> col owner for a10
SQL> col object_ name for a20
SQL> select owner ,object_ name, object_ type, created from dba_ objects where object_ type =‘ FUNCTION‘ * and object_ name =‘ VERIFY_ FUNCTION‘
显然,函数VERIFY_ FUNCTION 存在说明创建成功,这意味着整个数据库系统的用户都使用在ALTER PROFILE DEFAULT LIMIT 中设置的口令限制,除非用户创建了另一个口令管理的概要文件,或修改了概要文件参数值。
更改用户SCOTT 的用户密码为oracle,看是否成功修改
SQL> conn system/oracle as sysdba
SQL> alter user scott identified by oracle ; alter user scott * 第1 行出现错误:ORA- 29003: 指定口令的口令验证失败ORA- 20002: Password too simple
显然,修改失败,因为密码oracle 不符合函数VERIFY_ FUNCTION 中定义的规则之一。此时也说明口令管理的概要文件即时生效。
在介绍了口令管理的参数以及含义后,我们就可以根据业务需要创建口令管理概要文件。
语法格式:
CREATE PROFILE profile_ name LIMIT [parameter1 para_ value1] [parameter2 para_ value2] ...
创建口令管理的概要文件
SQL> create profile password_ prof limit failed_ login_ attempts 5 password_ life_ time 90 password_ reuse_ time 30 password_ lock_ time 15 password_ grace_ time 3;
上面创建了概要文件password_ prof,各个参数的含义如下所示。
failed_ login_ attempts 5:尝试登录的失败次数为5 次,5 次之后该用户将被锁定。
password_ life_ time 90:该密码在90 天内有效。
password_ reuse_ time 30:该口令失效后30 天后才可以使用。
password_ lock_ time 15:在尝试登录指定的次数后,该用户被锁定15 天。
password_ grace_ time 3:在口令过期后,4 天内可以使用旧口令(过期的口令)登录数据库。
现在读者已经明白创建的密码概要文件的作用,通过数据字典DBA_ PROFILES 查看密码概要文件PASSWORD_ PROF 的口令参数
SQL> col resource_ type for a10
SQL> col limit for a15
SQL> select * from dba_ profiles where profile =‘ PASSWORD_ PROF‘ * and resource_ type =‘ PASSWORD‘
从输出可以看出在创建密码概要文件时,没有明确给出数值的都采用默认值,这些参数LIMIT 列的值为DEFAULT。
Oracle 允许使用ALTER PROFILE 指令来修改概要文件中的参数,我们修改概要文件PASSWORD_ PROF 的口令管理参数。
修改口令管理概要文件的参数
SQL> alter profile password_ prof limit failed_ login_ attempts 3 password_ life_ time 60 password_ grace_ time 7;
输出显示成功修改口令管理的配置文件,下面我们使用数据字典DBA_ PROFILES 来验证修改结果
查看修改后的口令管理概要文件PASSWORD_ PROF 的参数
SQL> select * from dba_ profiles where profile=‘ PASSWORD_ PROF‘ and resource_ type =‘ PASSWORD‘;
输出中参数被修改成功。如果不需要某个概要文件,可以使用指令DROP PROFILE 删除,如果要删除的概要文件已经赋予了用户则需要使用CASCADE 参数。
删除概要文件PASSWORD_ PROF
SQL> drop profile password_ prof;
验证是否删除概要文件PASSWORD_ PROF
SQL> select * from dba_ profiles where profile =‘ PASSWORD_ PROF‘;
未选定行“未选定行”说明成功删除了概要文件PASSWORD_ PROF,因为在数据字典DBA_ PROFILES 中没有该文件记录。
控制文件是一个非常小的二进制文件,记录了数据库的状态信息,如重做日志文件与数据文件的名字和位置、归档重做日志的历史等,它的大小不会超过64MB,但是归档日志的历史记录会让该文件逐渐变大。
控制文件在数据库启动的MOUNT 阶段被读取,控制文件和数据库是一对一的关系,因为控制文件的重要性,所以需要将控制文件放在不同磁盘上,以防止控制文件的失效造成数据库无法启动,控制文件的大小在CREATE DATABASE 语句中被初始化。
在数据库启动时,会首先使用默认的规则找到并打开参数文件,在参数文件中保存了控制文件的位置信息,通过参数文件Oracle 可以找到控制文件的位置,打开控制文件,然后会通过控制文件中记录的各种数据库文件的位置打开数据库,从而启动数据库到可用状态。
当成功启动数据库后,在数据库的运行过程中,数据库服务器可以不断地修改控制文件中的内容,所以在数据库被打开的阶段,控制文件必须是可读写的。但是其他任何用户都无法修改控制文件,只有数据库服务器可以修改控制文件中的信息。
控制文件是数据库启动时非常重要的一个文件,通常一个数据库需要至少3 个控制文件,而且这些控制文件最好不要放在同一个磁盘上,这样可以防止磁盘故障造成数据库无法启动。
在数据库启动和控制文件关系中,控制文件的位置通过参数文件获得,显然我们可以打开参数文件获得控制文件的位置。但是这种方式不方便而且不安全,如果用户不小心输入了某个字符,会造成控制文件错误。
Oralce 提供了视图v$ parameter 来查看控制文件的位置
SQL> SELECT value FROM v$ parameter where name = ‘control_ files‘;
使用show parameter 查看当前控制文件的位置
SQL> show parameter control_ files;
使用该方式查看控制文件的位置时,默认输出3 列,分别是参数名NAME、参数类型TYPE 和参数值VALUE。
通过数据字典v$ controlfile 查看控制文件的名字和存储目录
SQL> col name for a50 ;
SQL> select status , name from v$controlfile;
在v$ parameter 视图中记录控制文件名字和目录的列名为VALUE,而在v$ controlfile 视图中记录控制文件名字和目录的列名为NAME。
控制文件的内容控制文件是二进制文件,是无法通过文本编辑器查看的,而且该文件由Oracle 数据库服务器自动维护,DBA 无法干预。我们可以通过Oralce 的文档得知控制文件中的内容,以及使用v$ controlfile_ record_ section 视图查看所有的记录信息。
控制文件中所存的内容在相关文档中,说明了控制文件中存放了如下的信息。
● 数据库名:在初始化参数DB_ NAME 中获得,或是CREATE DATABASE 语句执行时使用的名字。
● 数据库标识符:数据库创建时Oralce 记录的标识符。
● 数据库创建时间:创建数据库时由Oracle 自动记录。
● 表空间信息:当表增加或删除表空间时记录该信息。
● 重做日志文件历史:在日志切换时记录。
● 归档日志文件的位置和状态信息:在归档进程发生时完成。
● 备份的状态信息和位置:由恢复管理器记录。
● 当前日志序列号:日志切换时记录。
● 检验点信息:当检验点事件发生时记录。
查询控制文件中所存储的内容,此时使用动态数据字典视图v$ controlfile_ record_ section。
SQL> SELECT type, record_ size, records_ total, records_ used FROM v$ controlfile_ record_ section;
从上述输出可以看出控制文件中存放了创建数据库的信息、重做日志信息、数据文件以及归档日志文件记录等信息。控制文件中记录了大量很有价值的信息用于数据库维护和管理,很多动态数据字典视图就是从控制文件中获得数据的,这些数据字典视图如下所示。
v$ backup 、v$ database、v$ tempfile、v$ tablespace、v$ archive 、v$ log、v$ logfile、 v$ loghist 、v$ archived_ log、v$ database
下面我们说明从控制文件中获得相关数据的视图的用处,如v$ database 视图就是从控制文件中获得基础数据,通过该视图可以查看数据库ID、创建时间和数据库是否处于归档模式等。
SQL> col name for a20
SQL> select name, created, log_ mode from v$ database;
虽然我们不能从控制文件中直接读取关于数据库创建的信息,但是可以间接地通过数据字典视图v$ database 来查看。上面的输出显示了当前数据库的全局名为ORCL,创建时间为10- 10 月- 010 且处于归档模式
正是由于控制文件的重要性,就要求控制文件不能只有一个,通常生产数据库中的控制文件要多于3 个,并且存放在不同的磁盘上。Oracle 数据库会同时维护多个完全相同的控制文件,这也称为多重控制文件。在不同磁盘上存储多重控制文件可以避免控制文件的单点失效问题。如果一个磁盘的控制文件失效,Oracle 会自动使用参数文件中记录的其他控制文件启动数据库。
在控制文件的维护中,Oracle 会建议用户遵循一个原则,即使用多重控制文件,并将控制文件的副本存储在不同的磁盘上,监控备份工作。下面将依次讲解如何使用多重控制文件并将文件副本存储在不同的磁盘上、如何备份控制文件,以及如何恢复控制文件。
在Oralce 数据库中,控制文件的默认存储目录和数据库文件,重做日志文件等存放在同一个目录下,以Oralce 11g 为例,该目录为:$ ORACLE_ BASE\ oradata\ ORACLE_ SID.
查看当前数据库上的控制文件分布
SQL> col name for a50;
SQL> select status, name from v$controlfile;
D:\ORACLE\ORADATA\ORCL\CONTROL01.CTL
D:\ORACLE\FLASH_RECOVERY_AREA\ORCL\CONTROL02.CTL
把这么重要的控制文件放在同一个磁盘的同一个目录下显然是不安全的,我们应该遵循Oracle 的忠告,使用多重控制文件并存储在不同的磁盘上。
数据库在启动时首先要读取参数文件,而参数文件有传统的PFILE(init. ora)文件和SPFILE 文件,针对采用不同的数据库启动初始化参数文件实现控制文件的分布式存储的方式略有不同。下面依次演示。
1、使用PFILE(init. ora)文件时移动控制文件
PFILE 文件是一个可识别的正文文件,我们可以对存储在PFILE 中的参数直接更改,这就方便了使用PFILE 实现移动控制文件的存储方式,其具体步骤如下:
①利用数据字典获得控制文件的名字
SQL> select value from v$ parameter where name =‘ control_ files‘;
此时输出的控制文件信息就是参数文件中保存的控制文件名及目录信息
②6关闭数据库
SQL> shutdown immediate 数据库已经关闭。已经卸载数据库。ORACLE 例程已经关闭。③修改参数文件PFILE 中参数control_ files 的值,即更改控制文件名而使得该文件存储在不同目录下并保存该文件。
④使用操作系统命令把①中的控制文件CONTROL2. CTL 和CONTROL2. CTL 分别复制到目录D:\ OraBackup\ disk1 和D:\ OraBackup\ disk2 下。之后需要删除掉步骤1 中默认目录下的CONTROL2. CTL 和CONTROL3. CTL 文件,以防止文件冗余。
⑤重启数据库。
SQL> startup
⑥验证控制文件的修改结果
SQL> col name for a40
SQL> SELECT * FROM v$ controlfile
此时,我们的修改成功,3 个控制文件存储在不同磁盘,3 个不同磁盘上的控制文件由Oracle 数据库服务器自动维护,一旦发生诸如增删数据文件或更改重做日志名等事件,Oracle 数据库服务器会同时更改这3 个控制文件中的信息。
2、使用SPFILE 文件时移动控制文件
因为SPFILE 是二进制文件,所以无法通过修改PFILE 的方式修改控制文件名,Oralce 提供了ALTER SYSTEM 指令允许修改SPFILE 中的参数。此时实现控制文件分布式存储的步骤如下。
①获取控制文件名
SQL> select * from v$ controlfile;
②使用alter system set 指令修改SPFILE 中的控制文件名
SQL> alter system set control_ files = ‘F:\ APP\ ADMINISTRATOR\ ORADATA\ ORCL\ CONTROL01. CTL ‘, ‘D:\ ORABACKUP\ DISK3\ CONTROL02. CTL‘, ‘D:\ ORABACKUP\ DISK4\ CONTROL03. CTL‘ SCOPE = SPFILE;
③关闭数据库
SQL> shutdown immediate
④将控制文件CONTROL02. CTL 和CONTROL03. CTL 复制到更改的目录下。即将CONTROL02. CTL 复制到目录D:\ ORABACKUP\ DISK3 下,将CONTROL03. CTL 复制到目录D:\ ORABACKUP\ DISK4 下。
⑤重启数据库
SQL> conn /as sysdba
SQL> startup
验证是否使用PFILE 启动数据库
SQL> show parameter spfile;
显然,现在VALUE 的值不为空,说明此时使用SPFILE 文件启动数据库。
⑥验证控制文件的修改结果
SQL> select status, name from v$ controlfile;
从上述输出看出,我们已经将名为CONTROL02 和CONTROL03 的控制文件分布到了D:\ ORABACKUP\ DISK3 和D:\ ORABACKUP\ DISK4 目录下。
Oracle 默认建立3 个控制文件,使用7. 4. 2 节中介绍的方法可以移动控制文件,将控制文件存储在不同的磁盘空间,以防止控制文件的单点失效。
在生产数据库中往往至少需要3 个控制文件,需要5 个控制文件的处理步骤,以数据库启动时采用PFILE 参数文件为例。
①查看控制文件的名字
②关闭数据库
③使用操作系统命令将①中的一个控制文件复制到一个目录下并修改控制文件的名字,如复制到目录D:\ OraBackup\ disk5 下,控制文件名修改为CONTROL05. CTL
④修改参数文件中参数control_ files 的值,添加一个控制文件名,如D:\ OraBackup\ disk5\ CONTROL05. CTL
⑤重新启动数据库。
由于控制文件在数据库启动过程中的重要性,所以最好备份控制文件,这样在发生控制文件损坏时,可使用备份的文件来恢复控制文件,保证数据库的正常启动和运行。
使用ALTER DATABASE BACKUP CONTROL 备份控制文件
SQL> alter database backup controlfile to ‘d:\ OraBackup\ disk5\ backup_ controlfile_ 010_ 06_ 14. ora‘;
注意目录D:\ OraBackup\ disk5 必须是存在的,Oracle 会自动在该目录下创建一个备份文件backup_ controlfile_ 010_ 06_ 14. ora。由于Oracle 数据库服务器不断地更改控制文件中的信息,所以备份的控制文件不是最新的,在恢复数据库时最好不要使用备份的控制文件,这样会造成数据丢失。
Oracle 也提供了一种方式用于备份控制文件,即将控制文件备份到追踪文件中,使用该文件就可以恢复控制文件。其备份方法首先要设置参数sql_ trace 为true
SQL> alter session set sql_ trace = true;
注意在使用该方式备份控制文件时,必须把参数sql_ trace 的值设置为true,Oracle 默认该参数值为false。再使用如下指令将控制文件备份的追踪文件中。
SQL> alter database backup controlfile to trace;
Oracle 提供了一个参数user_ dump_ dest,可以查看跟踪文件的存储目录
查询参数user_ dump_ dest 指定的目录
SQL> show parameter user_ dump_ dest;
从输出看出,跟踪文件的存储目录为F:\ app\ administrator\ diag\ rdbms\ orcl\ orcl\ trace
在数据库中如果有一个或多个控制文件丢失或出错,我们可以根据不同的情况进行处理。
1、部分控制文件损坏的情况
如果数据库正在运行,我们可以先关闭数据库,再将完好的控制文件复制到已经丢失或出错的控制文件的位置,但是要更改文件名字为该丢失或出错的控制文件的名字。如果存储丢失的控制文件的目录也被破坏,则需要重新建立一个新的目录用于存放新的控制文件,并为该控制文件命名。此时需要修改数据库初始化参数文件中控制文件的位置信息。
2、控制文件全部丢失或损坏
此时使用备份的控制文件重建控制文件。先关闭数据库,再将备份的控制文件复制到先前控制文件的所在位置上,并更改备份控制文件名为先前控制文件的文件名。接下来打开数据库到MOUNT 状态,
SQL> startup mount
然后打开数据库,
ALTER DATABASE OPEN USING BACKUP CONTROLFILE; 注意此时由于使用备份的控制文件所以会有数据丢失的情况,因为从该备份文件被备份时刻起到控制文件发生故障时间段内发生的数据变化无法恢复。
重做日志是Oracle 数据库中很重要的一部分内容。在数据库恢复时,需要掌握重做日志的工作原理,学会如何配置和维护重做日志
数据恢复。
在数据库运行过程中,用户更改的数据会暂时存放在数据库高速缓冲区中,而为了提高写数据库的速度,不是一旦有数据变化,就把变化的数据写到数据文件中,频繁的读写磁盘文件使得数据库系统效率降低,所以,要等到数据库高速缓冲区中的数据达到一定的量或者满足一定条件时,DBWR 进程才会将变化了的数据写到数据文件中。
这种情况下,如果在DBWR 把变化了的更改写到数据文件之前发生了宕机,那么数据库高速缓冲区中的数据就全部丢失,如果在数据库重新启动后无法恢复这部分用户更改的数据,显然是不合适的。
重做日志就是把用户变化了的数据首先保存起来,其中LGWR 进程负责把用户更改的数据优先写到重做日志文件中。这样在数据库重新启动时,数据库系统会从重做日志文件中读取这些变化了的数据,将用户更改的数据提交到数据库中,写入数据文件。
为了提高磁盘效率,并为了防止重做日志文件的损坏,Oracle 引入了一种重做日志结构,重做日志文件结构由3 个重做日志组组成,每个重做日志组中有两个重做日志成员(重做日志文件),当然可以有更多的重做日志组,每个组中也可以有更多的重做日志成员。
数据库系统会先使用重做日志组1,该组写满后,就切换到重做日志组2,再写满后,继续切换到重做日志组3,然后循环使用重做日志组1,Oracle 以这样循环的方式使用重做日志组。该结构直观地说明重做日志文件的组成,Oracle 规定每个数据库实例至少有两个重做日志组,每个重做日志组至少有一个重做日志文件。当重做日志组中有多个日志成员时,每个重做日志成员的内容相同,Oracle 会同步同一个重做日志组中的每个成员。在工作过程中,Oracle 循环地使用重做日志组,当一个重做日志组写满时,就自动进行日志切换,切换到它可以找到的其他重做日志组,并为该日志组设置一个日志序列号。在必要的条件下也可以实现强制日志切换。如果没有启动归档日志,当一个循环结束,再次使用先前的重做日志组时,会以覆盖的方式向该组的重做日志文件中写数据。在非归档模式下,在重新使用新的联机重做日志前,DBWR 进程需要将所有的数据更改写到数据文件中,这有时也称为DBWR 归档。所以,对于生产数据库要求工作在归档模式下。
如果数据库处于归档模式下,当前正在使用的重做日志写满后,Oracle 会关闭当前的日志文件,ARCH 进程把旧的重做日志文件中的数据移动到归档重做日志文件中。归档完成后,寻找下一个可用重做日志组,找到该组中可用的日志文件,打开该文件并实现写操作。归档进程并不是一直存在。注意如果数据库处于归档模式,在归档进程ARCH 把联机重做日志移动到归档日志前,Oracle 无法使用一个已经关闭的重做日志。即如果ARCH 没有完成,就没有已经归档的联机重做日志可以用于切换,只有ARCH 释放了联机重做日志后,数据库才可以继续工作。
数据字典视图v$ log 记录了当前数据库的日志组号、日志序列号、每个日志文件的大小、每个日志组的成员数量,以及日志组的当前状态。
使用v$ log 查看重做日志信息
SQL> conn /as sysdba
SQL> select group#, sequence#, bytes, members, archived, status 2 from v$ log;
输出说明,当前有3 个日志组,与每个日志文件对应的日志序列号,该序列号是全局唯一的,同一个日志组中的日志序列号相同,用户数据库恢复时使用。每个日志组的成员数量及每个日志组的当前状态。重做日志组1 为当前正在使用的重做日志组,该日志组中有最大日志序列号,该日志文件还没有归档。
数据字典视图v$ logfile 记录了当前日志组号、该日志组的状态、类型和日志组成员信息,使用数据字典视图v$ logfile 查看重做日志组信息
SQL> conn /as sysdba
SQL> col member for a50
SQL> select group#, status, type, member 2 from v$ logfile;
在解释输出结果前,先介绍一下STATUS 参数的含义:
● STALE:说明该文件内容是不完整的。
● 空白:说明该日志组正在使用。
● INVALID:表示该文件不能被访问。
● DELETED:表示该文件已经不再使用。
从输出,我们可以知道,该数据库系统有3 个重做日志组,每个日志组有一个重做日志成员,且都为联机(ONLILNE)重做日志文件。其实DBA 如果看到这样的情况,应该知道需要增加重做日志成员,并且把每个日志组的重做日志成员分布在不同磁盘上。
查看当前的数据库是否处于归档模式
SQL> conn /as sysdba
SQL> archive log list;
输出说明,该数据库不处于日志归档模式,自动存档禁用
如何在Oracle 11g 中设置数据库为归档模式。首先要关闭数据库,再启动数据库到mount 状态:
关闭数据库并启动数据库到mount 状态
SQL> shutdown immediate
SQL> startup nomount;
SQL> alter database mount;
SQL> alter database archivelog;
此时虽然数据库处于归档模式,而且是自动归档。在设置了数据库为归档模式,而且为自动归档后,
验证数据是否处于归档模式
SQL> conn /as sysdba
SQL> archive log list;
上例说明数据库日志模式已经处于“存档模式”,存档重点为参数db_ recovery_ file_ dest 指定的目录,我们可以使用如下查询知道该参数指定的文件目录
查看参数db_ recovery_ file_ dest 的值
SQL> show parameter db_ recovery_ file_ dest;
从参数db_ recovery_ file_ dest 的值为可以知道归档文件的存储目录,并且参数db_ recovery_ file_ dest_ size 指出该目录存储文件的大小为2G。
Oracle 要求最少两个重做日志组,每个日志组至少一个日志成员,而在生产数据库中至少需要3 个重做日志组,而每个重做日志组需要多于3 个重做日志成员,这些日志成员最好部署在不同磁盘的不同目录下,由于重做日志文件在数据库恢复中的重要性,分布式部署的目的就是为了防止磁盘损坏造成的重做日志失效。本节讲述如何添加重做日志组及其管理。
向当前数据库中添加一个新的日志组的语法格式为:
ALTER DATABASE [database_ name] ADD LOGFILE [GROUP number] filename SIZE n [,ADD LOGFILE [GROUP number] filename SIZE n……]
注意Filename 为日志组成员的文件目录和文件名称。参数GROUP number 可以不用,Oracle 会自动生成一个日志组号,该日志组号在原有日志组号的基础上加1。
添加一个重做日志组
SQL> ALTER DATABASE ADD LOGFILE GROUP 4 (‘d:\ temp\ redo04a. log‘, ‘d:\ temp\ redo04b. log‘) SIZE 11M;
向当前数据库添加一个重做日志组,日志组号为4,如果不选择GROUP 参数,则默认在原有重做日志组号的基础上自动增长,如原来最大的日志组号为2,则此时新建的默认组号为3 等,依次类推。在日志组4 中有两个日志成员,大小都为11MB。
验证添加日志组的结果
SQL> select * from v$ logfile;
输出结果说明,成功添加重做日志组,该日志组有两个日志成员,地址为D:\ TEMP\ REDO04A. LOG 和D:\ TEMP\ REDO04B. LOG,这两个重做日志成员都处于联机状态。
下面再添加一个重做日志组,此时不选择GROUP 参数,向该日志组中添加3 个日志成员,成员大小都为11MB
添加一个重做日志组并向该日志组中添加3 个日志成员
SQL> ALTER DATABASE ADD LOGFILE (‘d:\ disk6\ redo05a. log‘, ‘d:\ disk6\ redo05b. log‘, ‘d:\ disk6\ redo05c. log‘) SIZE 11 M;
验证执行结果
SQL> conn /as sysdba
SQL> select * from v$ logfile;
显然,我们新添加的重做日志组号为5,该日志组共有3 个重做日志文件
查询当前重做日志组的使用情况
SQL> select group#, sequence#, bytes, members, archived, status from v$ log;
重做日志组4 和重做日志组5 是新建的重做日志组,二者的状态都为UNSUED 未使用,重做日志组4 有2 个日志成员,每个成员的大小为114 115 760 个字节,重做日志组5 有3 个日志成员,每个成员的大小为114 115 760 个字节。因为两个重做日志组还没有使用所以Oracle 没有分配日志序列号。
删除重做日志组的语法格式为:
ALTER DATABASE [database_ name] DROP LOGFILE {GROUP n|(‘filename’[,’filename’]…)} [{GROUP n|(‘filename’[,’filename’]…)}]…
在上述语法中符号“|”表示“或”的关系,而符号[] 表示可选。
删除重做日志组
SQL> alter database drop logfile group 4, group 5;
注意当前的重做日志组和处于ACTIVE 状态的重做日志组都无法删除,如果要删除当前在用的日志组,必须先进行日志切换。在删除一个日志组时可以使用GROUP 参数直接删除该日志组,也可以指定删除该日志组中的所有重做日志文件来达到删除日志组的效果
验证日志组5 的成员是否删除
SQL> conn /as sysdba
SQL> select * from v$ logfile;
验证日志组5 是否删除
SQL> select group#, sequence#, bytes, members, archived, status 2 from v$ log;
在每个重做日志组中至少要有一个日志成员,但是为了防止单点失效的发生,最好多设置几个重做日志成员,并存储在不同的磁盘空间中。这样的冗余设置可以极大地提高重做日志文件的可靠性。
向一个重做日志组中添加日志成员的语法格式:
ALTER DATABASE [databasename] ADD LOGFILE MEMBER [‘filename’[REUSE] [,’filename’[ REUSE]]……TO {GROUP n |(‘filename’[,’filename’]……)} ]……
如何向重做日志组中添加重做日志成员,此时无论是否是当前正在使用的重做日志组,都可以添加重做日志成员
向重做日志1、2、3 添加一个重做日志成员
SQL> alter database add logfile member ‘d:\ temp\ redo01a. log‘ to group 1, ‘d:\ temp\ redo02a. log‘ to group 2, ‘d:\ temp\ redo03a. log‘ to group 3;
验证日志组的成员数结果
SQL> select group#, sequence#, bytes, members, archived, status from v$ log;
在上述输出中,重做日志组1、2 和3 的MEMBERS 都为2,说明这些重做日志组有2 个重做日志成员。
验证添加的重做日志组以及对应成员信息
SQL> select * from v$ logfile order by group#;
我们使用了order by 子句对输出进行排序,这样就方便查看每一个重做日志组的成员。在上述输出中,重做日志组1、2 和3 都新增了一个重做日志成员。注意如果添加的日志成员文件已经存在,则需要使用REUSE 参数,并且日志成员要用全目录格式,不要使用相对目录的形式,否则,Oracle 数据库服务器会在默认路径下建立该重做日志文件。
出现重做日志文件受损的情况就要及时修复,也就是删除掉该文件,然后重建。
删除重做日志文件的语法格式为:
ALTER DATABASE [database_ name] DROP LOGFILE MEMBER ‘filename’[,’filename’]……
删除重做日志组中的一个日志成员
SQL> alter database drop logfile member ‘D:\ TEMP\ REDO04A. LOG‘;
查询重做日志组4 的日志成员信息
SQL> select * from v$ logfile 3 where group# = 4;
输出结果说明,已经成功删除了重做日志组4 的一个成员D:\ TEMP\ REDO04A. LOG。但是操作系统中和该成员对应的文件还没有被删除,需要手动删除。在删除日志成员时,并不是所有的重做日志成员都可以删除,Oracle 有一些限制条件。
执行删除操作的一些限制如下:
● 如果要删除的日志成员是重做日志组中最后一个有效的成员,则不能删除,如该日志组中只有一个日志成员。
● 如果该日志组当前正在使用,在日志切换前不能删该组中的成员。
● 如果数据库正运行在ARCHIVELOG 模式,并且要删除的日志成员所属的日志组没有被归档,该组中的日志成员不能被删除。
当一组重做日志组写满时,或用户发出alter database switch logfile 时,就会触发日志切换,此时Oracle 寻找下一个可用的重做日志组,如果数据库处于归档模式,则在将当前写满的日志组归档完成前不会使用新的重做日志组。
检查点事件是Oracle 为了减少数据库实例恢复时间而设置的一个事件,当该事件发生时,LGWR 进程将重做日志缓冲区中的数据写入重做日志文件中,而同时通知DBWR 进程将数据库高速缓存中的已经提交的数据写入数据文件,所以检查点事件越频繁则用于数据库恢复的重做数据就越少。此时,检验点事件也会修改数据文件头信息和控制文件信息以记录检查点的SCN。
可以使用如下指令强制启动检查点事件。alter database checkpoint 我们给出一个例子,先更改强制日志切换,为了加速日志切换时间,使得当前的重做日志文件处于INACTIVE 状态,再强制产生检查点事件。
强制日志切换并强制产生检查点事件
SQL> conn /as sysdba
SQL> alter system switch logfile;
SQL> alter system checkpoint;
注意检查点事件不是检验点进程触发的,如果不是强制产生检验点事件,则检验点事件由DBWR 数据库写进程触发。
归档重做日志就是联机重做日志的脱机备份,在数据库服务器处于归档模式时,发生日志切换时,数据库的归档进程ARCH 把重做日志文件中的数据移动到归档重做日志中。归档进程在数据库服务器运行期间并不是总是存在的,而是当满足一定条件(如一组重做日志文件写满)时启动归档进程。一旦归档完毕,归档进程自动关闭。归档日志文件存储在参数文件SPFILE 或init. ora 文件中参数指定的位置,在inti. ora 文件中该参数为log_ archive_ dest_ n。Oracle 只能把重做日志中的数据移动到磁盘上,而不能移动到磁带等存储介质上。
标签:组合 进程 角色权限 poi 环境 pass 方法 ide ase
原文地址:https://www.cnblogs.com/zhangguosheng1121/p/11991964.html